
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/c8/8e/c88e128e6f3086c05cfffe26c73191bb/0131936826v1.jpeg "Wie lässt sich KI sicher, wirtschaftlich und skalierbar in Unternehmen einsetzen? Das war das zentrale Thema auf der Reply Xchange 2026 in der Münchener BMW Welt. (Bild: © Sandra Eckhardt & Sonja Herpic)")
:quality(80)/p7i.vogel.de/wcms/b8/d4/b8d434e1421217c59b03f7e269607aee/0131981690v1.jpeg "Schneller Code, fehlende Kontrolle: Laut GitLab fällt es vielen Teams schwer, KI-generierten Code im Lebenszyklus nachzuvollziehen (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Grundlagen Statistik & Algorithmen, Teil 8 Der Approximationsalgorithmus
Für verschiedene Probleme lassen sich nur durch Annäherung bzw. Approximation optimale Lösungen finden. Durch einen geeigneten Approximationsalgorithmus versuchen Informatiker, sich dem optimalen Ergebnis anzunähern, so etwa in der Graphentheorie, die Beziehungen in Netzwerken darstellt.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
In der Informatik und der Betriebswirtschaftslehre sind Approximationsalgorithmen effiziente Berechnungsmethoden, um angenäherte Lösungen für NP-harteOptimierungsprobleme zu finden. Diese Lösungen müssen beweisbare Garantien hinsichtlich der Entfernung der gelieferten Lösung von der optimalen vorlegen.
„Im Banking werden Approximationsalgorithmen für das Kredit-Scoring genutzt“, sagt Benjamin Aunkofer, Chief Data Scientist bei Datanomiq. „Als Anwendungsfall ist Kredit-Scoring zwar alt, kann aber eine stetige Verbesserung mit Machine Learning vorweisen.“ Aunkofer zählt weitere Use Cases auf, so etwa im Versicherungswesen: „Da geht es um Schadensprognosen.“
:quality(80)/images.vogel.de/vogelonline/bdb/1568400/1568457/original.jpg "(Thore Husfeldt / CC BY-SA)")
:quality(80)/images.vogel.de/vogelonline/bdb/1568400/1568458/original.jpg "(Cliquenproblem / MichaelGl / CC BY-SA 3.0)")
:quality(80)/images.vogel.de/vogelonline/bdb/1568400/1568459/original.jpg "(MichaelGl / CC BY-SA 3.0)")
:quality(80)/images.vogel.de/vogelonline/bdb/1568400/1568460/original.jpg "(MichaelGl / CC BY-SA 3.0)")
In der Industrie tauchen Approximationsalgorithmen in der prädiktiven Wartung alias Predictive Maintenance auf. „Hier geht es um die Beobachtung der Abnutzung und die anschließende Vorhersage der idealen Wartungsintervalle.“ Eine optimale Wartung kann über Menschenleben entscheiden.
Im Handel werden sehr große Summen umgesetzt, aber nur minimale Margen erzielt. Daher lohnt sich jeder Prozentpunkt hinterm Komma, um die Marge zu vergrößern. „Approximationsalgorithmen lassen sich hier zur Vorhersage der Nachfrage und der Retouren nutzen, also von der Produkt-Ebene über die Shop-Ebene bis hin zur Kunden-Ebene. Sie geben die Retouren-Wahrscheinlichkeit für jede einzelne Kundenbestellung an. Es lassen sich also Verlustrisiken ebenso berechnen wie die Kundenbevorzugung – etwa in einem Bonusprogramm – steuern.
Erstaunliche Theorien
In der theoretischen Informatik ergeben sich Approximationsalgorithmen aus der weithin akzeptierten Vermutung, dass P ungleich NP. Aufgrund dieser Vermutung lässt sich eine große Klasse von Optimierungsprobleme nicht in polynomieller Zeit lösen. Approximationsalgorithmen versuchen daher, sich optimalen Lösungen für solche Probleme in polynomieller Zeit zu nähern.
