
:quality(80)/p7i.vogel.de/wcms/49/c6/49c665060846beb129ae679a2918c61a/0132163773v1.jpeg "Wer trägt die Verantwortung? Echte Datensouveränität bei KI und Cloud bedeutet, die Kontrolle über sensible Daten sicher in der eigenen Hand zu behalten. (Bild: © Lustre - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/6b/7a/6b7a7ae072bb7ab964cde4d302755ceb/0124814981v1.jpeg "Der European Blueprint soll bis Ende 2026 festlegen, welche europäischen Organisationen Zugang zu fortgeschrittenen KI-Modellen erhalten. Verbindliche Pflichten für Anbieter außerhalb der EU entstehen daraus nicht. (Bild: Vergiliy - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/26/81/2681098961a1b8010bbf241f3e914891/0132345254v1.jpeg "Räumlich-zeitliche Identifikatoren sollen fragmentierte Datenbestände systemübergreifend nutzbar machen. Nach Angaben von The Green Bridge ist die Grundlage für KI-Anwendungen und Automatisierung. (Bild: Unsplash-Steve A Johnson)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/d9/db/d9dbfbca0f9ff41469a40d883f8e5cb5/0132438388v1.jpeg "Mit Version 9.5 rückt Denodo die semantische Schicht ins Zentrum der Plattform und positioniert sich im Wettbewerb um die Kontextversorgung von KI-Agenten. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b8/76/b8761191f739895263a4bdbfcaf9c5b2/0132429694v1.jpeg "Mit dem Wechsel von assistierenden zu ausführenden Agenten verlagert sich der Kontrollbedarf im Produktdatenmanagement. Entscheidend wird die Nachvollziehbarkeit einzelner Attributänderungen. (Bild: Akeneo)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")
:quality(80)/p7i.vogel.de/wcms/78/9a/789af78a62e28f5e8cc995570d48b822/0130655525v1.jpeg "SupplyX wollte sein Transportmanagement-System ersetzen und fand den Engpass in den Daten. Ein Praxisbericht über die Datenbasis produktiver KI. (Source: © MAGNIFIER - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/9f/fe/9ffe3d484cf6fdc7ea137128b15f60a9/0131577982v1.jpeg "Im Einsatz für den Artenschutz: Ein WWF-Ranger durchstreift den Regenwald. Das geplante Wildlife Protection Operations Center soll solche Einsätze KI- und datenbasiert optimieren. (Bild: Emmanuel Rondeau / WW_US)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/e9/34/e9342418bd8081921fdd2fc2fc4be51b/0132359705v2.jpeg "Einsatz auf dem Acker: Wie sich humanoide Systeme mit schweren landwirtschaftlichen Maschinen vernetzen lassen, wird in Ilmenau erprobt. (Bild: Fraunhofer IOSB)")
:quality(80)/p7i.vogel.de/wcms/57/b8/57b8da3ba179d80f10073e7541f8b68f/0132491632v1.jpeg "Die Brücke vom Trainings-Cluster über die Simulation bis zum Roboter im Feld hat Lücken: Physical AI scheitert seltener am Modell als am Workflow. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f9/43/f943ca681620e9eb521fea039168a2fe/0132555049v1.jpeg "Die Konferenz T3 – Transform The Tomorrow diskutiert am 1. und 2. Dezember 2026 Strategien, wie Unternehmen sich zukunftssicher aufstellen können. (Bild: © Vogel Corporate Solutions / AdobeStock 1280236166, Oksana)")
:quality(80)/p7i.vogel.de/wcms/95/e5/95e50766b5de0f4b7ca74d1db2524bf2/0132321286v2.jpeg "Humanoide Roboter: Roboter, die vor wenigen Jahren noch eine Vision waren, sind heute dank KI, maschinellem Lernen und Echtzeit-Datenverarbeitung Realität. (Bild: Pete Linforth)")
