
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Grundlagen Statistik & Algorithmen, Teil 3 Speed für Mustererkennung mit dem Rete-Algorithmus
Geschäftsregeln halten zahlreiche Unternehmensprozesse am Laufen, deshalb können sie mitunter sehr umfangreich werden. Der Umfang macht ihre Ausführung zeitaufwendig, weshalb jede Methode, sie zu beschleunigen, willkommen ist. Der Rete-Algorithmus beschleunigte 1979 die damals bestehenden Systeme für die Verarbeitung von Business Rules um den Faktor 3.000. Er ist bis heute die Grundlage zahlreicher Expertensysteme, etwa in der Mustererkennung.
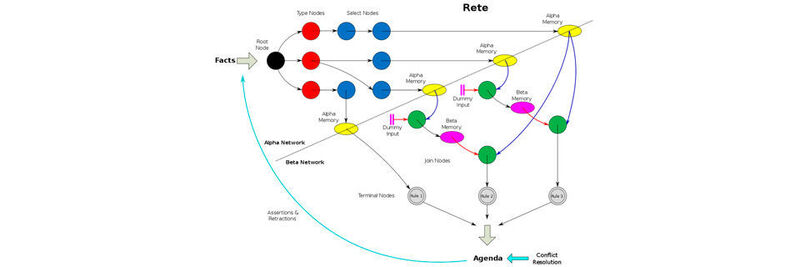
Der Rete-Algorithmus (lateinisch rete „Netz“, „Netzwerk“) ist ein Algorithmus und Expertensystem zur Mustererkennung und zur Abbildung von Systemprozessen über Regeln. Ist eine bestimmte Menge von Bedingungen erfüllt, wird eine oder mehr Regeln ausgeführt. Aber es gibt natürlich Konflikte.
Der ganze Ablauf wird von einem Interpreter orchestriert, der die Nutzung von zwei Speicherbereichen steuert. Im ersten Speicherbereich, dem Production Memory, befindet sich eine Reihe von Regeln, die als „productions“ bezeichnet werden. Im Data Memory hingegen befindet sich eine Reihe von Fakten in einer Datenbank.
Zuerst schaut ein Mustervergleicher des Interpreters in beiden Speicherbereichen nach, welche Fakten zu den Bedingungen der Regeln passen, um sie zu erfüllen. Der Vergleicher erstellt eine Liste von erfüllten Regelbedingungen, schickt sie an den Konfliktlöser, der mithilfe eines Algorithmus untersucht, welche Regel am besten für die Lösung der Aufgabe geeignet ist.
Ist der Konflikt bereinigt, wird die ausgewählte Regel angestoßen und im geeigneten System (Arbeitsspeicher) ausgeführt. Die Regel führt Änderungen herbei, entweder im Production Memory oder im Data Memory. Dann beginnt der Zyklus von vorne. Das Zuweisen von Regeln zu Daten wird „Inferenz“ genannt, ein Vorgang, der in der Mustererkennung mittels Deep Learning heute (wieder) sehr aktuell ist. Die Inferenz muss beispielsweise beim Autonomen Fahren extrem schnell ablaufen, damit das Verhalten des KI-gestützten Systems keine Schäden verursacht.
Der Rete-Algorithmus vergleicht die Fakten und zieht Schlussfolgerungen. Liegen Fakt X und Bedingung Y im Data Memory vor, dann sollte vom Konfliktlöser eine bestimmte Regel aus dem Production Memory ausgewählt werden. Das Vergleichen im Konfliktlöser kann angesichts vieler Daten und Tausenden von möglichen Regeln sehr lange dauern.
Beispiel
Ein Detektiv kann als ein menschliches Expertensystem angesehen werden, denn er oder sie ist ein Experte für Fakten, Bedingungen und Vergleiche.
- 1. Wenn eine Person X etwas Illegales getan hat, so ist X ein Verbrecher.
- 2. Befinden sich Fingerabdrücke von X auf einem Gegenstand Y, denn hat X Objekt Y zu einem vergangenen Zeitpunkt berührt.
- 3. Falls Person X Person Y erschossen hat, dann hat Person X etwas Illegales getan.
- 4. Falls Person X (oder auch Y) tot ist, dann sollte Person X nicht zum Abendessen eingeladen werden.
- 5. Person X heißt Fred.
- 6. Person Y heißt Sam und ist tot.
- 7. Fred erschoss Sam und sollte nicht zum Abendessen eingeladen werden.