In der großen Mehrheit aller Fälle wird die o. a. Garantie durch Multiplikationsalgorithmen ausgedrückt: als Annäherungsrate oder -faktor. Das heißt, die die optimale Lösung liegt innerhalb eines (festgelegten) Multiplikationsfaktors der gelieferten Lösung. Auch die Addition lässt sich für diesen Zweck heranziehen.
Ein erwähnenswertes Beispiel für einen Approximationsalgorithmus, der beide Methoden mit Lösungen nutzt, ist der klassische Approximationsalgorithmus von Lenstra, Shmoys und Tardos namens „Scheduling on Unrelated Parallel Machines“. Dabei werden Maschinen, Aufgaben und Kosten miteinander korreliert. Man sieht: Es gibt handfeste Anwendungsgebiete für diese scheinbar so abstrakte Methode, wie die auch die oben genannten Anwendungsfälle illustrieren.
Weitere Optimierungsprobleme
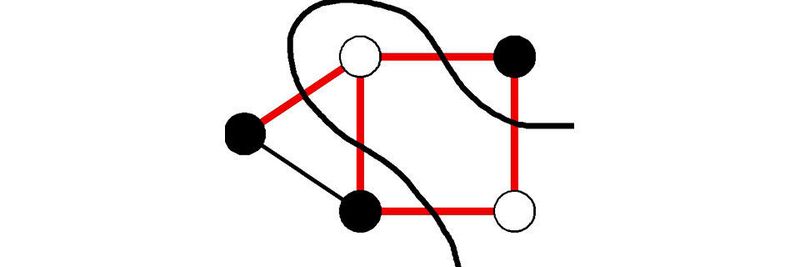
In der theoretischen Informatik gibt es mehrere Optimierungsprobleme. So wird etwa nach einem Algorithmus gesucht, der hinsichtlich des Metric-Traveling-Salesman-Problems (TSP) den „1,5-Approximationsalgorithmus“ von Christofides übertrifft. Siehe dazu den ersten Teil über das TSP-Problem. Das TSP-Problem spielt überall in der Logistik eine bedeutende Rolle. Ein weiteres Beispiel ist der Algorithmus für „Maximalen Schnitt“. Dieser Algorithmus löst ein theoretisches Graphen-Problem mithilfe von hochdimensionaler Geometrie (siehe Anblaufbild).
:quality(80)/images.vogel.de/vogelonline/bdb/1396700/1396763/original.jpg "2013 führte der US-Paketdienst UPS das Navigationssystem ORION ein (On-Road Integrated Optimization and Navigation) ein. Dieses berücksichtigt garantierte Lieferfristen für einzelne Pakete, angemeldete Abholungen und spezielle Kundenklassen mit bevorzugter Bedienung sowie Daten aus dem Verkehrsfluss in Echtzeit. (UPS)")
Grundlagen Statistik & Algorithmen, Teil 1
Das Problem des Handlungsreisenden und seine praktischen Anwendungen
Ein einfaches Beispiel für einen Approximationsalgorithmus ist die Lösung für das Minimum-Vertex-Cover-Problem, wobei Vertex ein Begriff aus der Graphentheorie sein kann, der einen Knoten bezeichnet. Dabei gibt es erstaunlicherweise einen konstant großen Faktor für den Approximationsalgorithmus, nämlich genau 2. Berücksichtigt man die Vermutung für einzigartige Spiele (Unique Games Conjecture), dann ist dieser Faktor sogar der bestmögliche. Die Graphentheorie wird auf alle Arten von vernetzten Beziehungen angewandt, so etwa in sozialen Netzwerken wie Facebook.
:quality(80)/images.vogel.de/vogelonline/bdb/1404000/1404092/original.jpg "Illustration des Satzes von Bayes durch Überlagerung der beiden ihm zugrundeliegenden Entscheidungsbäume bzw. Baumdiagramme. (Qniemiec / CC BY-SA 3.0)")
Grundlagen Statistik & Algorithmen, Teil 2
So verfeinert das Bayes-Theorem Spam-Filter – und mehr
Güte von Approximationsalgorithmen
Um die Optimierung beurteilen und verwalten zu können, muss der Nutzer herausfinden, was sein Approximationsalgorithmus überhaupt taugt. Das herauszufinden, ist kein Hexenwerk. Man muss nur ein paar Faktoren und Variablen formulieren und in den Algorithmus einsetzen.