:quality(80)/p7i.vogel.de/wcms/81/6d/816dfab525864f08b3569676daffb31f/0132240748v2.jpeg "Workflow des Ablaufs einer GitLost-Attacke. (Bild: Noma Security)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/ef/f6/eff64658474870dee6038d07b1344a81/0132429745v2.jpeg "KI: Die große Black-Box in der Fabrik (Bild: Lucid Origin / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/2d/e1/2de1bc70ea005474921a43b67a106036/0132125007v1.jpeg "Gemma 4 ermöglicht einen sehr effektiven KI-Betrieb, der komplett offline und lokal stattfindet. (Bild: Google)")
:quality(80)/p7i.vogel.de/wcms/70/85/70856801e79d66e890c31e787d297b45/0132522652v1.jpeg "Die kostenfreie Online-Konferenz „DATABRAIN Digital Conference“ am 10. November richtet sich an Fach- und Führungskräfte, die den Einsatz von Künstlicher Inteligenz in ihren Unternehmen strategisch vorbereiten und erfolgreich in die Praxis überführen möchten. (Bild: Vogel IT-Akademie)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Realtime Analytics So funktioniert Datenauswertung in Echtzeit
Prozesse, Endgeräte, Sensoren und Maschinen liefern laufend Logfiles, Sensor- und Betriebsdaten, Transaktionsdaten, die sich korrelieren und auswerten lassen – in Echtzeit. Doch „Echtzeit“ muss nicht unbedingt „ohne Verzug“ bedeuten, sondern lediglich in ausreichender Schnelligkeit für den jeweiligen IT-Benutzer, also vielmehr „rechtzeitig“. Daher befasst sich Realtime Analytics nicht nur mit Streaming-Daten, sondern auch mit viel „langsameren“ Datenlieferungen.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
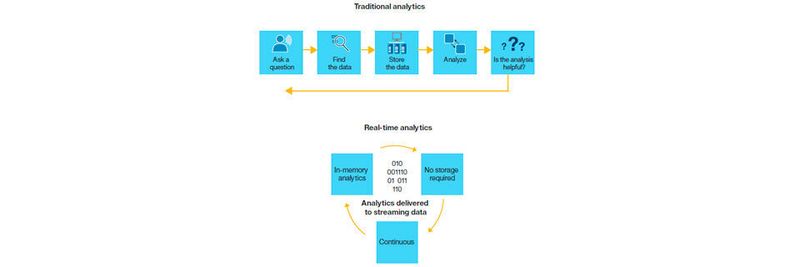
Schnelle Datenlieferungen in möglichst kurzer Zeit werden bei vielen Unternehmen immer begehrter, sei es in Social Media, an der Börse, in IoT oder in der Datensicherheit. Wenn dabei von „Echtzeit“ bzw. „Realtime“ die Rede ist, so wird etwas verwechselt: „Echtzeit“ bedeutet in der Informationstechnik nicht „sofort“, sondern „ausreichend schnell“, also rechtzeitig. Für jedes System gilt daher eine andere Echtzeit. Das eröffnet eine breite Vielfalt von Anwendungsmöglichkeiten.
:quality(80)/images.vogel.de/vogelonline/bdb/1265200/1265275/original.jpg "(IBM)")
:quality(80)/images.vogel.de/vogelonline/bdb/1265200/1265276/original.jpg "(IBM)")
:quality(80)/images.vogel.de/vogelonline/bdb/1265200/1265277/original.jpg "(IBM)")
:quality(80)/images.vogel.de/vogelonline/bdb/1265200/1265278/original.jpg "(SAS)")
„In vielen klassischen Data-Warehouse-Szenarien werden auch in 2017 die Daten immer noch im Wochenrhythmus geladen“, weiß Dominik Claßen zu berichten, Director of Sales Engineering EMEA & APAC bei Hitachi Vantara. „Für diese Anwender fühlt sich die Umstellung auf tägliche Einspeisung nicht selten bereits wie Echtzeit an.“ Mit Fast-Echtzeit, also mit Latenzen von zehn bis 15 Sekunden, könnten demnach auch bereits viele Analyse-Szenarien abgedeckt werden. „Tatsächliche Echtzeit-Anwendungsfälle, in denen die Daten jede Sekunde aktualisiert werden“, seien indes spezialisierten Analyse-Tools vorbehalten. In erster Linie kommen dafür Streaming-Engines infrage, insbesondere dann, wenn IoT- und Maschinendaten zu verarbeiten sind.
