
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/a9/93/a993e3c30653815b51bc29f9a4b8c960/0131800037v1.jpeg "Bundesdigitalminister Dr. Karsten Wildberger ist laut seinem Ministerium davon überzeugt, dass Deutschland – auch in der Politik – schnell den produktiven und maßvollen Umgang mit KI lernen muss. (Bild: BMDS/Woithe)")
:quality(80)/p7i.vogel.de/wcms/f2/06/f2068c07b75c64eb0f2f0379e195cfd6/0131791215v1.jpeg "Auszug aus den des von Google erzeugten KI-Zusammenfassungen, die zum Gegenstand der Verhandlungen wurden. (Bild: LG München I, Endurteil v. 28.05.2026 – 26 O 869/26)")
:quality(80)/p7i.vogel.de/wcms/5b/29/5b2978694f59bf125b6c84d053061adf/0131791809v1.jpeg "Auf seiner Hausmesse Transcend kündigt GitLab vier Funktionen an, die Geschwindigkeit, Kontext, Governance und Abrechnung beim Agenten-Einsatz adressieren sollen. (Bild: GitLab)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Künstliche Intelligenz mit Apache Spark Databricks erweitert Sparks KI-Fähigkeiten mit ML-Framework
Databricks, Entwickler und Betreuer der Analytics-Plattform Apache Spark, hat mit der Unified Analytics Platform ein neues Machine Learning Framework vorgestellt. Drei zusätzliche Spark-Funktionen sollen die Zusammenarbeit zwischen Datenbereitstellung und KI-Entwicklung plattformübergreifend performant machen
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
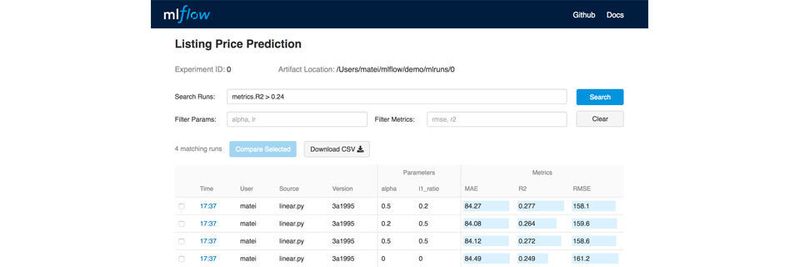
Die Unified Analytics Platform von Databricks soll ein Hauptproblem der KI-Entwicklung beheben, nämlich die Diskrepanz zwischen komplexem Datenmanagement einerseits und der über viele Plattformen verstreuten KI-Entwicklung andererseits.
Apache Spark verfügt von Haus aus über mächtige Machine-Learning-Fähigkeiten, mit denen sich vielfältige Algorithmen verwenden lassen. Doch ML-Modelle erfordern enorme Datenmengen, um zuverlässig zu arbeiten. Diese Datenmengen müssen gesäubert, konsolidiert und performant abrufbar sein. Doch nach Databricks' Erkenntnissen verschwenden die hochbezahlten Data Scientists die Hälfte ihrer Zeit darauf, eben diese Daten vorzubereiten und bereitzustellen. Dabei wäre das eigentlich die Aufgabe von Technikern.
Databricks MLflow
 und speichert Projekte in einem austauschbaren Format, damit sie reproduzierbare Ergebnisse liefern. Zudem lässt sich ein Modell in einem austauschbaren Format speichern, um sein Deployment auf einer anderen Plattform zu erleichtern.")
Um die Zusammenarbeit zwischen den Prozessen, Technologien und Plattformen der Techniker und Analytiker zu verbessern, dienen MLflow, Runtime for ML und Delta. MLflow ist ein quelloffenes Cloud-übergreifendes Framework, das den Ablauf einer Machine-Learning-Anwendung vereinfachen soll. Zum Ablauf gehört die Erstellung oder Selektion eines Algorithmus, die Schaffung eines Modells, die Inferenz der beiden Elemente aus umfangreichen Trainingsdaten und die Auswertung der Ergebnisse – und dies bitteschön in vielfacher Iteration in kürzester Zeit.