Die Konfliktmenge enthält wie oben formuliert zwei Regeln. Der Rete-Algorithmus führt sie zusammen und löst den Konflikt. Vor der Formulierung des Rete-Algorithmus prüften Systeme jede einzelne Regel daraufhin, ob sie zu den Fakten passte – in Iterationen. Durch das Indizieren der Daten und der Regelelemente in einem Index konnte der Prozess des Mustervergleichs zwar beschleunigt werden, aber erst Rete eliminiert die Iteration. Er speichert die Elemente der Konfliktmenge im Arbeitsspeicher und addiert oder löscht sie dort, je nachdem welche Datenelemente addiert oder gelöscht werden. Eine iterative Wiederholung wird überflüssig.
:quality(80)/images.vogel.de/vogelonline/bdb/1396700/1396763/original.jpg "2013 führte der US-Paketdienst UPS das Navigationssystem ORION ein (On-Road Integrated Optimization and Navigation) ein. Dieses berücksichtigt garantierte Lieferfristen für einzelne Pakete, angemeldete Abholungen und spezielle Kundenklassen mit bevorzugter Bedienung sowie Daten aus dem Verkehrsfluss in Echtzeit. (UPS)")
Grundlagen Statistik & Algorithmen, Teil 1
Das Problem des Handlungsreisenden und seine praktischen Anwendungen
Wenn beispielsweise die Regel auftaucht: „Wenn jemand eine Waffe auf mich abfeuert, ducke ich mich“, dann müssen mehrere Daten gegeben sein: Eine Waffe ist gefährlich und jemand feuert eine auf mich ab usw. Daher ist es klug und lebenserhaltend, der Kugel durch Ducken aus dem Wege zu gehen. Unter anderen Fakten und Bedingungen – etwa Geschosse, die ein automatisches Zielsuchsystem besitzen – sind andere Regeln für das Verhalten sinnvoller. Immer wenn sich etwas in dieser Konfliktmenge ändert, wird das zugehörige Muster (die Regel) geändert und alle vorherigen Muster gelöscht. Der Vorteil: Der Algorithmus muss nie im Data Memory nachschauen – und auch nicht alle potentiellen Regeln abklappern. Denn es gibt eine zweite Rete-Hälfte, die das obsolet macht.
Rete speichert die Bedingungen aller „production“-Regeln in einem Sortier-Netzwerk, das wie ein Baum aufgebaut ist. Der Algorithmus kompiliert das Netzwerk aus der Liste dieser Regeln und hält anschließend das Netzwerk auf dem laufenden, sobald Regeln zur Liste addiert oder daraus gelöscht werden.
Um zu verstehen, wie das funktioniert, schaut man sich ein paar Regeln im Expertensystem eines Süßwarenherstellers an. Zwei Production-Regeln in diesem System lauten:
- 1. Regel für ROTE__RUNDE__STÜCKE: Der Zweck besteht darin, ein. Süßwarenstück zu bestimmen. Ist das Süßwarenmuster rot und außerdem noch rund, stellt man die Hypothese auf, es sei ein runder roter Lutscher.
- 2. Regel für ROTE_ZYLINDRISCHE_STÜCKE: Gleichermaßen stellt man für ein rotes, zylindrisches Muster die Hypothese auf, es handle sich um eine Zuckerstange.
Das baumförmige Sortiernetzwerk des Algorithmus nutzt diese Redundanzen aus. Der Mustervergleicher kompiliert ein Netzwerk aus einzelnen Unterbedingungen. Er schaut jedes einzelne Element einer Regeln an und erstellt daraus eine Kette aus Gliedern, deren Attribut sich einzeln prüfen lässt. Dann schaut sich der Algorithmus Vergleiche zwischen Elementen an (er vergleicht beispielsweise die OBJEKT-Variable des ZIELs mit der NAME-Variable [„Lutscher“ etc.] des SÜSSWARENMUSTERs) und verknüpft Ketten mit neuen Gliedern. Abschließend werden Endglieder hinzugefügt, um anzuzeigen, dass alle Bedingungen für die Regel erfüllt worden sind. In einem Artikel im „Dr. Dobbs Magazine“ wird die Funktionsweise für ein OPS genauer erklärt.
Heutiger Einsatz
RETE bildet heutzutage die Grundlage für viele Regelsysteme wie etwa diverse Prolog-Interpreter oder sogenannte Business Rules Engines und hat sich für diese als De-facto-Standard etabliert. Heute wird Rete überall gelehrt, implementiert (etwa im SAP Business Rules Management und sogar im Roboter-Fußball verwendet.