Anwender
Bei Realtime Analytics geht es dennoch in vielen Fällen um sehr große Datenmengen, die in kürzester Zeit aktualisiert werden müssen. Pentahos Datenintegrations-Tool PDI (Pentaho Data Integration) wird zum Beispiel eingesetzt, um XML/JSON-Streams abzugreifen, die Apache Kafka liefert, und die Daten mit Apache Spark abzufragen und weiterzuverarbeiten.
Ein interessanter Anwendungsfall ist in diesem Bereich die finnische Lotterie Veikkaus. Das staatliche Unternehmen für Wetten und Lotterien nutzt unter anderem Pentaho PDI, um täglich mehr als zwei Millionen Kafka-XML/JSON-Messages aus dem Lotterie-System zu laden. Dabei werden mehr als 200 Messages pro Sekunde von PDI verarbeitet und via Cloudera Flume in Hadoop sowie HPE Vertica gespeichert.
Die Datenströme werden in Near Realtime (zehn bis 15 Sekunden) ins Frontend der Anwendung geladen, was es dem Marketing Team ermöglicht, den rund eine Million registrierten Nutzern beispielsweise Erinnerungen oder personalisierte Angebote zwei Tage vor der Lotterie zu senden und sie zur Teilnahme aufzufordern. Die hundertprozentige Korrektheit der Daten, die das Pentaho-System nun gewährleistet, ermöglicht nicht nur genaue Finanzanalysen – die Erlöse kommen Bildung, Sport und Kultur zugute – sondern auch vollständige Compliance.
Einsatzszenarien
Es gibt für die Verarbeitung von unstrukturierten und semistrukturierten Daten wie etwa Logfiles und Datenströmen zahlreiche Einsatzfelder, darunter Kapazitätsplanung für Applikationen und Netzwerke, Datensicherheit, Betrugserkennung, Kundenservice, Gesundheit, Smart Grid und IoT, um nur ein paar zu nennen. Je verbreiteter IoT-Anwendungen werden, desto mehr sind auch Versorger betroffen, so etwa Stromerzeuger, die ein Netz von intelligenten Stromzählern verwalten.
Immer mehr Unternehmen werden also Realtime-Analytics nicht nur als reizvolle Option betrachten, sondern zunehmend als einen kritischen Erfolgsfaktor. Ein Börsenmakler, der die neuesten Aktienkurszahlen im Mikrosekundentakt in sein IT-System bekommt, steht vor der Frage, wo und vor allem wann er am gewinnbringendsten investiert. Die Analyse-Software muss ihm die Antwort geben, mithilfe von Predictive oder sogar Prescriptive Analytics.
Streaming-Technologien
Der große Unterschied zu Business Intelligence Tools und Big Data Analytics sind die oft enormen Datenmengen und ihre hohe Aktualisierungsgeschwindigkeit aus unterschiedlichsten Datenquellen. Was für den Endanwender zählt, ist die möglichst zeitnahe, aber „rechtzeitige“ Bereitstellung der Analyse-Resultate. Das bedingt einen grundlegenden Unterschied in der IT-Architektur.
