
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Big Data und Virtual Data Warehouse Das Virtual Data Warehouse verhilft zur schnelleren digitalen Transformation
Das traditionelle Data Warehouse ist auf die Verarbeitung strukturierter Daten ausgelegt, welche es effizient und performant erledigt. Doch Big Data besteht aus unstrukturierten Daten, Datenströmen, die in großen Mengen und mit hoher Geschwindigkeit eintreffen. Um Leistung und Effizienz zu erhalten, aber Flexibilität hinzuzugewinnen, bietet das Virtual Data Warehouse eine vielversprechende Alternative.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
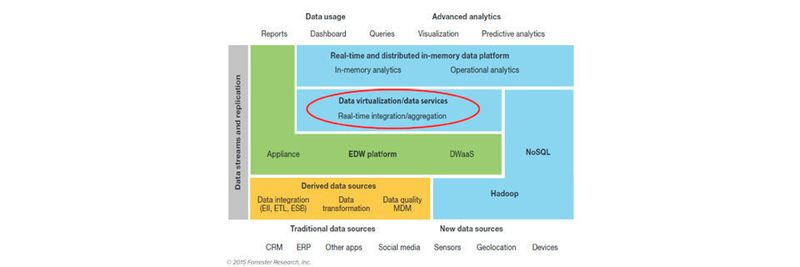
Innerhalb einer traditionellen BI-Architektur spielt das Data Warehouse bislang eine zentrale Rolle, wenn die Aufgabe im Vordergrund steht, eine 360-Grad-Sicht auf den Kunden sowie eine konsolidierte Datenhaltung mit ausgeprägten ETL-Datenprozessen zur Verfügung zu stellen. Seit 2014 findet die Vorstellung des Virtual oder Logical Data Warehouse (VDW, LDW) zunehmend Anhänger und Nutzer.
Die moderne, bimodale IT- und BI-Architektur, wie sie vor allem die Gartner Group beschreibt, erlaubt die Realisierung von Entitäten traditioneller BI wie etwa Reports oder Dashboards wie auch die Integration von Kombinationen aus BI-Anwendungen mit Big Data Analytics, wie sie etwa in Data Mining, Text Mining oder Machine Learning vorzufinden sind.
:quality(80)/images.vogel.de/vogelonline/bdb/1245000/1245055/original.jpg "(Rick van der Lans)")
:quality(80)/images.vogel.de/vogelonline/bdb/1245000/1245056/original.jpg "(Rick van der Lans)")
:quality(80)/images.vogel.de/vogelonline/bdb/1245000/1245057/original.jpg "(Rick van der Lans)")
:quality(80)/images.vogel.de/vogelonline/bdb/1245000/1245058/original.jpg "(Forrester Research)")
Dadurch sind bestimmte Fachbereiche des Unternehmens in der Lage, sowohl historische Daten etwa aus einem Hadoop-Cluster oder Data Warehouse, als auch Echtzeitdaten aus Sensorik, Cloud, Mobile oder Fertigung miteinander zu integrieren und einer zeitnahen oder gründlichen Analyse zuzuführen. Diese Analyse lässt sich unter Einsatz von Machine Learning beschleunigen und individuell anpassen.
Abstraktion von Datenquellen
Den Kern eines virtuellen oder logischen Data Warehouses bildet die Virtualisierung respektive Abstraktion von Datenquellen auf einer entsprechenden Server-Plattform (nicht zuletzt auch in der Cloud). Die Virtualisierung von Datenquellen abstrahiert die zahlreichen, unterschiedlichen und meist verteilten Datenquellen durch eine integrierende Schicht von semantischen Metadaten und Logik.
Auf diese semantische Schicht, die in einem Repository abgelegt ist, beziehen sich künftig alle Anwendungen und Services als gemeinsamen Nenner. Die Datenvirtualisierungsplattform stellt verschiedenen Nutzern Metadaten und den Zugriff auf jegliche Datenquellen bereit, orchestriert diese Zugriffe und optimiert gleichzeitig die Performance der Abfragen und sonstigen Operationen auf den virtualisierten Datenbeständen.
