
:quality(80)/p7i.vogel.de/wcms/6b/7a/6b7a7ae072bb7ab964cde4d302755ceb/0124814981v1.jpeg "Der European Blueprint soll bis Ende 2026 festlegen, welche europäischen Organisationen Zugang zu fortgeschrittenen KI-Modellen erhalten. Verbindliche Pflichten für Anbieter außerhalb der EU entstehen daraus nicht. (Bild: Vergiliy - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/90/bd/90bdca8aec471f2d81b2190ff43a7402/0132025652v2.jpeg "Generative KI und Recurrent Networks laufen auf den Photonik-Prozessoren der zweiten Generation von Q.ANT. (Bild: Q.ANT)")
:quality(80)/p7i.vogel.de/wcms/26/81/2681098961a1b8010bbf241f3e914891/0132345254v1.jpeg "Räumlich-zeitliche Identifikatoren sollen fragmentierte Datenbestände systemübergreifend nutzbar machen. Nach Angaben von The Green Bridge ist die Grundlage für KI-Anwendungen und Automatisierung. (Bild: Unsplash-Steve A Johnson)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")
:quality(80)/p7i.vogel.de/wcms/08/80/0880ca983fee9a7f5063ded041bda70b/0132193434v1.jpeg "GoodData.AI zielt mit „agentischer Analytik\" auf regulierte Branchen wie Finanzwesen, Fertigung und Pharma, in denen Nachvollziehbarkeit von KI-Ergebnissen gefordert ist. (Bild: GoodData.AI)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/9f/fe/9ffe3d484cf6fdc7ea137128b15f60a9/0131577982v1.jpeg "Im Einsatz für den Artenschutz: Ein WWF-Ranger durchstreift den Regenwald. Das geplante Wildlife Protection Operations Center soll solche Einsätze KI- und datenbasiert optimieren. (Bild: Emmanuel Rondeau / WW_US)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/81/6d/816dfab525864f08b3569676daffb31f/0132240748v2.jpeg "Workflow des Ablaufs einer GitLost-Attacke. (Bild: Noma Security)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/fe/b8/feb8768484c1b5fe705a352dc7794ff9/0132390869v1.jpeg "GitLab 19.2 verlagert KI-Agenten von der Code-Erzeugung an den nachgelagerten Engpass aus Reviews und Sicherheitsprüfungen. Die finale Freigabe bleibt beim Entwickler. (Bild: Gitlab)")
:quality(80)/p7i.vogel.de/wcms/df/94/df944e60d812b6c53b09cca19eacfe58/0132385502v1.jpeg "Sebastian Seutter, Global Managing Partner Continental Europe bei HTEC, sieht den entscheidenden Hebel nicht in der Technik, sondern darin, wie gut eine Organisation den passenden Kontext für sie bereitstellt. (Bild: HTEC)")
:quality(80)/p7i.vogel.de/wcms/47/26/4726265505f4e06176a11477afb9f36f/0132346355v1.jpeg "Zum zweiten Mal fand die Gitex AI Europe in Berlin statt: Europäische Innovation war eines der Leitthemen des branchenübergreifenden Technologieevents. (Bild: Lights in Motion)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Übersicht KI- und ML-Stacks, Teil 1 KI-Engines im Bündel mit Hardware
Künstliche Intelligenz (KI) „fällt nicht vom Himmel“. Leistungsstarke KI-Lösungen entstehen auf der Basis gut abgestimmter KI- und Machine Learning Stacks. Davon gibt es zum Glück einige. Etablierte Softwareentwicklungshäuser sind in Sachen KI und Machine Learning (ML) mittlerweile fest im Sattel. Inzwischen wollen andere Unternehmen auch mit ins Boot.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
Künstliche Intelligenz gilt als ein Oberbegriff für lernfähige Systeme und deckt Maschinelles Lernen (ML) eigentlich mit ab. Der Begriff KI findet dann Anwendung, wann immer von lernenden Anwendungen die Rede ist – auch Algorithmen des Deep Learnings sind hiermit abgedeckt. Im Gegensatz dazu stellt ML die autarken oder semi-autarken Handlungsfähigkeiten cyberphysischer Systeme in den Vordergrund, welche hierzu die Analyse von Datenströmen aus Sensorik in nahezu Echtzeit meistern müssen.

