
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b5/f4/b5f489601994978d1730f20e206002f7/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/83/9e/839e53e64bfed2ccc4a4601f74681ff5/0132065310v1.jpeg "Wo KI vor der eigentlichen Arbeit stehen bleibt, statt in die Kernprozesse einzuziehen, übernehmen Beschäftigte weiterhin das manuelle Verbinden getrennter Systeme. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Grundlagen Statistik & Algorithmen, Teil 6 Die Ereigniszeitanalyse – wenn Anfang und Ende die Erfolgsrate bestimmen
Die Ereigniszeitanalyse bzw. Survival Analysis umfasst eine Reihe von Werkzeugen der Statistik, mit denen die Zeit bis zum Eintritt eines bestimmten Ereignisses zwischen Gruppen verglichen wird. Auf diese Weise will man die Wirkung von prognostischen Faktoren, einer medizinischen Behandlung oder von schädlichen Einflüssen abschätzen. Bei dem Ereignis kann es sich um etwas so Endgültiges wie den Tod handeln, aber auch um den Verlust einer Arbeitsstelle, eine Scheidung oder einen Beginn, etwa um eine Geburt oder einen Heilungseintritt.
Mit dem Sammelbegriff der „Survival- und Ereigniszeitanalyse“ werden eine Reihe von statistischen Verfahren bezeichnet, die der Untersuchung von Zeitintervallen zwischen aufeinander folgenden Ereignissen oder Zustandswechseln dienen. Die von den Untersuchungseinheiten wie etwa Individuen, Haushalten oder Organisationen eingenommenen Zustände sind dabei stets abzählbar.
In der Regel handelt es sich um eine relativ begrenzte Anzahl von Zuständen wie etwa hohe/tiefe Körpertemperatur, hohe/niedrige Feuchtigkeit usw. Die erfassten Ereignisse können zu beliebigen Zeitpunkten eintreten, bezeichnen aber für gewöhnlich einen Anfangs- oder Endpunkt, wie etwa eine Geburt, eine Inbetriebnahme, eine Heilung, eine Erkrankung oder das Lebensende – auch das einer Maschine.
Anwendungsfelder
Weil die Ereigniszeitanalyse in der Soziologie und in den Ingenieursdisziplinen so vielfältig verwendbar ist, lassen sich zahlreiche Beispiele für solche Prozesse finden. So sind etwa die Dauer der Arbeitslosigkeit bis zum Beginn einer neuen Erwerbstätigkeit für die Arbeitsmarktforschung interessant. Die Zeit in einer beruflichen Tätigkeit bis zu einem sozialen Aufstieg ist für die soziale Mobilitätsforschung von Interesse. Die Dauer bis zu einem Umzug an einen anderen Ort ist für die Migrationsforschung relevant. Die Ehedauer bis zur Scheidung taucht in der demografischen Forschung auf und die Überlebenszeiten von Patienten werden in medizinischen Studien erfasst.
Analog dazu lassen sich Maschinen beschreiben, etwa im Smart Grid, in einer komplexen Maschine oder in einem sensorgestützten IoT-System. Deshalb wird das Verfahren im Englischen auch „Reliability Theory“, also Zuverlässigkeitsanalyse, genannt. Üblicherweise werden nur Ereignisse untersucht, die höchstens ein Mal pro Subjekt bzw. Gruppe auftreten können, etwa eine Lebenszeit. Eine Erweiterung auf wiederholt auftretende Ereignisse ist indes möglich.
Statistische Funktionen
Es geht stets darum, zentrale Kenngrößen wie etwa die Überlebensrate einer Gruppe oder die Zuverlässigkeit einer Maschine herauszufinden. Daraus folgt, dass die Überlebensfunktion S analog zur Zuverlässigkeitsfunktion R(t) berechnet wird, wobei der Faktor t Zeit ist und P die Höhe der Wahrscheinlichkeit: S(t) = R(t) = P (T>t). T ist die verbleibende Dauer zum Lebensende eines Organismus oder zum Ausfall eines Geräts. Normalerweise ist S(0) = 1, sonst kann nämlich ein sofortiger „Tod“ oder Geräteausfall eintreten.
