
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Grundlagen Statistik & Algorithmen, Teil 7 So deckt der Local Outlier Factor Anomalien auf
Um Trends zu erkennen, wird oft die Clusteranalyse herangezogen. Der k-Means-Algorithmus etwa zeigt an, wo sich Analyseergebnisse in einer Normalverteilung ballen. Für manche Zwecke ist es aber aufschlussreicher, Ausreißer zu untersuchen, denn sie bilden die Antithese zum „Normalen“, etwa im Betrugswesen. Der Local-Outlier-Factor-Algorithmus (LOF) ist in der Lage, den Abstand von Ausreißern zu ihren Nachbarn zu berechnen und deckt so Anomalien auf.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
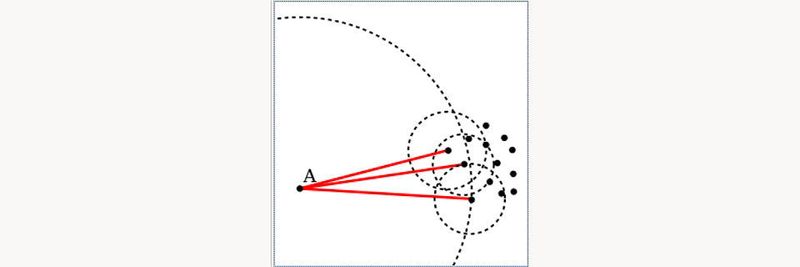
Bei der Clusteranalyse geht es darum, Gruppen von Objekten zu identifizieren, die sich auf eine gewisse Art ähnlicher sind als andere Gruppen. Oft handelt es sich dabei um Häufungen im Datenraum, woher der Begriff Cluster kommt.
In der Ausreißersuche werden Datenobjekte gesucht, die inkonsistent zu dem Rest der Daten sind, beispielsweise indem sie ungewöhnliche Attributswerte haben oder von einem generellen Trend abweichen. In der Statistik spricht man von einem Ausreißer, wenn ein Messwert oder Befund nicht in eine erwartete Messreihe passt oder allgemein nicht den Erwartungen entspricht. Die „Erwartung“ wird meistens als Streuungsbereich um den Erwartungswert herum definiert, in dem die meisten aller Messwerte zu liegen kommen, z. B. der Quartilabstand Q75 – Q25. Werte, die weiter als das 1,5-Fache des Quartilabstandes außerhalb dieses Intervalls liegen, werden – meist recht willkürlich – als Ausreißer bezeichnet.
Der Algorithmus „Local Outlier Factor“, der hier näher vorgestellt wird, sucht beispielsweise Objekte, die eine von ihren Nachbarn deutlich abweichende Dichte aufweisen, man spricht hier von „dichtebasierter Ausreißer-Erkennung“. Identifizierte Ausreißer werden oft anschließend manuell verifiziert und aus dem Datensatz ausgeblendet, da sie die Ergebnisse anderer Verfahren verschlechtern können. In manchen Anwendungsfällen, wie der Betrugserkennung, sind aber gerade die Ausreißer die interessanten Objekte.
, während D kein k-nächster Nachbar ist.")
Der Local Outlier Factor (etwa „Lokaler Ausreißerfaktor“) wurde von Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng und Jörg Sander im Jahr 2000 vorgeschlagen. Die Kernidee von LOF besteht darin, die Dichte eines Punktes mit den Dichten seiner Nachbarn zu vergleichen. Ein Punkt, der „dichter“ ist als seine Nachbarn, befindet sich in einem Cluster. Ein Punkt mit einer deutlich geringeren Dichte als seine Nachbarn ist hingegen ein Ausreißer.
LOF definiert die „lokale Umgebung“ eines Punktes über seine nächsten Nachbarn. Der Abstand zu diesen wird verwendet, um eine lokale Dichte zu schätzen. In einem zweiten Schritt wird der Quotient aus den lokalen Dichten seiner Nachbarn und der lokalen Dichte des Punktes selbst gebildet. Dieser Wert bewegt sich nahe an 1.0, wenn ein Punkt in einem Bereich gleichmäßiger Dichte ist. Für Objekte, die aber abgeschieden von einer solchen Fläche sind, wird der Wert deutlich größer – und kennzeichnet so Ausreißer.
Der „Local Outlier Factor“ ist also die „durchschnittliche Erreichbarkeitsdichte der Nachbarn“ dividiert durch die Erreichbarkeitsdichte des Objektes selbst. Ein Wert von etwa 1 bedeutet, dass das Objekt eine mit seinen Nachbarn vergleichbare Dichte hat (also nicht als Ausreißer bezeichnet werden kann). Ein Wert kleiner als 1 bedeutet sogar eine dichtere Region (was ein sogenannter „Inlier“ wäre), während signifikant höhere Werte als 1 einen Ausreißer kennzeichnen: LOF >> 1.
Vorteile

Im Gegensatz zu vielen globalen Verfahren zur Ausreißererkennung kann der LOF-Algorithmus mit Bereichen unterschiedlicher Dichte in demselben Datensatz umgehen. Punkte mit einer „mittleren“ Dichte in einer Umgebung mit „hoher“ Dichte werden von LOF als Ausreißer klassifiziert, während ein Punkt mit „mittlerer“ Dichte in einer „dünnen“ Umgebung explizit nicht als solcher erkannt wird.
Während die geometrische Intuition von LOF nur in niedrigdimensionalen Vektorräumen Sinn ergibt, kann das Verfahren auf beliebige Daten angewendet werden, auf denen eine „Unähnlichkeit“ definiert werden kann. Es muss sich dabei nicht um eine Distanzfunktion im strengeren mathematischen Sinne handeln. Der Algorithmus wurde erfolgreich auf verschiedensten Datensätzen eingesetzt, beispielsweise zum Erkennen von Angriffen in Computernetzwerken, wo er bessere Erkennungsraten lieferte als die Vergleichsverfahren. Das wurde 2003 in der Studie „A comparative study of anomaly detection schemes in network intrusion detection“ veröffentlicht.