:quality(80)/images.vogel.de/vogelonline/bdb/1404000/1404092/original.jpg "Illustration des Satzes von Bayes durch Überlagerung der beiden ihm zugrundeliegenden Entscheidungsbäume bzw. Baumdiagramme. (Qniemiec / CC BY-SA 3.0)")
Grundlagen Statistik & Algorithmen, Teil 2
So verfeinert das Bayes-Theorem Spam-Filter – und mehr
Rete I war kostenlos, da das US-Verteidigungsministerium seine Entwicklung mit Steuergeldern finanzierte. Bislang gibt es zwei direkte Nachkömmlinge, nämlich Rete II und Rete III, die allerdings kostenpflichtig sind. Beide sind ungefähr 50-mal schneller als der ursprüngliche Ansatz. Rete III umfasst ein paar Erweiterungen, die seine Effizienz nochmals leicht erhöhen.
Er wurde vom US-amerikanischen Informatiker Charles Forgy im Rahmen seiner Doktorarbeit an der Carnegie Mellon University entwickelt, der ihn 1979 zum Titel führen sollte. Die Entwicklung war 1979 eng an die Plattform DEC XCON (DEC: Digital Equipment Corp.) angelehnt und fand ihre Implementierung zunächst in Betriebsunterstützungssystemen, speziell in OPS2 bzw. später in OPS5. Einsparungen in Millionenhöhe wurden benannt. Das implementierte Regelwerk hatte im Endausbau an die 10.000 Elemente.
Im Jahr 2010 entwickelte Forgy eine neue Generation des Rete-Algorithmus und nannte sie einfach Rete NT. In einem Benchmark-Test der Zeitschrift „InfoWorld“ wurde NT als 500-mal schneller als der ursprüngliche Algorithmus und zehnmal schneller als sein Vorgänger Rete II gemessen. NT ist jetzt an die Firma SparklingLogic lizenziert, in die Charles Forgy eintrat, und zwar als Inferenzmaschine des SMARTS-Produkts.
:quality(80)/images.vogel.de/vogelonline/bdb/1430600/1430659/original.jpg "Der monegassische Stadtbezirk Monte-Carlo (© Noppasinw - stock.adobe.com)")
Grundlagen Statistik & Algorithmen, Teil 4
Der Monte-Carlo-Algorithmus und -Simulationen
Das verbreitete Werkzeug Drools, das zusammen mit der Firma Jboss von IBM aufgekauft wurde, ist ein Beispiel für eine Business-Rule-Engine, die auf dem Rete-Algorithmus basierte. Seit Version 6.0 ist in Drools ein Nachfolge-Algorithmus namens PHREAK aktiv.
Als einziger Nachteil lässt sich nennen, dass die hohe Geschwindigkeit des Algorithmus zu Lasten des genutzten Speichers geht, doch das dürfte angesichts des heute zu Tiefpreisen verfügbaren Speichers kein Problem mehr sein. Und dass man seine Algorithmen stets möglichst effizient schreiben sollte, bedarf keiner gesonderten Erwähnung.
:quality(80)/images.vogel.de/vogelonline/bdb/1481900/1481934/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Grundlagen Statistik & Algorithmen, Teil 5
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1509200/1509209/original.jpg "Ereigniszeitanalyse mit zensierten Daten für die Vertriebsabteilung: die Überlebensfunktion für Vertriebstechniker (durchgezogene Linie) und für Vertreter (gestrichelte Linie) in einem Kaplan-Meier-Schätzer. Vertriebstechniker sind ihrer Stelle wesentlich stärker und länger treu als Vertreter. Der blaue und rötliche Hintergrund deckt sich mit der jeweiligen Kurve. (SAS)")
Grundlagen Statistik & Algorithmen, Teil 6
Die Ereigniszeitanalyse – wenn Anfang und Ende die Erfolgsrate bestimmen
:quality(80)/images.vogel.de/vogelonline/bdb/1524900/1524972/original.jpg "Kernidee von LOF ist, die lokale Dichte eines Punktes mit der seiner Nachbarn zu vergleichen- (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 7
So deckt der Local Outlier Factor Anomalien auf
(ID:45349547)
:quality(80)/p7i.vogel.de/wcms/90/c3/90c302b9470136bdcf725549552fe6b1/0129302897v1.jpeg "Drei Werkzeuge, drei Logiken: Automatisierung ist heute eine Frage der Auswahl, nicht der Ideologie. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")