Begrifflichkeiten jetzt aber beiseite: Der KI/ML-Goldrausch ist in vollem Gange. IDC-Analysten zufolge soll der weltweite Markt für KI/ML-Lösungen im laufenden Jahr satte 35,8 Milliarden US-Dollar erreichen und sich damit gegenüber dem Vorjahr mit 44 Prozent Wachstum nahezu verdoppeln.
Das deutsche Bruttoinlandsprodukt (BIP) könnte sich dank KI bis zum Jahr 2030 um insgesamt 11,3 Prozent vergrößern, schätzt PwC. Dieses Wachstum entspricht einer Wertschöpfung von rund 430 Milliarden Euro, also knapp über der aktuellen Gesamtwirtschaftsleistung von Ländern wie Österreich und Norwegen.
Sehen, Hören, Handeln
Unternehmen erhoffen sich von KI/ML-Algorithmen zur Auswertung von Big Data einzigartige Wettbewerbsvorteile: mehr Customer Intelligence, niedrigere Kosten dank prädiktiver Instandhaltung, geringere Betriebsrisiken durch Betrugsprävention und Früherkennung von Cyberangriffen. Den Anwendungsmöglichkeiten sind praktisch keine Grenzen gesetzt, sofern sich das Vorhandensein hochwertiger Datenquellen gewährleisten lässt.
Doch was nützt KI als ein Alleinstellungsmerkmal, wenn alle Akteure über dieselben Algorithmen verfügen? Nicht viel. Erst fortgeschrittene KI-Stacks schaffen die Grundlagen, um den Lernfähigkeiten der eigenen Anwendungen die so begehrte Exklusivität zuteilwerden zu lassen.
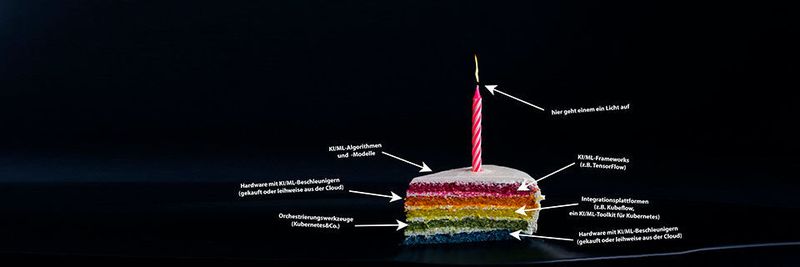
Ein KI-Stack setzt sich wie eine traditionelle Schichttorte aus mehreren Ebenen zusammen. Idealerweise sollten diese ineinander „greifen“ und beim Schneiden und Servieren (sprich: beim Orchestrieren) gut zusammenhalten. Die unterste Ebene des Stacks bildet eine KI/ML-optimierte Hardware (siehe den Abschnitt „Aufgebohrt: KI-Optimierte Hardware“ weiter unten). Auf diesem Infrastrukturfundament setzen dann die Orchestrierungswerkzeuge auf (z. B. Kubernetes). Eine weitere Softwareschicht, die dann wiederum darauf aufbaut, zeichnet für das Management der Orchestrierungswerkzeuge und somit auch die Portabilität des Softwarestacks zwischen verschiedenen Laufzeitumgebungen verantwortlich (mehr zu diesen Aspekten eines Stacks im Abschnitt „Eingespielt: Orchestrierungs-Tools für KI/ML-Workloads“ im zweiten Teil dieser Folge).
Darauf setzt dann das eigentliche KI/ML-Framework auf. Dieses lässt sich gegebenenfalls um externe Dienste, Bibliotheken und sonstige anwendungsspezifische Erweiterungen ergänzen (z. B. im Bereich der Bilderkennung oder Sprachanalyse). Erst oberhalb dieser Schicht entstehen die eigentlichen KI/ML-Modelle und -Visualisierungen. Aus welchen Bestandteilen sich ein bestimmter KI/ML-Stack im Einzelnen zusammensetzt, hängt also im Endeffekt von den avisierten Anwendungsszenarien ab.
Aufgebohrt: KI-optimierte Hardware
KI-Algorithmen wie künstliche Neuronale Netze für maschinelles Lernen müssen in der Inferenzphase die anfallenden Datenströme möglichst echtzeitnah verarbeiten, um zu gewährleisten, dass cyberphysische Systeme auch in Situationen mit hoher Ungewissheit und in einem stark individualisierten Kontext autark handeln können. Neuronale Netze durchlaufen üblicherweise die hierzu erforderliche Trainingsphase, welche die Verarbeitung massiver Big-Data-Bestände voraussetzt, in verteilten Anwendungsarchitekturen in einem voll ausgewachsenen Rechenzentrum. Erst die Inferenzphase kann dann auf dem betreffenden cyberphysischen Edge-System stattfinden (zum Beispiel in einer autonomen Drohne).