Das Virtual oder Logical Data Warehouse dient der Self-Service BI, der Erstellung von Daten-Services für Applikationen zur Umsetzung datengetriebener Lösungen, aber auch von abgesicherten Sandboxes, wie sie etwa Entwickler benötigen. Durch die Virtualisierung der Datenquellen lassen sich nach Ansicht der Experten von Forrester, Gartner und anderen in wirtschaftlicher Hinsicht zahlreiche Vorteile erzielen. Agile Anwendungsentwicklung für Big Data Analytics und Business Analytics ist gleichermaßen möglich. So lässt sich auch die digitale Transformation im Hinblick auf IoT und ML auf den Weg bringen.
Es dürfte nicht verwundern, dass jeder Anbieter von BI-Technologie seine jeweils eigene Variante des Virtuellen Data Warehouse hat. Meist wird es überhaupt nicht so genannt, sondern unter ganz anderen Aspekten vermarktet. IBM nennt die zentrale Technik „Federation“, Informatica stellt seine Integrationsfunktionen im Produkt PowerCenter ins Zentrum, doch vor allem Denodo Technologies hat eine klare Vorstellung von einem VDW vermarktet. Die drei Varianten haben jedoch mehrere Komponenten gemeinsam: Entkopplung und Abstraktion, eine semantische Schicht, Datentransfer und Security. Ein nicht repräsentativer Vergleich soll diese Aspekte beleuchten.
IBM InfoSphere Federation Server v10.5
Der Federation Server weist zahlreiche Merkmale eines VDW auf. Auf Basis der relationalen Datenbank DB2 verarbeitet der Server die Abfragesprache SQL. Daher können BI-Nutzer von DB2 aus verteilte SQL-Skripte in die Quellsysteme verschicken, etwa Microsoft SQL Server oder Oracle. Diese Push-down-Skripte können Selektionen, etwa um ausgewählte Zeiträume miteinander zu vergleichen, und Joins enthalten. Joins koppeln Tabellen und Datensätze, ja, sogar einzelne Felder miteinander und führen darauf eine Operation aus. Die Joins werden im Federation Server von der DB2-Datenbank-Funktionalität übernommen, die auch den Query Optimizer umfasst, der für die Performance einer SQL-Abfrage in den Quellsystemen von hoher Bedeutung ist.
Nun ergibt sich der Sinn der Entkopplung: Die zu den jeweiligen Datenquellen geschickten Teil-SQL-Statements liefern lediglich die benötigten Selektionsdaten zurück, nicht aber komplette Tabellen. Mit dem eng verwandten Produkt Big SQL kann man auf Hadoop etc. zugreifen, etwa um einen Data Lake in Hadoop mit SQL, das auch Spark SQL beinhalten kann, abzufragen. Auf diese Weise braucht kein BI-Nutzer mehr große Datenquellen zusammenzuführen.
Zumindest theoretisch, denn der IBM-Experte Harald Gröger berichtet: „Bei einem großen deutschen Industrieunternehmen wird ein Data Lake auf Basis Hadoop mit Kopien von SAP Daten betrieben, um SAP-Daten ohne Zusatzlast auf den SAP-Systemen analysieren zu können.“ Dass dabei doppelte Storage-Kapazität, erhöhte Netzwerkbelastung und doppelte Wartungsarbeit anfällt, nimmt das Unternehmen in Kauf. Andere Firmen wollen genau dies durch das VDW vermeiden.
Big SQL
Mit Big SQL, einem mit Federation Server eng verwandten Produkt, ist die SQL-basierte Analyse von Hadoop-, Hive- und Spark-Daten in einem Data Lake usw. realisierbar. „Will man etwa Echtzeitdaten aus Wetter-Servern oder Social Media einbinden, könnten diese im JSON-Format in Hadoop gespeichert und dann für Big SQL zugreifbar gemacht werden“, erläutert Gröger. Die Performance lässt sich durch Caching bzw. Buffering in DB2 erhöhen. Kritisch sind laut Gröger die Updates dieses Speicherpuffers, etwa wenn es um Echtzeitdaten geht.