Der Code, den das KI-Team bereits erstellt hat und der den Workflow von Anfang bis Ende beschreibt, lässt sich mit MLflow in einem Austauschformat verpacken, damit dessen Ausführung auf anderen Plattformen wie etwa Tensorflow reproduzierbare Ergebnisse liefert, die sich vergleichen lassen. MLflow lässt sich mit Apache Spark, mit SciKit-Learn, mit TensorFlow und anderen quelloffenen ML-Frameworks wie etwa Keras integrieren. Auf welcher Hardware die einzelnen Programme laufen, erfährt man aus deren jeweiliger Dokumentation, aber Databricks erwähnt ausdrücklich auch die Unterstützung von MS Azure und AWS.
Databricks Runtime for ML
Je größer die Menge der Trainingsdaten, desto besser das Modell. Aber je komplexer die Daten, desto länger die Trainingsdauer. Diese Crux soll sich mit Databricks Runtime for ML beheben lassen. Vor allem die Komplexität soll sich durch vorkonfigurierte Betriebsumgebungen für die verbreitetsten Frameworks abfedern lassen: TensorFlow, Keras, xgboost und Scikit-Learn. Um den Bedarf an hohen Deep-Learning-Kapazitäten zu befriedigen, führt Databricks nun die Nutzung von GPUs (etwa von Nvidia) auf MS Azure und AWS ein. Dieser überfällige Schritt, den auch Hadoop kürzlich gegangen ist, verkürzt die Trainingszeiten um mehrere Größenordnungen.
Der Vorteil laut Databricks: Data Scientists können jetzt Modelle mit erheblichen Datenmengen füttern, verlässliche Ergebnisse evaluieren und fortschrittliche KI-Modelle auf nur einer vereinheitlichten „Maschine“ (lies: Unified Analytics Platform) bereitstellen und ausführen.
Databricks Delta
Um das eingangs erwähnte Problem des hohen Aufwands für die Datenvorbereitung zu bekämpfen, soll Databricks Delta die Datentechniker unterstützen. Sie erhalten durch das in Spark integrierte Delta-Modul hohe, skalierbare Performance, verlässliche Daten aufgrund transaktionaler Integrität sowie die niedrige Latenzzeit von Streaming-Systemen (Spark beherrscht Streaming von Beginn an). Der Fokus liegt also auf höherem Datendurchsatz, aber an der Datenqualität muss noch viel gearbeitet werden.
Die Unified Analytics Platform befindet sich im Alpha-Stadium, bekommt also noch viele weitere Komponenten. Man findet sie bereits auf Microsoft GitHub. Detaillierte Informationen zu allen Neuheiten und zur Produktplanung bietet dieser Blog.
Resümee
Die Lösung, die die drei Funktionen anbieten, ist quasi salomonisch. Einerseits erleichtern sie die Bereitstellung und Ausführung von Modell-Code per Austauschformat auf zahlreichen KI-Frameworks. Andererseits sollen sie darauf hinwirken, dass die Nutzer ihre ML-Workflows auf der Unified Analytics Platform zusammenführen und so die hinderlichen Silos beseitigen. Man kann Databricks nur die Daumen drücken, dass diese Lösung Anklang findet. Umgekehrt lässt sich aus der Notwendigkeit für diese Angebote ablesen, womit viele KI-Anwender derzeit noch kämpfen.
(ID:45360676)
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/3b/b8/3bb83fa0b3243f0f43e2b21eda68ce38/0125180669v1.jpeg "Databricks hat auf der Anwenderkonferenz Data + AI Summit 2025 unter anderem die beiden Produkte „AI Agent Bricks“ und „Lakeflow Designer“ vorgestellt. (Bild: GRANT TERZAKIS)")