Im Gegensatz dazu können sich diejenigen lernenden Algorithmen, die rein historische Daten verarbeiten, sich zwar damit generell mehr Zeit lassen, doch für die Entwickler gestaltet sich das Ganze wohl kaum einfacher. Denn in der ursprünglichen Lernphase geht es vorrangig darum, zuvor ungekannte Zusammenhänge in massiven Datenmengen aufzudecken, statt „nur“ vorgegebenen Denkmustern durch iterative Verbesserungen zu folgen. Diese Herangehensweise ist unter dem Namen Deep Learning bekannt.
Konventionelle CPUs sind mit datenlastigen KI-Workloads nach wie vor überfordert. Sie haben ja auch mittlerweile kaum Spielraum, an Leistung zuzulegen, weil sich das Mooresche Gesetz unweigerlich seinem Ende nähert. Der Aufbau eines KI/ML-Stacks setzt daher zwingend geeignete Hardware voraus. Es fragt sich nur, welche.
Eingebettet: den Datenhunger sättigen
Bisher stehen Entwicklern von KI/ML-Algorithmen GPUs (Graphic Processing Units) von NVIDIA, FPGAs (Field Programmable Gate Arrays) und ASICs wie die TPU (Tensor Processing Units) von Google zur Verfügung.
Diese und andere KI/ML-optimierte Chip-Architekturen sollen über das Ende des Mooreschen Gesetzes hinaus eine Brücke in die Zukunft schlagen. Welches Gelände sich den KI/ML-Entwicklern auf dem anderen Ende dieser Brücke erschließt, weiß bisher so genau noch keiner. Laut den Analysten von Gartner dürften u. a. Quanten-Computer und neuromorphische Chips die Nachfolge heutiger Hardwarebeschleuniger und domainspezifischer Prozessoren antreten.
Zu den guten Nachrichten zählt der Umstand, dass Unternehmen KI-Stacks aufbauen können, ohne sich erst mit spezialisierter Hardware eindecken zu müssen. Die führenden Cloud-Dienstleister bieten Hardware als ein Service aus der Wolke an. So vermietet beispielsweise Google die zweite und dritte Generation der TPU-Beschleuniger für KI-Modelle auf der Basis von Matrizenberechnungen, gebündelt zu je tausend Stück, über die Google Cloud Platform. Als Vorzeigekunden nennt Google u. a. die Metro-Gruppe und die Siemens AG.

Der internationale Spezialist für den Großhandel- und Lebensmitteldirektvertrieb aus Düsseldorf hat seine 100 separaten Buchhaltungssysteme auf SAP-HANA in der Google-Cloud konsolidiert, enthüllt Timo Salzsieder, CIO/CSO der Unternehmensgruppe, bekannt. So könne der Metro-Konzern fortgeschrittene Big-Data-Analysetechniken und KI u. a. zur Optimierung der eigenen Versorgungsketten nutzen.
Der Lebensmittelkonzern lässt seine Daten in die serverlose PaaS-Plattform BigQuery von Google via die Datalab-Infrastruktur einfließen. Hier entstehen unter Verwendung des quelloffenen KI-Frameworks TensorFlow und unter aktiver Mitwirkung der KI-Spezialistin Freiheit.com Technologies GmbH aus Hamburg die eigentlichen ML-Modelle, enthüllt Stefan Richter, Founder and Head of Engineering bei freiheit.com. Die so gewonnenen Erkenntnisse ließen sich dann mithilfe von Google Data Studio in verschiedenen Unternehmensbereichen visualisieren. So lernt die Metro-Gruppe ihre Kunden in Echtzeit kennen.
Branchenspezifische Full-Stack-Fertiggerichte servieren — oder lieber doch selbst backen?

Im Grunde genommen stehen den Unternehmen in Bezug auf die Wahl eines KI-Stacks mehrere diametral unterschiedliche Ansätze offen. Zum einen gibt es branchenspezifische Full-Stack-Umgebungen wie die Drive-Plattform für autonome Fahrzeuge von NVIDIA. Das Unternehmen bietet seinen Partnern unter anderem Referenzdesigns, eine Entwicklungsumgebung, eine Simulationsplattform und ein künstliches neuronales Netzwerk zum Trainieren von ML-Fähigkeiten im Bereich der audiovisuellen Wahrnehmung. NVIDIA ging bereits strategische Partnerschaften unter anderem mit Audi, Mercedes-Benz und VW ein.