Was nun die Entwicklungsarbeit und BI-Abfrage stark vereinfacht, sind die Views. Diese Sichten basieren auf den Metadaten, die im DB2 Catalog verwaltet werden. Ändern sich die Basisdaten, ändern sich auch die Daten, die eine Sicht anzeigt. Folglich sind Views stets aktuell. Ihre Inhalte kann jeder BI-Nutzer nach seinen Wünschen – etwa für Dashboards – nutzen.“ Views werden indes von den DB-Admins definiert und können nicht von BI-Nutzern geändert werden. Sollen weitere Apps erstellt werden, stellt der IBM Information Services Director, ein Bestandteil von IBM InfoSphere Information Server, entsprechende APIs bereit. Dieses Produkt erlaubt die Kapselung von Federation, ETL-Prozesse und die Datenqualitätsbereinigung als Web Services.
Security und Datenschutz
Ab Mai 2018 wird durch die Europäische Datengrundschutzverordnung (DSGVO alias GDPR) die technische Fähigkeit zu Löschung von Nutzerdaten bei jedem Unternehmen Pflicht, das Kundendaten verarbeitet. Also muss auch ein VDW selektiv Daten löschen bzw. verbergen können. Dies lässt sich mit der Federation Server Security realisieren, etwa durch die Einschränkung der Sichtbarkeit von (Teil-) Daten in Tabellen mithilfe von Label Based Access Control. „Über Benutzerrechte lässt sich der Datenzugriff sowohl im Federation Server als auch in BigSQL für Hadoop-Daten feingranular einschränken“, so Gröger.
Das selektive Löschen von Daten dürfte mit SQL wohl kein Problem sein, aber wie sieht es etwa mit Verschlüsselung von Kundendaten aus? Harald Gröger versichert, dass über Big SQL auch die Hadoop Transparent Data Encryption unterstützt wird.“
Denodo Platform v6.0
Der Softwarehersteller Denodo Technologies wurde bereits 2002 gegründet, die aktuelle Version 6.0 seiner VDW-Plattform wurde im März 2016 veröffentlicht. Die VDW-Plattform erschließt dem BI- und Enterprise-Architekten eine breite Palette von Datenquellen und -formaten, wobei sie zahlreiche Programmiersprachen und Programmierschnittstellen (APIs) unterstützt.
Das erweiterte relationale Datenmodell, das intern unterstützt wird, soll es erlauben, auch nicht-relationale Datenstrukturen auf effiziente Weise zu verarbeiten. Die Konnektivität dieses Servers erstreckt sich daher auch auf Big-Data-Quellen wie Amazon Redshift, Cloudera Impala und Apache Spark.
Die Plattform unterstützt komplexe Datentypen wie etwa XML, JSON, Key-Value-Pairs und sogar SAP-BAPIs (Business Application Programming Interfaces), im Datenmodell selbst sowie in der Bereitstellung von Webservices. Denodo reklamiert für sich, damit das breiteste Angebot an Konnektoren und Publishing-Methoden am Markt zu bieten. Zudem lässt sich Denodo 6.0 auch auf Amazon AWS in der Cloud nutzen, ähnlich wie die Produkte von IBM.
Bei der Optimierung von Queries hinsichtlich Kosten und Performance arbeitet der dynamische Query Optimizer auch kostenbasiert. Mithilfe von statistischen Methoden berechnet der Optimizer den kostengünstigsten und performantesten Ausführungsplan für die jeweilige Abfrage. Dabei bezieht der Optimizer spezielle Charakteristika von Big Data ein, wozu unter anderem Anzahl von Verarbeitungseinheiten (Prozessoren) und Partitionen auf Speichergeräten gehören. Während er eine beliebige Anzahl von inkrementellen Abfragen handhaben kann, lässt sich dieses Workload-Management mit einem spezifischen Workload Manager noch verfeinern.
Das VDW, das sich damit erstellen und betreiben lässt, unterstützt Data Scientists und Admins dabei, logische und semantische Business Views zu generieren, zum Beispiel im Zuge von Data Discovery und Data Profiling. Unter dem Aspekt der Datensicherung bietet das VDW zudem Schutzmechanismen für Autorisierung und Authentifizierung. Die Belange von Compliance (siehe DSGVO) und Governance sind ebenfalls berücksichtigt.