Aus der Überlebensfunktion lassen sich verschiedene Größen ableiten. Die Ereigniszeit-Verteilungsfunktion, in technischem Bezug auch als Ausfallswahrscheinlichkeit („Probability of failure“) bezeichnet und mit F abgekürzt, ist die komplementäre Funktion zur Überlebensfunktion: F(t). Die erste Ableitung von F, die Ereignisdichtefunktion oder Ausfallsdichte („failure density function“), wird mit f bezeichnet. Die Ereignisdichtefunktion ist die Rate des betrachteten Ereignisses pro Zeiteinheit.
Die Ausfallrate, auch als Hazardfunktion bezeichnet und mit h(t) bezeichnet, ist definiert als Häufigkeit, mit der ein Ereignis zum Zeitpunkt T eintritt, vorausgesetzt, dass es bis zum Zeitpunkt t noch nicht eingetreten ist. Der englische Ausdruck „force of mortality“ (Sterblichkeitsrate) wird speziell in der Demografie verwendet. Die Hazardfunktion kann anwachsen oder fallen, sie braucht weder monoton noch stetig zu sein.
Die verbleibende Lebenszeit zu einem Zeitpunkt t0 ist die bis zum Tod bzw. Ausfall verbleibende Zeit, also T - t0. Die zukünftige Lebenserwartung ist der Erwartungswert der verbleibenden Lebenszeit. Für t0 = 0 reduziert sich dies auf die Lebenserwartung bei der Geburt. In Zuverlässigkeitsanalysen wird die Lebenserwartung englisch „mean time to failure“ (MTTF) und die zukünftige Lebenserwartung englisch „mean residual lifetime“ (MRL) genannt. MTFF ist eine obligatorische Angabe für jede Art von elektrischem oder elektronischem Gerät. Nach Ablauf dieses „Mindesthaltbarkeitsdatums“ sollte das Gerät ausgetauscht werden.
Weitere Methoden
Die statistischen Methoden der Ereigniszeitanalyse reichen von den deskriptiven Verfahren der Survivalanalyse (z. B. Sterbetafel-Methode und Kaplan-Meier-Schätzung), über das semiparametrische Regressionsmodell von Cox, bis zu den parametrischen Verfahren mit und ohne Zeitabhängigkeiten, so etwa dem Exponential-, Piecewise-Constant-, Gompertz (-Makeham)-, Weibull- oder log-logistischen Modell. Im begrenzten Rahmen dieses Beitrag können nur der Kaplan-Meier-Schätzer und das Cox-Modell näher vorgestellt werden.
Kaplan-Meier-Schätzer (KMS)
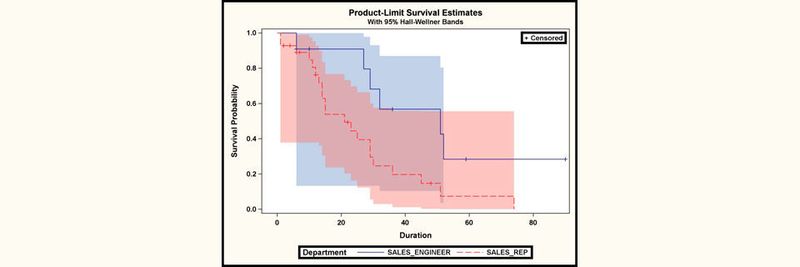
Der Kaplan-Meier-Schätzer-Algorithmus, bereits 1958 formuliert, ist eine der am häufigsten verwendeten Methoden der „Survival Analysis“ und in praktisch jedem Statistikpaket (SAS, R, Mathematica, Python usw.) zu finden. Der KMS dient zum Schätzen der Wahrscheinlichkeit, dass bei einem Versuchsobjekt ein bestimmtes Ereignis innerhalb eines Zeitintervalls nicht eintritt.
Es handelt sich um eine nichtparametrische Schätzung der Überlebensfunktion (s.o.) im Rahmen der Ereigniszeitanalyse. Der KMS lässt sich beispielsweise nutzen, um die Sterbewahrscheinlichkeit eines Patienten oder die Ausfallwahrscheinlichkeit eines Geräts zu kalkulieren.
