
:quality(80)/p7i.vogel.de/wcms/90/bd/90bdca8aec471f2d81b2190ff43a7402/0132025652v2.jpeg "Generative KI und Recurrent Networks laufen auf den Photonik-Prozessoren der zweiten Generation von Q.ANT. (Bild: Q.ANT)")
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/25/d2/25d20236b51f4e958a91c11c9e20fad9/0132078197v1.jpeg "Die Regierung Merz will mit einer KI-Taskforce ihre KI-Kompetenzen bündeln. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5a/ad/5aad0113ed8f8be11aa2ed01881738a4/0132139416v1.jpeg "Die europäische Datenpolitik befinde sich im Wandel, so Martin Hacker, Regional Vice President Public Sector bei Elastic. Kurzfristig sei mit spürbaren Erleichterungen jedoch nicht zu rechnen. (Bild: Elastic)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Berufsbild Data Scientist Fachliche Vielseitigkeit und Kreativität sind gefragt
Bei Big-Data-Projekten fällt der Rolle des Data Scientist eine Schlüsselfunktion zu: Dieser Mitarbeiter, der Kenntnisse in Mathematik, Informatik und Betriebswirtschaft vereint, kommuniziert den möglichen Mehrwert von analytischen Resultaten an die Unternehmensleitung. So wird er Teil von strategischen Entscheidungsprozessen.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
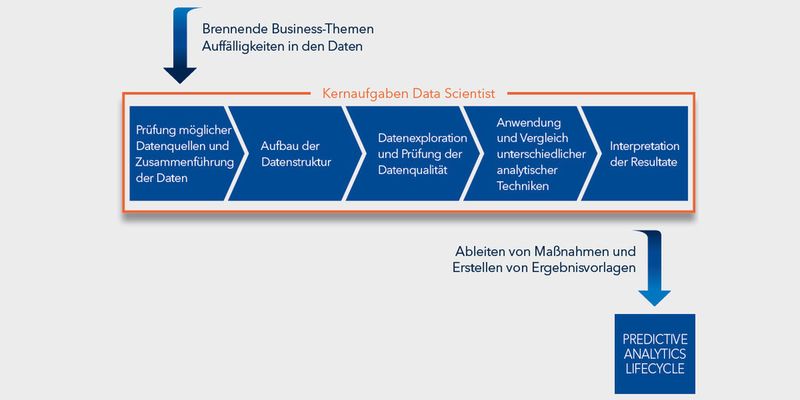
Was macht eigentlich ein Data Scientist? SAS Institute Education beschreibt in einem Whitepaper die Aufgaben so: „Data Scientists arbeiten an der Schnittstelle zwischen Daten und Business. Ihre Aufgabe ist es, geschäftsrelevante Besonderheiten oder Zusammenhänge in den Daten eines Unternehmens zu identifizieren, zu analysieren und sie als Entscheidungsgrundlage für Management oder Fachabteilungen aufzubereiten.“
Das bedeutet: „Data Scientists haben die Aufgabe, Big Data in ,Big Value‘ zu wandeln“, erläutert der Unternehmensberater Wolfgang Martin. „Sie sind verantwortlich für die Methodologie von Big-Data-Analytik sowie die Kommunikation von analytischen Resultaten gegenüber dem Vorstand und dem gesamten Unternehmen.“ Mit anderen Worten: Für die Wertschöpfung von Big Data sind Data Scientist unverzichtbar.
„Data Scientists übernehmen das Organisieren der Daten und das Bauen von analytischen Modellen im Rahmen des Projektes“, präzisiert Martin. „Dazu gehört auch das Überprüfen, Ändern und Ersetzen von Modellen, falls notwendig, sowie die Kommunikation von analytischen Resultaten.“
Idealanforderungen
Laut Martin handelt es sich um Mitarbeiter, die eher im Bereich Business Intelligence angesiedelt sind und folgende Eigenschaften idealerweise mitbringen:
- 1. Technische Expertise: Tiefe Kenntnisse in einer Natur- oder Ingenieurs-Wissenschaft sind notwendig. Sie bilden die Grundlage, um als Data Scientist erfolgreich arbeiten zu können. Insofern sollte man zukünftige Data Scientists in dieser Gruppe suchen und dann auch die weiteren geforderten Eigenschaften testen.
- 2. Problembewusstsein: Die Fähigkeit, ein Problem in überprüfbare Hypothesen aufzubrechen.
- 3. Kommunikation: Die Fähigkeit, komplexe Dinge per Anekdoten durch einfach verständliche und gut kommunizierbare Sachverhalte darzustellen.