Es sei S ( I ) die zu einer Eingabe I gehörige Menge zulässiger Lösungen. Zu jeder möglichen Lösung y ∈ S ( I )\ in S(I) sei v ( y ) der Wert der Zielfunktion für y. Der Zielfunktionswert einer optimalen Lösung für Eingabe I sei v *. Ein Approximationsalgorithmus (oder Approximationsverfahren) gibt bei Eingabe I eine Lösung y ∈ S aus, sodass (v ( y ) relativ nah an v * liegt.
Ist die von einem Approximationsverfahren für die Eingabe berechnete Lösung, so ist die Güte des Approximationsverfahrens bei der Eingabe
- bei Maximierungsaufgaben als r l = v * v ( y ) frac {v^{*}}{v(y)}}} und bei
- Minimierungsaufgaben als r l = v ( y ) v * frac {v(y)}{v^{*}}}} definiert.
Es ist also immer r l ≥ 1. Gilt r l = 1, liefert der Algorithmus eine optimale Lösung für I .
Hat ein Approximationsverfahren für alle möglichen Eingaben I eine Güte von r l höchstens α, so spricht man von einer α-Approximation.
:quality(80)/images.vogel.de/vogelonline/bdb/1409900/1409917/original.jpg "Prinzipbild des Rete-Algorithmus. Deutlich sind zwei Netzwerke (Alpha, Beta) zu erkennen und dass darin jeweils sehr viel Speicher benötigt wird. Dieser hohe Speicherbedarf ist einer der wenigen Nachteile des Rete-Algorithmus. (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 3
Speed für Mustererkennung mit dem Rete-Algorithmus
Klassen von Approximationsalgorithmen
Optimierungsprobleme werden in der Theoretischen Informatik in verschiedene Approximationsklassen unterschieden, je nachdem welcher Grad an Approximation möglich ist:
1. APX
Die Abkürzung APX steht für „approximable“ und deutet an, dass das Optimierungsproblem, zumindest bis zu einem gewissen Grad, effizient approximierbar ist. Ein Problem liegt innerhalb der Klasse APX, wenn eine Zahl r und ein polynomieller Algorithmus, der bei jeder zulässigen Eingabe I eine Lösung mit einer Güte ≤ r liefert, existieren.
2. PTAS/PAS
PTAS oder PAS steht für „polynomial time approximation scheme“. Anders als bei der Klasse APX wird hier für jedes δ ∈ ( 0 , 1) gefordert, dass ein polynomieller Algorithmus existiert, der bei jeder zulässigen Eingabe eine Lösung mit einer Güte r ≤ 1 + δ liefert. Der Algorithmus muss also nicht nur für eine bestimmte Güte, sondern für jede Approximationsgüte (s. o.) effizient sein.
3. FPTAS
FPTAS steht für „fully polynomial time approximation scheme“. Hier wird gefordert, dass sich der Algorithmus nicht nur polynomiell zur Eingabe, sondern auch zur Güte der Approximation verhält; Dass er also zu jeder Eingabe I und jedem k ∈ N eine Lösung mit der Güte r ≤ 1 + 1 / k ausgibt und seine Laufzeit polynomiell in x und k ist.
Es gilt: P O ⊆ F P T A S ⊆ P T A S ⊆ A P X ⊆ N P O .