Für eine KM-Verlaufskurve sind zwei Daten nötig: der Status der letzten Messung bzw. Beobachtung und die Zeit bis zum Ereignis. Sollen die Überlebensfunktionen zweier Gruppen verglichen werden, wird ein drittes Datum benötigt: die Gruppenzuordnung jeden Subjekts. Auf diese Daten braucht man nur noch die KM-Formel anwenden.
 und Hazard-Funktion (Zacken). Wann immer die Überlebens-Kurve einen Einbruch erlebt, taucht ein signifikanter Zacken auf. Je höher der Zacken, desto tiefer der Einbruch.")
Das Verlaufsdiagramm eines KM-Schätzers (siehe Abbildungen) besteht aus einer Reihe von absteigenden horizontalen Schritten bzw. Stufen, welche, eine ausreichend große Datenmenge vorausgesetzt, sich der wahren Überlebensfunktion (s. o.) dieser Bevölkerungsgruppe annähert. Der Wert der Überlebensfunktion zwischen aufeinanderfolgenden Messungen bzw. Beobachtungen wird als konstant angenommen.
Ein großer Vorteil dieser KM-Kurve besteht darin, dass die Methode auch manche Arten von zensierten Daten berücksichtigen kann, besonders rechts zensierte. Häufig werden Daten nämlich links oder rechts zensiert. Wenn Geburt und Tod bekannt sind, dann ist in diesem Fall der Lebensverlauf eindeutig. Wenn man dagegen nur weiß, dass die Geburt vor einem bestimmten Zeitpunkt stattfand, dann nennt man diesen Datensatz links zensiert.
Genauso könnte nur bekannt sein, dass der Tod nach einem bestimmten Datum eintrat. Das ist dann ein rechts zensierter Datensatz. Ein Lebenslauf kann auf diese Weise auch rechts und links zensiert sein (intervallzensiert). Falls eine Person, die ein bestimmtes Alter nicht erreicht, überhaupt nicht beobachtet wird, dann ist der Datensatz abgeschnitten (engl.: truncated). Bei einem links zensierten Datensatz weiß man dagegen zumindest, dass das Individuum existierte.
 und Wahrscheinlichkeit (y-Achse).")
Im Verlaufsdiagramm zeigen kleine Häkchen an, dass einzelne Patienten Überlebenszeiten aufweisen, die rechts-zensiert wurden. Um die Verlässlichkeit auszudrücken, ist im KM-Schätzer das Konfidenzintervall eingeführt worden. Ein Konfidenzintervall ist ein Intervall aus der Statistik, das die Präzision der Lageschätzung eines Parameters angeben soll. Das Konfidenzintervall gibt den Bereich an, der bei unendlicher Wiederholung eines Zufallsexperiments mit einer gewissen Wahrscheinlichkeit die wahre Lage des Parameters einschließt. Das Konfidenzintervall kann aus der Varianz bzw. dem Standardfehler berechnet werden.
Regressionsmodell von Cox
Die Cox-Regression ist eine nach David Cox benannte Regressionsanalyse zur Modellierung von Überlebenszeiten. Wie alle ereigniszeitanalytischen Methoden ist sie ein Verfahren zur Schätzung des Einflusses unabhängiger Variablen auf die Dauer bis zum Eintreten von Ereignissen („Überlebenszeit“) bzw. deren Hazard. Als sogenanntes semiparametrisches Verfahren liefert die Cox-Schätzung kein komplettes Vorhersagemodell für die Überlebenszeit, sondern lässt die Verteilungsfunktion der beobachteten Episodenenden unspezifiziert. Sie schätzt ausschließlich den Einfluss metrischer oder kategorialer Variablen auf einen Baseline-Hazard, von dem angenommen wird, dass er über alle Fälle hinweg konstant ist.
Die Anwendungsgebiete sind ähnlich wie in der Ereigniszeitanalyse. Das von Cox vorgeschlagene Regressionsmodell wird zur Untersuchung des Verhaltens der Ausfallraten in Abhängigkeit von Umwelteinflüssen benutzt, beispielsweise von Soldaten unter Beschuss. Grundlage des Modells sind die Einflussvektoren z von i, mit i = 1 bis n, die für jedes Individuum der Studie beobachtet werden können. Der Zusammenhang zwischen diesen Einflüssen und der Ausfallfunktion wird dann über eine festgelegte Relation h hergestellt.
