
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/c8/8e/c88e128e6f3086c05cfffe26c73191bb/0131936826v1.jpeg "Wie lässt sich KI sicher, wirtschaftlich und skalierbar in Unternehmen einsetzen? Das war das zentrale Thema auf der Reply Xchange 2026 in der Münchener BMW Welt. (Bild: © Sandra Eckhardt & Sonja Herpic)")
:quality(80)/p7i.vogel.de/wcms/b8/d4/b8d434e1421217c59b03f7e269607aee/0131981690v1.jpeg "Schneller Code, fehlende Kontrolle: Laut GitLab fällt es vielen Teams schwer, KI-generierten Code im Lebenszyklus nachzuvollziehen (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Grundlagen Statistik & Algorithmen, Teil 5 Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
Der k-Means-Algorithmus ist ein Rechenverfahren, das sich für die Gruppierung von Objekten, die sogenannte Clusteranalyse, einsetzen lässt. Dank der effizienten Berechnung der Clusterzentren und dem geringen Speicherbedarf eignet sich der Algorithmus sehr gut für die Analyse großer Datenmengen, wie sie im Big-Data-Umfeld üblich sind, so etwa in der Bildverarbeitung und in der Kundensegmentierung.
Der k-Means-Algorithmus ist eines der am häufigsten verwendeten mathematischen Verfahren zur Gruppierung von Objekten (Clusteranalyse), beispielsweise von Bilddaten. Der Algorithmus ist in der Lage, aus einer Menge ähnlicher Objekte mit einer vorher bekannten Anzahl von Gruppen die jeweiligen Zentren der Cluster zu ermitteln. Da es sich um ein sehr effizientes Verfahren handelt, das mit vielen verschiedenen Datentypen zurechtkommt und der Speicherbedarf gering ist, eignet sich der k-Means-Algorithmus für die Datenanalyse im Big-Data-Umfeld.
Die Laufzeit des Algorithmus ist linear zur Anzahl der vorhandenen Datenpunkte und die Anzahl der Schleifendurchläufe (Iterationen) zur Ermittlung der Clusterzentren ist relativ klein. Die Idee für den k-Means-Algorithmus stammt ursprünglich von Hugo Steinhaus aus dem Jahr 1957. Erst 1982 wurde der Algorithmus in einer Informatik-Zeitschrift veröffentlicht. Es besteht eine große Ähnlichkeit zum sogenannten Expectation-Maximization-Algorithmus. Eine weitere Variante ist die von Hartigan und Wong, die unnötige Distanzberechnungen vermeidet, indem sie auch den Abstand zum zweitnächsten Mittelpunkt verwendet. Für den k-Means-Algorithmus existieren verschiedene Erweiterungen wie k-Means++ oder der k-Median-Algorithmus (dazu später mehr).
Ziele der Clusteranalyse mit dem k-Means-Algorithmus
Die Clusteranalyse ist ein Verfahren, mit dem sich eine bestimmte Anzahl von Objekten in homogene Gruppen einteilen lässt. Das Ziel besteht darin, dass die verschiedenen Objekte innerhalb einer Gruppe sich nach der erfolgten Einteilung möglichst ähnlich sind. Die Eigenschaften der Objekte sind in Dimensionen eingeteilt. Die Gruppen nennen sich Cluster. Der k-Means-Algorithmus lässt sich für mehrdimensionale Objekte anwenden und nähert sich durch sich ständig wiederholende Neuberechnungen (Iterationen) den jeweiligen Clusterzentren an, bis keine signifikante Veränderung mehr stattfindet. Diese Clusterzentren lassen sich entsprechend kenntlich machen, etwa durch Farbe (siehe dazu die Abbildungen).
Typischer Ablauf des k-Means-Algorithmus

Der k-Means-Algorithmus findet Anwendung auf Daten oder Objekte in einem n-dimensionalen Raum. Das Verfahren verläuft in folgenden Schritten:
- 1. Wahl von k-Punkten als Anfangszentren der Berechnung (dieser Schritt ist von entscheidender Bedeutung);
- 2. Zuordnung der Datenpunkte zu den verschiedenen Clustern auf Basis des Abstands (siehe „Distanzen“) zu den Zentren
- 3. Neuberechnung der Clusterzentren
- 4. Wiederholung ab Schritt 2 – bis sich die Lage der Zentren nicht mehr ändert.