:quality(80)/images.vogel.de/vogelonline/bdb/1430600/1430659/original.jpg "Der monegassische Stadtbezirk Monte-Carlo (© Noppasinw - stock.adobe.com)")
Grundlagen Statistik & Algorithmen, Teil 4
Der Monte-Carlo-Algorithmus und -Simulationen
Unter der Annahme P ≠ N P sind die obigen Inklusionsabbildungen echte Inklusionen. Das heißt, es gibt zum Beispiel mindestens ein Optimierungsproblem, das in der Klasse PTAS liegt, aber nicht in der Klasse FPTAS. Unter dieser Annahme existiert auch mindestens ein Optimierungsproblem, das nicht in APX liegt.
FPTAS-Beispiel: das Cliquenproblem
Das oben Gesagte lässt sich unter der Annahme P ⊊ N P zum Beispiel für das Cliquenproblem zeigen. Dieses Entscheidungsproblem der Graphentheorie liefert seit rund fünfzig Jahren zahlreiche interessante Lösungen.
Eine Clique bezeichnet in der Graphentheorie eine Teilmenge von Knoten in einem ungerichteten Graphen, bei der jedes Knotenpaar durch eine Kante verbunden ist. Zu entscheiden, ob ein Graph eine Clique einer bestimmten Mindestgröße enthält, wird „Cliquenproblem“ genannt und gilt, wie das Finden von größten Cliquen, als algorithmisch schwierig.
:quality(80)/images.vogel.de/vogelonline/bdb/1481900/1481934/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Grundlagen Statistik & Algorithmen, Teil 5
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
Es ist gefragt, ob es zu einem einfachen Graphen G und einer Zahl n eine Clique der Mindestgröße n in G gibt; das heißt, ob G zumindest n Knoten hat, die alle untereinander paarweise verbunden sind. Das Optimierungsproblem fragt nach der Cliquenzahl eines Graphen: Wie viele kann er enthalten?
Das zugehörige Suchproblem fragt nach einer größten Clique. Eine größte Clique lässt sich unter bestimmten Bedingungen in polynomieller Zeit berechnen, dauert also nicht ewig. Die Berechnung einer maximalen Clique gelingt bereits mit einem einfachen Greedy-Algorithmus. Dieser wird Gegenstand eines weiteren Grundlagenartikels sein.
:quality(80)/images.vogel.de/vogelonline/bdb/1509200/1509209/original.jpg "Ereigniszeitanalyse mit zensierten Daten für die Vertriebsabteilung: die Überlebensfunktion für Vertriebstechniker (durchgezogene Linie) und für Vertreter (gestrichelte Linie) in einem Kaplan-Meier-Schätzer. Vertriebstechniker sind ihrer Stelle wesentlich stärker und länger treu als Vertreter. Der blaue und rötliche Hintergrund deckt sich mit der jeweiligen Kurve. (SAS)")
Grundlagen Statistik & Algorithmen, Teil 6
Die Ereigniszeitanalyse – wenn Anfang und Ende die Erfolgsrate bestimmen
„BI-Systeme sind noch weitgehend frei von Approximationsalgorithmen“, befindet Benjamin Aunkofer. „BI-Systeme bestehen heute noch im Wesentlichen aus Data Warehousing (= saubere Datenbereitstellung) und Dashboarding (= Nutzung dieser Daten via Standard Reporting). Zukünftig werden BI-Systeme aber vermehrt Predictive Analytics aufnehmen.“
:quality(80)/images.vogel.de/vogelonline/bdb/1524900/1524972/original.jpg "Kernidee von LOF ist, die lokale Dichte eines Punktes mit der seiner Nachbarn zu vergleichen- (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 7
So deckt der Local Outlier Factor Anomalien auf
(ID:45946450)
:quality(80)/p7i.vogel.de/wcms/47/5d/475d2f9a48c8105e4f8313df086bfaae/0125406873v1.jpeg "Der Autor: Alexander Zschaler ist Regional Vice President DACH, Zentral- und Osteuropa bei Fivetran (Bild: Fivetran)")
:quality(80)/p7i.vogel.de/wcms/ee/8a/ee8a359384204f8d71dc150a22edd9f5/0127740604v1.jpeg "Der Autor: Steve Kearns ist VP of Product Management bei Elastic (Bild: Elastic)")