Eine hoch entwickelte Form der traditionellen Entscheidungsunterstützung ist Complex Event Processing (CEP). Diese erprobte Disziplin basiert auf Boole'scher Logik und strukturierten Datentypen. Daher kann sie nur eine begrenzte Anzahl von Geschäftsereignissen pro Sekunde verarbeiten. Big Data besteht jedoch zu über 90 Prozent aus unstrukturierten Daten, wie sie etwa Mobilgeräte und Soziale Netzwerke erzeugen. CEP 2.0 müsste also folgende Bedingungen erfüllen:
- Parallele Datenströme verarbeiten,
- Daten In-Memory analysieren, um für Hochgeschwindigkeitsanwendungen (Börse, Betrugserkennung, Datensicherheit) geeignet zu sein,
- Linear je nach Speicheranforderungen skalieren,
- die Datenverarbeitung näher zu den Datenquellen platzieren und
- mehrere parallele Prozesse aufgrund eines einzigen Auslösers (Ereignis) oder einer Nachricht anstoßen und im System verarbeiten.
Während Big Data Analytics durchaus mit relativ langsamen Systemen wie Hadoop oder auch Spark zufrieden sein könnte, sind Realtime-Systeme, die etwa auf Streaming basieren, dazu gezwungen, diesen Schritt zu umgehen: Hadoop? Das ist etwas für historische Analysen.
Wenn ein Unternehmen etwa aufgrund seiner Data-Lake-Architektur noch langsame MapReduce-ähnliche Stapelverarbeitungsprozesse in Hadoop nutzen muss, kann es dennoch gleichzeitig Apache Storm für das Verarbeiten von Datenströmen heranziehen – gleichzeitig oder parallel.
So unterstützt etwa die neueste Version der Speicher-Engine ColumnStore der SQL-Datenbank MariaDB die massiv-parallele Verarbeitung sowohl historischer Daten als auch von Datenströmen, sogenanntes Streaming, in einer einzigen Systemarchitektur. Das erhöht die Leistung für die Bereitstellung und Verarbeitung von Daten aller Art erheblich und ermöglicht innovative Geschäftsmodelle, besonders im IoT-Markt.
Open Source Tools
Wie schon Namen wie Hadoop, Spark und Storm signalisieren, existiert bereits eine enorme Vielfalt von Tools für die Verarbeitung von Datenströmen in Formaten wie XML/JSON oder MQTT, aber auch Publish/Subscribe-Verfahren sind häufig. Apache Spark etwa bietet seit dem Start auch Streaming-Fähigkeiten an, während Apache Storm anders arbeitet, sich aber gut mit Apache Kafka oder Apache Flink kombinieren lässt.
Jedes Tool hat seine Stärken und Beschränkungen, doch unterm Strich zählt die Leistung bei der Datenlieferung und den Analyseresultaten. Die Storm-Kuratoren nennen eine Leistung des Tools bei mittlerweile eine Million Tupeln pro Sekunde pro Node (der Einsatz erfolgt üblicherweise nur auf Clustern). Mit „Tupeln“ sind simple Datenlisten gemeint, die sich rasch verwerten und transformieren lassen, etwa für die SQL-Abfrage. Wie sich die Performance und Einsatzvielfalt steigern lässt, sollen die folgenden Beispiele aufzeigen.
Streaming-Services
Auch aus der Public Cloud können System- und App-Entwickler entsprechende Services beziehen. Mit AWS Kinesis lassen sich IoT-Telemetriedaten, Anwendungsprotokolle oder Website-Clickstreams in Echtzeit erfassen, verarbeiten und auswerten, etwa in einem Data Warehouse oder Data Lake. Der Service besteht aus den Bausteinen Firehose (Transport), Streams (Entwicklung) und Analytics.
Google Cloud Dataflow arbeitet wie Spark mit einer Architektur, die sowohl Stapelverarbeitung als auch Streaming unterstützt. Durch die Integration mit anderen Google-Service wie BigTable, Datastore, BigQuery eignet sich Dataflow für Massendaten. Mithilfe der Apache Beam SDKs, die für Java und Python bereitstehen, sowie mit APIs zu Drittanbietern kann ein Entwickler diejenigen Erweiterungen erstellen, die er für seinen jeweiligen Zweck benötigt.