Informatica PowerCenter & Intelligent Data Platform
Informatica bietet weltweit über 7.000 Kunden eine erprobte, stabile Integrationsplattform an: die Informatica Intelligent Data Platform. Durch Universalzugriffstechnologie kann damit nahezu jeder Datentyp verarbeitet und durch ETL-Prozesse an die Wünsche des Nutzers angepasst werden. Der Zugriff ist durch native APIs performant und die Datenmenge fast beliebig skalierbar.
„Die Technologie bietet auch Funktionalität zur Virtualisierung von Datenquellen, kann aber auch mit externen virtuellen Datenquellen arbeiten“, erläutert Frank Waldenburger, Director Sales Consulting bei Informatica Central EMEA. „In Richtung der Datenverbraucher gibt es darüber hinaus den sogenannten Data Integration Hub (DIH). Diese Technologie arbeitet nach dem Publish & Subscribe-Prinzip und kann Daten als eine Art Abonnement aus allen angeschlossenen Datenlieferanten aufbereiten und bereitstellen.“ Das bedeute das Ende der Punkt-zu-Punkt-Verbindungen der traditionellen Datenintegration durch Entkoppelung, so der Hersteller. Das ist genau der Sinn der Datenvirtualisierung.
Durch die nativen APIs lassen sich Abfrage- und ETL-Funktionen direkt auf Hadoop ausführen, sodass auf Wunsch nur die Resultate dieser Operationen geliefert werden. „Generell“, so Waldenburger, „besteht immer die Möglichkeit, die für die Extraktion aus Datenbankobjekten generierten SQL-Statements anzupassen, also auch hinsichtlich der Performance zu optimieren.“
Die Version Big Data Integration Hub unterstützt Hadoop-Repositorys wie etwa von Cloudera oder Hortonworks. Der Hub abstrahiert die Komplexität des Speicherns und Verwaltens roher und bearbeiteter Datenmengen in einem Hadoop-Data-Lake oder -Hub. Das DIH indiziert alle in Spark, Hadoop oder Hive gespeicherten Daten, um so die Daten zugänglich und für Analysewerkzeuge und andere Apps abfragbar zu machen.
Zur Nutzung großer Datenmengen auf Hadoop, Hive, Cloudera und weiteren stellt Informatica neben dem DIH auch den Enterprise Information Catalog (EIC) bereit. Der Katalog erlaubt die Erfassung sämtlicher Datentypen im Unternehmen, die semantische Suche und das Entdecken der Abstammung und Beziehungen der Informationen. Datenbestände lassen sich mit Geschäftskontext anreichern und sogar mit Crowdsourcing-Tags versehen. Der EIC ist auf Big-Data-Bereitstellungen etwa in Hadoop-Clustern ausgelegt. Die parallele Metadatenaufnahme und die schnelle verteilte Indexierung ermöglichen eine zeitnahe Aktualisierung der Kataloginhalte und eine gesteigerte Such-Performance, so der Hersteller.
Resümee
Umfangreiche Datenübertragungen, um Analysen auszuführen, sollten heute der Vergangenheit angehören: Die Daten bleiben idealerweise in den Quellsystemen, wo entsprechende Skripte die nötigen Selektionen, Transformationen usw. erledigen, statt in einem Data Lake unbehandelt abgelegt zu werden.
Dass das Virtual Data Warehouse als Plattform für die Datenintegration, für Self-Service BI und moderne BI-Apps eine vielversprechende Zukunft hat, belegt die wachsende Zahl von Kunden, die es – unter dieser oder jener Bezeichnung – nutzen: Autodesk, Swiss Re, Electronics Arts, deutsche Industrieunternehmen.
Wie vielfältig die Ausprägungen (noch) sind, konnte hoffentlich diese kleine Auswahl belegen. Sie sollte zeigen, auf welche Funktion und Leistungsmerkmale der Interessent achten sollte, wenn er solch eine Lösung in Betracht zieht. Im Mittelpunkt der Überlegungen sollte die effiziente, kostengünstige und gesetzeskonforme Bewirtschaftung von Massendaten stehen.
(ID:44746120)
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")