H von 0 bezeichnet dabei eine unbekannte Ausfallfunktion, die im Ausgangsfall ohne Einflüsse die zugehörige Ausfallfunktion darstellt. ß ist ein unbekannter Parameter, ebenfalls n-dimensional. Aufgabe der Statistik ist die Schätzung dieses Parameters.
Da Jahrzehnte seit der Konzeption dieser beiden Methoden vergangen sind, wurden sie im Laufe der Zeit erweitert, verfeinert und modifiziert. So ist es dem Statistiker möglich, zahlreiche vom Standard abweichende Fälle zu berechnen. In jüngster Zeit kommt den Methoden der Ereignisanalyse eine besondere Bedeutung bei der Weiterentwicklung der Kausalanalyse, der Untersuchung von parallelen und interdependenten Prozessen und der Mehrebenenanalyse zu. Sicher ist aber, dass die Ereigniszeitanalyse mit bedeutenden Algorithmen arbeitet, die in keinem Statistikpaket fehlen dürfen.
:quality(80)/images.vogel.de/vogelonline/bdb/1396700/1396763/original.jpg "2013 führte der US-Paketdienst UPS das Navigationssystem ORION ein (On-Road Integrated Optimization and Navigation) ein. Dieses berücksichtigt garantierte Lieferfristen für einzelne Pakete, angemeldete Abholungen und spezielle Kundenklassen mit bevorzugter Bedienung sowie Daten aus dem Verkehrsfluss in Echtzeit. (UPS)")
Grundlagen Statistik & Algorithmen, Teil 1
Das Problem des Handlungsreisenden und seine praktischen Anwendungen
:quality(80)/images.vogel.de/vogelonline/bdb/1404000/1404092/original.jpg "Illustration des Satzes von Bayes durch Überlagerung der beiden ihm zugrundeliegenden Entscheidungsbäume bzw. Baumdiagramme. (Qniemiec / CC BY-SA 3.0)")
Grundlagen Statistik & Algorithmen, Teil 2
So verfeinert das Bayes-Theorem Spam-Filter – und mehr
:quality(80)/images.vogel.de/vogelonline/bdb/1409900/1409917/original.jpg "Prinzipbild des Rete-Algorithmus. Deutlich sind zwei Netzwerke (Alpha, Beta) zu erkennen und dass darin jeweils sehr viel Speicher benötigt wird. Dieser hohe Speicherbedarf ist einer der wenigen Nachteile des Rete-Algorithmus. (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 3
Speed für Mustererkennung mit dem Rete-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1430600/1430659/original.jpg "Der monegassische Stadtbezirk Monte-Carlo (© Noppasinw - stock.adobe.com)")
Grundlagen Statistik & Algorithmen, Teil 4
Der Monte-Carlo-Algorithmus und -Simulationen
:quality(80)/images.vogel.de/vogelonline/bdb/1481900/1481934/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Grundlagen Statistik & Algorithmen, Teil 5
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1524900/1524972/original.jpg "Kernidee von LOF ist, die lokale Dichte eines Punktes mit der seiner Nachbarn zu vergleichen- (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 7
So deckt der Local Outlier Factor Anomalien auf
(ID:45704766)
:quality(80)/p7i.vogel.de/wcms/d3/a3/d3a31ea4e0bc62c49bf42099f907b6c6/0129912380v1.jpeg "Erst durch semantische Harmonisierung werden KI und Advanced Analytics realisierbar und ohne eine einheitliche Semantik bleibt der Einsatz von KI in der Industrie oft ein isoliertes Experiment ohne klaren ROI. (Bild: © shobakhul - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/27/af/27af31f63218e7b98932076f3a014418/0131071281v1.jpeg "Der SAS Viya Copilot umfasst mehrere Agenten, die die KI-Nutzung erleichtern und beschleunigen sollen. (Bild: SAS)")