In den ersten Durchläufen des Algorithmus treten noch große Änderungen der Zentren auf. Mit zunehmenden Schleifendurchläufen werden die Veränderungen immer kleiner. Wesentlich für einen effizienten Ablauf des Algorithmus ist die Wahl der Anfangszentren.
Probleme bei der Anwendung des k-Means-Verfahrens
Ein Problem bei der Anwendung des k-Means-Algorithmus stellt die Vorgabe der Anzahl der Cluster und die Wahl der Anfangszentren dar. Die gefundene Lösung ist daher stark von den gewählten Startpunkten abhängig. Zur Wahl der Startpunkte ist die Kenntnis einer gewissen Clusterstruktur notwendig, die aus Voranalysen der Daten stammen könnte. In vielen Fällen erfolgt der Durchlauf des Algorithmus mit unterschiedlichen Startwerten. Die verschiedenen Ergebnisse liefern Hinweise auf eine möglichst plausible Struktur der Cluster.
Achtung: Verwendet man eine ungeeignete Anzahl von Clusterzentren als Startwerte, können sich unter Umständen komplett andere Lösungen oder sogar ungeeignete Clustereinteilungen ergeben.
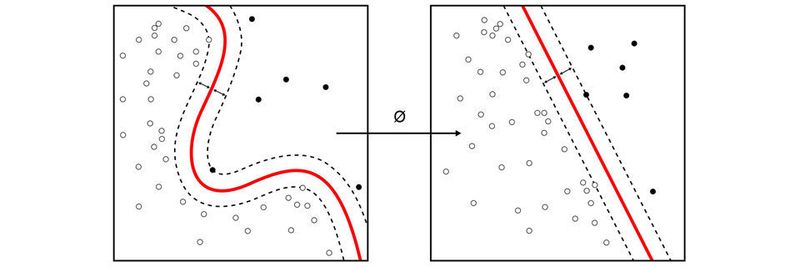
Auch problematisch für den k-Means-Algorithmus sind Datenmengen, die sich überlappen oder in Teilen nahtlos ineinander übergehen. In diesen Fällen ist das k-Means-Verfahren nicht in der Lage, die verschiedenen Gruppen zuverlässig voneinander zu trennen. Daten mit hierarchischen Clusterstrukturen werden ebenfalls nicht unterstützt. Sind Ausreißer in der Datenmenge vorhanden, können diese das Ergebnis stark verfälschen, da k-Means keine Ausreißer erkennt und jedes Objekt einem Cluster zuordnet. In diesen Fällen ist vor der Auswertung mit dem k-Means-Algorithmus eine Bereinigung der Daten (Noisereduktion) durchzuführen.
Alternativen und Variationen
J. B. MacQueen führte einen anderen Algorithmus ein, den er „k-Means“ nannte:
- 1. Wähle die ersten k Elemente als Clusterzentren
- 2. Weise jedes neue Element dem Cluster zu, bei dem sich die Varianz am wenigsten erhöht, und aktualisiere das Clusterzentrum
Man kann auch diesen Algorithmus iterieren, um ein besseres Ergebnis zu erhalten.
Die Erweiterung k-Means++
Für den k-Means-Algorithmus existiert die Erweiterung k-Means++. Sie beschreibt ein Verfahren, mit dem die Clusterzentren als Startwerte nicht mehr zufällig, sondern nach einer Vorschrift gewählt werden. Dabei werden die Clusterzentren als Startwerte bestimmt. In der Regel konvergiert der nachfolgende k-Means Algorithmus in wenigen Schritten. Die Ergebnisse sind so gut wie bei einem üblichen k-Means-Algorithmus, jedoch ist der Algorithmus typischerweise fast doppelt so schnell wie der k-Means-Algorithmus.
Eine weitere Erweiterung ist K-Median. Im k-Median-Algorithmus wird im Zuweisungsschritt statt der euklidischen Distanz die Manhattan-Distanz verwendet. Im Updateschritt wird der Median statt des Mittelwerts verwendet.
Variationen
- k-Means ++ versucht bessere Startpunkte zu finden.
- Der Filtering-Algorithmus verwendet als Datenstruktur einen K-d-Baum.
- Der k-Means-Algorithmus kann unter Berücksichtigung der Dreiecksungleichung beschleunigt werden.