Microsoft Azure Stream Analytics offeriert einen ähnlichen Leistungsumfang wie Google und AWS, setzt aber ganz auf seine eigene Cloud-Infrastruktur. Das Event Hub soll Millionen von Ereignissen in kürzester Zeit verarbeiten können. Das Protokoll dafür ist das neue Advanced Message Queuing Protocol (AMQP). Interessant ist auch die Unterstützung für Apache Nifi zwecks Automation des Datenflusses und des beliebten, ebenfalls quelloffenen Elastic- bzw. ELK-Stack aus ElasticSearch, Kibana und Logstash.
Die Abfragen erfolgen auf Azure wie beim Wettbewerb mit SQL, doch die Konnektoren werden bereits frei Haus bereitgestellt. Mit Machine-Learning-Algorithmen lassen sich Predictive-Scoring-Schritte auf Streaming-Daten realisieren. Microsoft hat klar erkannt, dass künftig die größten Datenmengen aus dem Internet der Dinge kommen werden. Daher ist Stream Analytics bereits mit dem Azure IoT Hub und IoT Analytics integriert, und alle Resultate lassen sich mit Dashboards überwachen, die man mit Microsoft PowerBI erstellt. Der gesamte Service ist bereits in Deutschland nutzbar.
Kaufen statt bauen – alles aus einer Hand
Für den Interessenten stellt sich die Frage, ob er genügend Zeit, Geld und Know-how besitzt, um alle diese Bausteine fachgerecht, ausgetestet und rechtzeitig zusammenzustellen – oder ob er nicht gleich zu einem zwar proprietären, aber dafür einheitlichen und ausgereiften Produkt greift. Als zwei Vertreter dieser Gattung seien exemplarisch IBM InfoSphere Streams und SAS Event Stream Processing (ESP) vorgestellt.
SAS ESP ist eine einbettbare Ereignisverarbeitungs-Engine, die sich, ähnlich einem Motor in einem Fahrzeug, in geeignete Applikationen einbauen und programmieren lässt. Dennoch verfügt sie über eine visuelle Benutzeroberfläche, über die sich ihre Eigenschaften konfigurieren lassen. Dazu gehören etwa die zahlreichen Datenquellen von strukturierten und unstrukturierten Daten, zu denen SAS Adapter und Konnektoren bereitstellt. Zu den Quellsystemen gehören u. a. Hadoop, HDFS und YARN, relationale Datenbanken, XML/JSON-Quellen, Message-Queueing-Tools (RabbitMQ), ODBC-Quellen und Publish/Subscribe-Quellen.
Entscheidend für den Mehrwert einer solchen Engine ist indes die Leistungsfähigkeit und vielfältige Nutzbarkeit dieses Datenmotors. Laut SAS sammelt ESP Millionen von Events pro Sekunde aus operativen Transaktionen, Sensoren, Endgeräten, Maschinen, Übertragungen usw. Die Übertragung und Verarbeitung erfolgt parallelisiert und in Process-Threads in einem In-Memory-Grid in Millisekunden oder schneller, sodass die Latenz minimal ist. Das Grid hat den Vorteil, linear skalierbar zu sein. Werden die Datenmengen zu groß, tritt ein Cache in Aktion, um sie zwischenzuspeichern. Die Endspeicherung erfolgt, sofern nötig, in indizierten In-Memory-Stores.
Noch während sich die Daten im Fluss befinden, werden sie mit Operatoren, Funktionen, Routinen und Advanced Analytics (Modellen usw.) normalisiert, bearbeitet, transformiert (Update, Delete und Insert) und verwertet. Denn schließlich interessiert den Nutzer nur das Besondere und das Ergebnis. Die Datenqualität wird bereits während des Streamings gesichert, ESP wendet vorab konfigurierte analytische Ausdrücke und Musterabgleichsalgorithmen auf die Daten an. Diese Musterabgleichsfunktionen erlauben es, sequenzielle oder temporale Ereignisse (etwa in Zeitreihen) zu definieren und Anomalien durch KPIs frühzeitig zu erkennen. Visualisierung, Warnung und Benachrichtigung gehören zur Grundausstattung der Konsole, um so Entscheidungen und Aktionen anzustoßen bzw. auszulösen, etwa im Fall einer sich anbahnenden Krise oder Katastrophe.
