
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/b3/d4b39c1c2d46f3ae6e49ed80f2ecd9d1/0132006976v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/e2/bae2c84df6310701a01325e9fbfd96d6/0132099756v1.jpeg "Simon Ritter, Deputy CTO bei Azul, warnt: Vibe Coding produziere Code, der tue, was das Modell verstanden habe – nicht, was gemeint war. (Bild: Azul)")
:quality(80)/p7i.vogel.de/wcms/b5/f4/b5f489601994978d1730f20e206002f7/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Evolution Der Übergang von Business Intelligence zu Advanced Analytics
Wenn einem BI-Nutzer Reports und Dashboards nicht mehr reichen, wird es Zeit für Prognose-Tools, die in den Disziplinen Advanced Analytics (AA) und Data Science zu finden sind. Doch AA-Modelle sind nur von begrenztem Wert, wenn man sie nicht in die Prozesse integriert. Wie der Übergang von BI zu AA gelingen kann, zeigt ein Webinar von BARC-Experte Timm Grosser.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
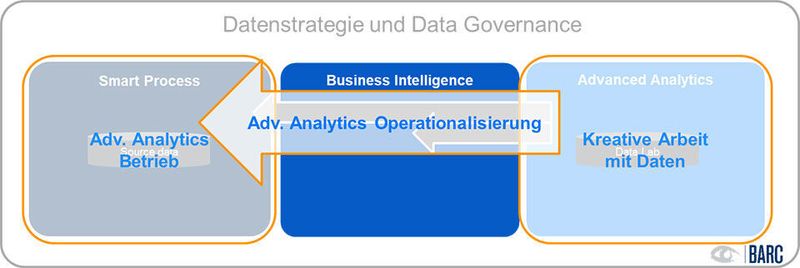
Mit Reports und Dashboards schaut ein BI-Nutzer quasi in einen Rückspiegel: Er sieht, was bereits geschehen ist. Diese Einsichten und Berichte liefert das Data Warehouse, das sie in industrialisiertem Maße kostenoptimiert bereitstellt. Discovery-Werkzeuge wie Qlik oder Tableau ermöglichen das Aufspüren weitergehender Trends, insbesondere aus unstrukturierten Daten, die in zusätzlichen Datenspeichern, etwa in Data Lakes, gesammelt werden.
Allerdings wollen Nutzer aufgrund dieser Einblicke auch planen und handeln, etwa um Einsparpotenziale auszunutzen oder Wettbewerbsvorteile zu erzielen. Timm Grosser, Senior Analyst Data & Analytics beim BARC-Institut, sieht die Kluft zwischen Erkenntnisgewinn und dem Handeln als die Kluft zwischen Labor und tatsächlicher Anwendung in den operativen Systemen. Denn erst die Anwendung der Erkenntnisse in den Prozessen führe zu Nutzen aus Daten wie etwa Chancen zur Automatisierung, schnellere und umfangreichere Kundenbetreuung durch mehr Daten und Wissen über Kunden. Nun gelte es, sie mit Einsichten in Echtzeit zu unterfüttern. Grosser nennt das Anwenden der Erkenntnisse auf Aktionen die „Operationalisierung“ von BI und Analytics.
Advanced Analytics
Ein Data Warehouse arbeitet sehr effizient, wenn es strukturierte Daten verarbeiten kann, die etwa aus relationalen Datenbanken und aus SQL-Abfragen kommen. Doch die Welt bleibt nicht stehen, sondern liefert Massen von semi- bzw. unstrukturierten Daten, die für das Unternehmen wertvoll sein können, weil sie von den Kunden und aus der realen Umgebung kommen: Weblogs, Texte aller Art, Standortdaten, menschengenerierte Daten, aber auch maschinengenerierte Daten aus Sensoren, Endgeräten, Fahrzeugen und vielem mehr. Um sie zu verarbeiten, wird neben dem Data Warehouse häufig ein Data Lake angelegt, der aber bewirtschaftet werden sollte. Dieser ist in der Regel speziell für die Datenspeicherung in einem Data Lab konzipiert, um Advanced Analytics zu unterstützen.
Das Datenlabor
Das Data Lab arbeitet im Unterschied zum Data Warehouse wertorientiert. Oberstes Ziel ist es, Wert aus Daten zu generieren. Dafür sind im Gegensatz zum Data Warehouse andere Ansätze notwendig, um den Wert in den Daten überhaupt entdecken und erforschen zu können. In welche Richtung geforscht wird, legen meist die Unternehmensleitung oder ihre Fachbereiche fest. So können Informationen interessant sein, die eine Bestellhistorie und einen Standort umfassen, um einem Kunden eine Kaufempfehlung in Echtzeit auf sein Handy zu schicken: ein neuer Prozess, um Wertschöpfung zu generieren.