Nachteile
Ein wichtiger Nachteil von LOF ist, dass die Ergebniswerte schwer zu interpretieren sind. Werte um und weniger sind sicher keine Ausreißer, aber es gibt keine klare Regel, ab welchem Wert ein Punkt ein signifikanter Ausreißer ist. In einem sehr gleichmäßigen Datensatz sind Werte von 1,1 auffällig, in einem Datensatz mit starken Dichteschwankungen kann ein Wert wie 2 noch ein ganz normaler Datenpunkt sein.
Im schlimmsten Falle treten solche Unterschiede sogar in unterschiedlichen Teilen desselben Datensatzes auf. Am besten einigen sich Anwender von vornherein auf einen Schwellenwert, der die Definition eines „Ausreißers“ festlegt.
Erweiterungen

Der Algorithmus lässt sich erweitern. Das „Feature Bagging for Outlier Detection“ wendet LOF in mehreren Projektionen an und kombiniert die Ergebnisse, um in hochdimensionalen Daten bessere Ergebnisse zu erhalten. Die Funktion „Local Outlier Probability“ (LoOP) ist eine von LOF abgeleitete Methode, die die Dichte statistisch schätzt, um weniger abhängig vom genauen Wert von k zu werden. Zusätzlich wird das Ergebnis statistisch in den Wertebereich [0,1] normalisiert, um besser interpretierbare Werte zu liefern. Und „Interpreting and Unifying Outlier Scores“ stellt eine Normalisierung für LOF und andere Verfahren vor, die die Scores statistisch in das Intervall [0,1] normalisiert, um die Benutzerfreundlichkeit des Ergebnisses zu verbessern.
Eine Referenzimplementierung des LOF-Algorithmus ist im Software-Paket ELKI verfügbar, inklusive Implementierungen von Vergleichsverfahren. Die Scikit-Webseite bietet Lernmaterial zum LOF, darunter auf der Seite mit Links zu Python-Quellcode und einem Jupyter-Notebook. Auf der Seite towardsdatascience.com stellt der Autor Phillip Wenig den LOF prägnant und anschaulich vor, der Leser muss jedoch entsprechendes Data-Science-Wissen mitbringen.
:quality(80)/images.vogel.de/vogelonline/bdb/1396700/1396763/original.jpg "2013 führte der US-Paketdienst UPS das Navigationssystem ORION ein (On-Road Integrated Optimization and Navigation) ein. Dieses berücksichtigt garantierte Lieferfristen für einzelne Pakete, angemeldete Abholungen und spezielle Kundenklassen mit bevorzugter Bedienung sowie Daten aus dem Verkehrsfluss in Echtzeit. (UPS)")
Grundlagen Statistik & Algorithmen, Teil 1
Das Problem des Handlungsreisenden und seine praktischen Anwendungen
:quality(80)/images.vogel.de/vogelonline/bdb/1404000/1404092/original.jpg "Illustration des Satzes von Bayes durch Überlagerung der beiden ihm zugrundeliegenden Entscheidungsbäume bzw. Baumdiagramme. (Qniemiec / CC BY-SA 3.0)")
Grundlagen Statistik & Algorithmen, Teil 2
So verfeinert das Bayes-Theorem Spam-Filter – und mehr
:quality(80)/images.vogel.de/vogelonline/bdb/1409900/1409917/original.jpg "Prinzipbild des Rete-Algorithmus. Deutlich sind zwei Netzwerke (Alpha, Beta) zu erkennen und dass darin jeweils sehr viel Speicher benötigt wird. Dieser hohe Speicherbedarf ist einer der wenigen Nachteile des Rete-Algorithmus. (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 3
Speed für Mustererkennung mit dem Rete-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1430600/1430659/original.jpg "Der monegassische Stadtbezirk Monte-Carlo (© Noppasinw - stock.adobe.com)")
Grundlagen Statistik & Algorithmen, Teil 4
Der Monte-Carlo-Algorithmus und -Simulationen
:quality(80)/images.vogel.de/vogelonline/bdb/1481900/1481934/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Grundlagen Statistik & Algorithmen, Teil 5
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
:quality(80)/images.vogel.de/vogelonline/bdb/1509200/1509209/original.jpg "Ereigniszeitanalyse mit zensierten Daten für die Vertriebsabteilung: die Überlebensfunktion für Vertriebstechniker (durchgezogene Linie) und für Vertreter (gestrichelte Linie) in einem Kaplan-Meier-Schätzer. Vertriebstechniker sind ihrer Stelle wesentlich stärker und länger treu als Vertreter. Der blaue und rötliche Hintergrund deckt sich mit der jeweiligen Kurve. (SAS)")
Grundlagen Statistik & Algorithmen, Teil 6
Die Ereigniszeitanalyse – wenn Anfang und Ende die Erfolgsrate bestimmen
(ID:45770883)
:quality(80)/p7i.vogel.de/wcms/d4/90/d49096fad857f07b788198c34b35e010/0128339234v1.jpeg "Prophet ist ein wertvolles Werkzeug zur Datenanalyse mithilfe von Python und R. (Bild: T. Joos)")
:quality(80)/p7i.vogel.de/wcms/59/0b/590bdb8dd7816097e1c233b138c3cf92/0130720216v1.jpeg "Der Autor: Falko Germar-Schwarz ist Strategic Account Executive bei Factor House (Bild: Factor House)")