IBM Streams
IBM Streams verfährt auf technischer Ebene ähnlich wie SAS ESP, etwa um Datenmengen zu verkleinern, zu bereinigen, weiterzuleiten, zu indizieren und schließlich, falls unbedingt nötig, für spätere historische Analysen zu speichern. Ein Compiler konvertiert Streaming-Anwendungen, die in SPL-Code oder für eine Java-API geschrieben wurden, in Maschinensprache. Dieses Tools stellt auch fest, ob Operatoren einen Status haben (stateless, stateful) und kann aufgrund dieser Informationen festlegen, ob die Ausführung auf Mehrkernprozessoren multi-threaded erfolgen soll. Indem der Compiler Leistungsdaten aus vorherigen Ausführungen berücksichtigt, kann er entscheiden, welche Operatoren er in den Ablauf der Prozesse einfügen soll, um eine optimale Leistung zu erzielen.
Das führt zu der erfreulichen Konsequenz, dass mit der Inbetriebnahme weiterer Cores und Nodes die Performance hinsichtlich Parallelverarbeitung und Datendurchsatz steigt. In einem Vergleich mit Apache Storm übertrifft der IBM-Streams-Durchsatz den von Apache Storm um den Faktor 2,6 bis 12,3, während die Anwendung gleichzeitig 5,5 bis 14,2 Mal weniger CPU-Zyklen benötigt. Die Unterschiede hinsichtlich der Leistung können also je nach verwendetem System erheblich ausfallen.
Das IBM-Tool stellt lokal, in der Cloud oder in Hybrid-Modellen zahlreiche Konnektoren zur Verfügung, was dem Nutzer eine große Bandbreite an Möglichkeiten bietet. Die wirkliche Flexibilität beim betrieblichen Einsatz erlaubt indes die Fähigkeit des Systems, während des laufenden Betriebs weitere Input- oder Output-Streams sowie Nodes hinzuzufügen oder zu entfernen, ohne das System neu starten zu müssen. Laufende Streams lassen sich zudem in andere laufende Streaming-Jobs im- oder exportieren, sodass sich Daten und Situationen auf alternative Weisen analysieren lassen. Das könnte sich beispielsweise bei der Betrugserkennung oder der Aufdeckung eines Cyberangriffs als nützlich erweisen.
Mit Streams Studio steht eine integrierte Entwicklungsumgebung zur Verfügung, die es Entwicklern erlaubt, vorhandene Routinen in Java oder C++ in einer visuellen Umgebung in die Analyseprozesse zu integrieren. Beim Data Mining können Nutzer bestehende Scoring-Modelle auf die Streaming-Daten anwenden, statt auf historische Daten warten zu müssen. Die Streams-Applikation aktualisiert ihr Modell dann selbsttätig, um einer veränderten Situation gerecht zu werden. Geschäftliche Nutzer können MS Excel zu Hilfe nehmen, um ihre vertraute Tabellenkalkulation als Analyseumgebung zu nutzen.
Streams weist mit dem Scheduler und dem Job Manager zwei Optimierwerkzeuge auf, die der BI-Nutzer aus Data-Warehouse-Umgebungen kennt. Sie sorgen dafür, dass große Datenmengen keine Überlastung herbeiführen und dass Anwendungen mit geänderten Spezifikationen optimal weiterlaufen.
Webserver auf einer Internetseite werden außerhalb Streams ausgeführt und dienen etwa dazu, Datenströme in Echtzeit über eine TCP/IP-Verbindung zu visualisieren. Das kann eine Verkehrslage sein oder eine Wettersituation, aber auch die Anzeige von Anomalien wie etwa einem versuchten Kreditkartenbetrug oder einem drohenden Zusammenbruch des nationalen Stromnetzes. Man sieht: Echtzeit-Analysen von Datenströmen gewinnen täglich an Bedeutung.
(ID:44814769)
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")