Das Data Lab liefert also neue Einsichten. Diese stehen im Vorfeld – im Gegensatz zu einer konkret berechneten Kennzahl (KPI) in einem Data Warehouse – noch nicht fest. Um diese zu erkunden, bedarf es Freiräume und neuer Methoden, wie etwa das Versuch-und-Irrtum-Verfahren, explorative Analysen sowie Iterationen, um aussagekräftigere Ergebnisse zu erhalten. Daher muss das Data Lab sehr agil und flexibel aufgebaut sein, was sich in den AA-Tools widerspiegeln sollte.
Neue Kombination
Nach Ansicht von Timm Grosser erlaubt die Kombination von AA-basiertem Data Lab, der DW-basierten Info-Factory und der operativen Prozesse neue Anwendungsfälle und Einsatzbereiche, etwa im Internet der Dinge. Dazu gehört etwa Predictive Maintenance und die Optimierung von Service- und Produktqualität. Diese Use Cases sind datengetrieben. Sie laufen systemübergreifend ab, was einen Umbau der IT-Infrastruktur und/oder die Erweiterung der Integrationstechnologien erforderlich machen kann. Zudem müssen die Use Cases auf einer skalierbaren IT-Infrastruktur aufbauen, damit auch Spitzen wie etwa im Weihnachtsgeschäft oder am Cyber Monday noch Bestellungen verarbeitet werden können.
Neue Strategie
Um die Anwendungsfälle realisieren zu können, ist eine neue oder erweiterte Strategie des Unternehmen angebracht: Wenn das Data Lab neue Einsichten liefert, ist für ihre rechtzeitige Integration in Prozesse Flexibilität nötig. Dafür braucht es einen Leitfaden, da hier unterschiedliche Bereiche mit ihren eigenen Systemen, Methoden, Systemen und mehr aufeinandertreffen. Eine Strategie wird benötigt, die übergreifend die Aktivitäten steuert, um aufgrund von Daten im Sinne der Geschäftssteuerung handeln zu können.
Die bewusste Steuerung und Planung von Daten im Sinne der Geschäftsstrategie ist eine Datenstrategie. Eines der Instrumente zur Umsetzung einer Datenstrategie ist die Data Governance. Eine Data Governance sieht Rollen vor, die helfen, die Voraussetzungen für die Kollaboration zwischen den Bereichen zu schaffen, welche die Data- und Analytics-Kompetenz treiben sowie die Erstellung und Verwendung von Daten steuern helfen. Kollaborationswerkzeuge ergänzen die Operationalisierung auf der organisatorischen Ebene.
Produzenten und Verbraucher
Das datengetriebene Unternehmen besteht aus zwei Mega-Rollen. Auf der einen Seite stehen die Datenproduzenten wie etwa Prozesseigner in Fachbereichen. Sie erzeugen Daten sowie die dazugehörigen Metadaten. Metadaten beschreiben Daten. Aus ihnen ziehen Nutzer Wissen über Daten. Dieses Wissen kann in einem Repository oder Data Catalog gespeichert werden, um es auffindbar und verfügbar zu machen.
Auf der anderen Seite stehen die Datenkonsumenten, die eigentlichen Datennutzer. Sie benötigen Wissen über Daten (Metadaten), um Daten verstehen, beurteilen und richtig anwenden zu können. Aufbereitet und ausgewertet werden die Daten von analytischen Rollen wie etwa Data Engineers, Data Scientists, Power Usern oder Business-Analysten. Sie benötigen einerseits Metadaten zur Aufbereitung und Analyse. Auf der anderen Seite stellen sie ebenfalls Metadaten bereit: Informationen zu Metriken (KPIs) und Modelle für Analysen und Vorhersagen, etwa für Predictive Maintenance.
Datenkatalog
Ein Data Catalog verwaltet Daten nicht nur übersichtlich, sondern stellt die „Gelben Seiten“ der unternehmensrelevanten Daten für alle Nutzer im Unternehmen dar. Er konsolidiert das Wissen über Daten aus den Systemen und bietet eine Plattform, um technisches Wissen mit fachlichem und organisatorischem Wissen anzureichern, etwa indem er technische Tabellen mit Fachbegriffen verknüpft und um die verantwortlichen Ansprechpartner erweitert.