Wer eine solche branchenspezifische KI-Entwicklungsplattform nicht benötigt, kann einen eigenen KI/ML-Stack aus quelloffenen Frameworks wahlweise auf eigener Hardware und/oder — wie die Metro-Gruppe — in der Cloud zusammenstellen (siehe dazu den zweiten Teil des Berichtes „KI/ML-Stacks, Teil 2: die (künstliche) Framework-Intelligenz“).
Viele der beliebtesten quelloffenen Frameworks für Maschinelles Lernen (ML), allen voran TensorFlow, sind bei den großen Cloud-Anbietern als vollständig „gemanagte“ Services verfügbar. Dies senkt die Verwaltungskosten, fördert jedoch die Abhängigkeit von den proprietären Lösungen und den Kompetenzen des jeweiligen Dienstleisters.
Cloud-Dienste trumpfen wiederum mit der Fähigkeit, ihren Nutzern die benötigten Hardwarebeschleuniger bedarfsgerecht und kostengünstig zur Verfügung zu stellen. Amazons KI-Dienst Elastic Inference unterstützt beispielsweise den Einsatz von GPU-Beschleunigern für KI/ML-Workloads des Deep Learnings in der Cloud.
McKinsey Global Institute (MGI) schätzt das Wachstumspotenzial der deutschen Wirtschaft durch KI-Technologien bis zum Jahre 2030 (jährlich 1,3 Prozent) auf etwa 16,7 Prozent. Um dieses Ziel zu erreichen, müssten allerdings 70 Prozent aller Unternehmen bis zum Jahr 2030 KI-Lösungen einsetzen, vor allem in den Bereichen automatische Bilderkennung, natürliche Sprache, virtuelle Assistenten, roboterbasierte Prozessautomatisierung und fortgeschrittenes maschinelles Lernen.
Fazit
Die Wahl des KI/ML-Stacks ist keine leichte Entscheidung. Um die steile Lernkurve zu überwinden, entscheiden sich einige Firmen für strategische Partnerschaften, andere wählen wiederum den Weg der kleine Schritte, indem sie eine KI/ML-Lösung nach einem eigenen Rezept aus öffentlich verfügbaren KI/ML-Frameworks „backen“ und hierbei auf die Kompetenzen von Infrastrukturdienstleistern und KI/ML-Entwicklungsschmieden zurückgreifen. Wie dem auch sei: An der intelligenten Auswertung von Big Data kommt keiner mehr vorbei.
:quality(80)/images.vogel.de/vogelonline/bdb/1614600/1614665/original.jpg "15,7 Billionen US-Dollar – diese Summe können KI-Lösungen Schätzungen zufolge bis 2030 zur Weltwirtschaft beitragen. (gemeinfrei)")
Übersicht KI- und ML-Stacks, Teil 2
Künstliche Intelligenz im Eigenbau
(ID:46119526)
:quality(80)/p7i.vogel.de/wcms/88/71/887169bca143bd080356b5395686cf81/0125685819v1.jpeg "Autonome KI-Agenten übernehmen immer häufiger komplexe Aufgaben wie Netzwerkmanagement, FinOps und Datenanalyse – oft im Zusammenspiel als Multi-Agenten-Systeme in Cloud-Umgebungen. (Bild: leszekglasner - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/21/83/2183b1d12ff249dbe99b3b2057c4ad39/0127126428v2.jpeg "„Wir befinden uns auf einem Weg, auf dem die Auswirkungen des Klimawandels erst dann vollständig bekannt sein werden, wenn es zu spät ist, um noch etwas dagegen zu unternehmen,“ sagt Jennifer Turliuk MBA '25, Kurzzeitdozentin am MIT, ehemalige Sloan Fellow und ehemalige Praxisleiterin für Klima- und Energie-KI am Martin Trust Center for MIT Entrepreneurship. Daher sei es gerade jetzt eine einmalige Gelegenheit, im Bezug auf die Entwicklung neuer KI-Systeme innovativ zu sein und diese weniger kohlenstoffintensiv zu gestalten. (Bild: frei lizenziert)")