- „Bisecting k-means“ beginnt mit k = 2 und teilt dann immer den größten Cluster, bis das gewünschte k erreicht ist.
- „X-means“ beginnt mit k = 2 und erhöht k so lange, bis sich ein sekundäres Kriterium nicht weiter verbessert.
Die Erweiterung K-Medoids (PAM)
Der Algorithmus PAM (Partitioning Around Medoids, 1990) – auch bekannt als k-Medoids – kann als Variante des k-Means-Algorithmus interpretiert werden, die mit beliebigen Distanzen konvergiert.
- 1. Wähle k Objekte als Cluster-Schwerpunkte (Medoid) aus
- 2. Ordne jedes Objekt dem nächsten Cluster-Schwerpunkt zu
- 3. Für jeden Cluster-Schwerpunkt und jeden Nicht-Cluster-Schwerpunkt vertausche die Rollen
- 4. Berechne für jede Vertauschung die Summe der Distanzen oder Unähnlichkeiten
- 5. Wähle als neue Cluster-Schwerpunkte die Vertauschung, die die kleinste Summe liefert
- 6. Wiederhole 2. bis 5. solange, bis sich die Cluster-Schwerpunkte nicht mehr ändern
In der ursprünglichen Version von PAM macht hierbei der erste Schritt – die Wahl der initialen Medoiden – einen großen Teil des Algorithmus aus. Da in jeder Iteration stets nur die beste Vertauschung durchgeführt wird, ist der Algorithmus nahezu deterministisch (bis auf exakt gleiche Distanzen). Achtung: Dadurch ist der Algorithmus aber auch meist sehr langsam!
Während k-Means die Summe der Varianzen minimiert, minimiert k-Medoids die Distanzen. Insbesondere kann dieser Algorithmus mit beliebigen Distanzfunktionen verwendet werden und konvergiert dennoch garantiert. Man sieht: Die Erweiterungen und Alternativen des k-Means-Algorithmus erlauben eine willkommene Ausweitung des Anwendungsbereichs des Algorithmus. Meist lässt sich eine doppelte Ausführungsgeschwindigkeit erzielen.
Anwendungen des k-Means-Algorithmus
 im Iris-Flower-Datensatz, visualisiert mit der Software ELKI. Die Clusterzentren sind durch größere, blassere Symbole gekennzeichnet. Gruppen in den Daten können sich, wie im Schwertlilien-Beispiel,, überlappen und nahtlos ineinander übergehen. In einem solchen Fall kann k-Means diese Gruppen nicht zuverlässig trennen, da die Daten nicht dem verwendeten Cluster-Modell folgen.")
Der k-Means-Algorithmus findet in vielen Bereichen der Informationstechnik Anwendung. Aufgrund seiner Effizienz und des geringen Speicher- und Rechenbedarfs eignet er sich für die Datenanalyse großer Datenmengen im Big-Data-Umfeld.
In der Bildverarbeitung wird k-Means häufig zur Segmentierung der Bilddaten (siehe Schwertlilien-Abbildung) eingesetzt. Als Entfernungsmaß ist die euklidische Distanz häufig nicht ausreichend und es können andere Abstandsfunktionen, basierend auf Pixelintensitäten und Pixelkoordinaten verwendet werden.
Mit den Ergebnissen des Algorithmus ist beispielsweise die Trennung von Vorder- und Hintergrund oder das Erkennen von einzelnen Objekten möglich. Das ist für die Vorbereitung der Bilderkennung und Bild-Verschlagwortung mithilfe von Deep-Learning-Methoden sehr nützlich. Das DL-Framework Torch und Scikit-learn umfassen k-Means.
Ein weiterer wichtiger Anwendungsbereich sind das Marketing und die Analyse des Kundenverhaltens. k-Means findet in vorliegenden Kundendaten verschiedene Gruppen von Kunden mit jeweils ähnlichem Kundenverhalten. Die von k-Means ermittelten homogenen Gruppen (Kundensegmente, Zielgruppen) lassen sich klar voneinander trennen. Mithilfe spezifischer Marketingmaßnahmen sind die Gruppen effizienter und mit größerer Erfolgsaussicht ansprechbar. Dies ist für Marketingkampagnen, etwa in sozialen Netzwerken, von hoher Bedeutung.