Generischer Ablauf für Advanced Analytics
Um wirklich Nutzen aus der AA-Nutzung zu ziehen, sollte auch die Implementierung einem Plan folgen, der die notwendige Operationalisierung von Einsichten ermöglicht und fördert.
Wesentlich ist laut Grosser Folgendes:
Es gibt eigentlich drei wesentliche Komponenten im Ablauf:
- 1. Kreative Arbeit mit Daten und Generierung von Modellen
- 2. Die Überführung der Erkenntnisse (der Modelle) in den operativen Betrieb (Operationalisierung)
- 3. Der operative Betrieb der Modelle
Phase 1: Zu den Aufgaben gehört es, Daten anzuzapfen, aufzubereiten, zu analysieren und zu modellieren sowie zu validieren, mit der Zielsetzung der Erstellung eines Minimum Viable Product (MVP).
Phase 2 umfasst die Überführung dieses Modells in den operativen Betrieb. Dafür braucht der Nutzer eine Vorstellung, wie dieses entdeckte Modell fachlich und technisch zu integrieren ist. Er muss sich also Gedanken dazu machen, in welchen Anwendungsfällen das Modell unterstützend wirken kann (d. h., in welchen Prozessen für einen profitablen Business Case).Wie sind die Prozesse anzupassen (organisatorisch, technisch), damit das Modell implementiert werden kann? In welchen Schritten muss der Nutzer hier vorgehen und wie muss er dies technisch gestalten. Das Ergebnis unterliegt einem Integrationstest: „Kommt am Ende des Tages auch das Richtige raus?“
Phase 3 umfasst zunächst das Monitoring: Läuft das erstellte AA-Modell wie vorgesehen? Bekommt es die richtigen Daten, generiert es die richtigen Daten? Es gilt nachzuprüfen, ob der Output noch gut genug ist, denn schließlich ändern sich Daten mit der Zeit. Schließlich sind Optimierung bzw. Retraining des Modells nötig, also die regelmäßige Kontrolle und Anpassung des Modells, damit es valide bleibt.
Anforderungen an eine AA-Lösung

Die Anforderungen an eine Technologieplattform für ganzheitliche AA-Lösungen umfassen also das Data Lab (zwecks Datenerfassung und -modellierung), die Operationalisierung von AA überall im System, interdisziplinäre Kollaboration, den Betrieb der AA-Analytik und last, but not least, die Berücksichtigung von Data Governance, Compliance und Regulatorik sowie die Sicherstellung der Datenqualität.
Zu den Trends zählt der BARC-Experte die Unterstützung der BI-Nutzer durch Self-Service, KI und NLP-Sprachunterstützung. Beim Datenmanagement werden zunehmend auch Standortdaten integriert, etwa für Location Intelligence. Einen weiteren Trend sieht Grosser in der Erweiterung und Modernisierung der Datenarchitektur, etwa durch Data Lakes. Die Erstellung entsprechender Apps war nicht Schwerpunkt seines Webinars.
Die intensive Nutzung von Künstlicher Intelligenz und Machine Learning ermöglicht seiner Ansicht nach die Verkürzung und Optimierung von datengetriebenen Prozessen durch Automation, die Aus- und Verwertung von Data Catalog-Metadaten (etwa durch das zeitintensive Tagging und Verschlagworten) sowie die Unterstützung der Nutzer wie durch Nutzerführung. Wie etwa Salesforce gezeigt hat, lassen sich Machine-Learning- und NLP-Funktionen in zahlreiche Anwendungen der Fachbereiche nahtlos integrieren, um die Mitarbeiter produktiver zu machen.
Artikelfiles und Artikellinks
(ID:46498960)
:quality(80)/p7i.vogel.de/wcms/3f/cb/3fcbdf71036cdeb2dacc68c100bfa5db/0131917207v1.jpeg "Die Datenbank-Inseln laut Databricks (Bild: Dr. Dietmar Müller)")
:quality(80)/p7i.vogel.de/wcms/2f/ba/2fba02f0b161655c2df58a7ce4dd6557/0127367593v1.jpeg "Viele KI-Initiativen scheitern an unzureichender Datenbasis. Wie Data Culture, Governance und moderne Architektur eine verlässliche Grundlage für KI-Mehrwert schaffen. (Bild: Midjourney / KI-generiert)")