Software
Der Algorithmus ist weit verbreitet und ist in gängigen Bildverarbeitungsbibliotheken wie OpenCV und itk implementiert. Eine ausführliche Software-Liste findet man im entsprechenden Artikel der englischsprachigen Wikipedia, der sowohl freie, quelloffene Software wie ELKI als auch proprietäre Programme wie etwa SAS, IBM SPSS oder SAP HANA erwähnt. Gut zu wissen, wenn man Statistiker ist: Sowohl die R-Distribution GNU-R als auch die Machine Learning Bibliothek (MLIib) in Apache Spark enthalten k-Means. Dass allein R bereits drei k-Means-Variationen umfasst, unterstreicht die hohe Bedeutung und weite Verbreitung dieses Algorithmus.
:quality(80)/images.vogel.de/vogelonline/bdb/1396700/1396763/original.jpg "2013 führte der US-Paketdienst UPS das Navigationssystem ORION ein (On-Road Integrated Optimization and Navigation) ein. Dieses berücksichtigt garantierte Lieferfristen für einzelne Pakete, angemeldete Abholungen und spezielle Kundenklassen mit bevorzugter Bedienung sowie Daten aus dem Verkehrsfluss in Echtzeit. (UPS)")
Grundlagen Statistik & Algorithmen, Teil 1
Das Problem des Handlungsreisenden und seine praktischen Anwendungen
:quality(80)/images.vogel.de/vogelonline/bdb/1404000/1404092/original.jpg "Illustration des Satzes von Bayes durch Überlagerung der beiden ihm zugrundeliegenden Entscheidungsbäume bzw. Baumdiagramme. (Qniemiec / CC BY-SA 3.0)")
Grundlagen Statistik & Algorithmen, Teil 2
So verfeinert das Bayes-Theorem Spam-Filter – und mehr
:quality(80)/images.vogel.de/vogelonline/bdb/1409900/1409917/original.jpg "Prinzipbild des Rete-Algorithmus. Deutlich sind zwei Netzwerke (Alpha, Beta) zu erkennen und dass darin jeweils sehr viel Speicher benötigt wird. Dieser hohe Speicherbedarf ist einer der wenigen Nachteile des Rete-Algorithmus. (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 3
Speed für Mustererkennung mit dem Rete-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1430600/1430659/original.jpg "Der monegassische Stadtbezirk Monte-Carlo (© Noppasinw - stock.adobe.com)")
Grundlagen Statistik & Algorithmen, Teil 4
Der Monte-Carlo-Algorithmus und -Simulationen
:quality(80)/images.vogel.de/vogelonline/bdb/1509200/1509209/original.jpg "Ereigniszeitanalyse mit zensierten Daten für die Vertriebsabteilung: die Überlebensfunktion für Vertriebstechniker (durchgezogene Linie) und für Vertreter (gestrichelte Linie) in einem Kaplan-Meier-Schätzer. Vertriebstechniker sind ihrer Stelle wesentlich stärker und länger treu als Vertreter. Der blaue und rötliche Hintergrund deckt sich mit der jeweiligen Kurve. (SAS)")
Grundlagen Statistik & Algorithmen, Teil 6
Die Ereigniszeitanalyse – wenn Anfang und Ende die Erfolgsrate bestimmen
:quality(80)/images.vogel.de/vogelonline/bdb/1524900/1524972/original.jpg "Kernidee von LOF ist, die lokale Dichte eines Punktes mit der seiner Nachbarn zu vergleichen- (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 7
So deckt der Local Outlier Factor Anomalien auf
(ID:45588052)
:quality(80)/p7i.vogel.de/wcms/57/f5/57f51fb2030e615747fcfba43835725d/0128237968v1.jpeg "Microsoft Research hat FLAML initiert und auch in Azure zur Verfügung gestellt. (Bild: Microsoft)")
:quality(80)/p7i.vogel.de/wcms/fb/6b/fb6b964b51448dcb96c121eee0baacb9/0129173166v1.jpeg "Quanten-KI heißt nicht, einfach bestehende KI-Modelle beziehungsweise -Algorithmen auf schnellere Rechner zu portieren; auf Quantencomputern gelten andere Gesetzmäßigkeiten als in der Digitalwelt, die überraschende Ergebnisse liefern. (Bild: IBM/Flickr)")