- 4. Kreativität: Die Fähigkeit, Probleme mit anderen Augen zu sehen und anzugehen („thinking out of the box“).
SAS ist nicht so streng bei der Stellenbeschreibung: „In jedem Unternehmen gibt es Mitarbeiter, die die Voraussetzungen mitbringen, sich zum Data Scientist weiterzubilden. Dafür sind Talent und Veranlagung, Flexibilität und Lust auf Neues erforderlich. Und eine Grundausstattung an technisch-methodischem Know-how.“
Unterschiedliche Karrierewege
Der Weg zum Data Scientist kann demnach ganz unterschiedlich verlaufen und hängt sowohl vom Unternehmen als auch vom jeweiligen Mitarbeiter ab: Manche kommen aus dem technisch-naturwissenschaftlichen Bereich und haben sich das notwendige Business Know-how angeeignet. Andere starten mit Fachabteilungsperspektive, beispielsweise aus Marketing, Vertrieb oder Controlling, und bilden sich in den erforderlichen technischen Disziplinen weiter.
Stephan Reimann und Alexander Richthammer sind IBM-Mitarbeiter aus der Praxis der Big-Data-Analyse. „Der Data Scientist“, so Reimann, „kümmert sich mithilfe von Data Mining um die Frage, wie sein Unternehmen bzw. seine Organisation Wissen und Nutzen aus Daten ziehen kann. Im Rahmen von Data Mining setzt er auch ETL-Tools ein. Seine Arbeitsweise ist vor allem explorativ.“ Daher benötige der Data Scientist als berufliche Vorbildung Mathematik, BWL und/oder Informatik. „Fachliche Geschäftsprozesse zu kennen, ist etwa für Disziplinen wie Predictive Maintenance wichtig“, weiß Reimann.
Kein Allround-Talent
Aber der Data Scientist braucht kein Allround-Talent zu sein. Um möglichst effektiv arbeiten zu können, ist er Teil eines Dream Teams, dessen Rollen – nicht Stelle – McKinsey für Big Data skizziert hat:
- 1. Data Hygienists stellen sicher, dass die Daten bereinigt und richtig sind und auch über den Lebenszyklus der Daten so bleiben. Dieses Data Profiling und Cleansing beginnt ganz am Anfang des Projektes, wenn die ersten Daten erfasst werden. Daran sind alle Team-Mitglieder beteiligt, die diese Daten nutzen wollen. Eine bekanntere Stellenbezeichnung dafür ist Data Steward.
- 2. Data Explorers durchsuchen das Big-Data-Universum, um die Daten aufzufinden, die man im Projekt braucht. Dazu gehört auch die Aufbereitung der Daten für das Projekt, denn die meisten Daten draußen wurden nicht erzeugt, um analytisch untersucht zu werden, sind also weder für eine Analyse geeignet noch angemessen gespeichert oder organisiert.
- 3. Business Solution Architects haben die Aufgabe, die identifizierten Daten zusammenzustellen und für die Analyse vorzubereiten. Dazu werden die Daten auch für die erwarteten Abfragen strukturiert. Daten, die im Minuten- oder Stundentakt benötigt werden, müssen dann auch entsprechend aufgefrischt werden.
- 4. Data Scientists übernehmen das Organisieren der Daten und das Bauen von analytischen Modellen im Rahmen des Projektes. Dazu gehört auch das Überprüfen, Ändern und Ersetzen von Modellen, wenn notwendig, sowie die Kommunikation von analytischen Resultaten gegenüber dem Vorstand und dem gesamten Unternehmen.
- 5. Campaign Experts haben die Aufgaben, die Ergebnisse zu interpretieren und in entsprechende Aktionen umzusetzen in. Dazu gehören auch das Priorisieren von Kanälen und das Festlegen der Kampagnen-Sequenzen.
„Die Rollen der Data Explorers und Campaign Experts benötigen Expertisen wie Cognitive Scientists und Behavioral Economists“, erläutert Wolfgang Martin. „Solche Expertise ist notwendig, um zu identifizieren, welche Daten für das Projekt wichtig sind und welche nicht. Sie ist auch von großer Hilfe in der Interpretation von Ergebnissen und entsprechenden Umsetzungen.“ Im Hinblick auf Information Governance ist der Data Steward die ideale Ergänzung zum Data Scientist: „Er spielt in der Big-Data-Analytik die Rolle eines SWAT-Teams, also eines taktisch agierenden Spezialteams, und nicht die strategische Rolle wie im Unternehmen.“
Der Data Scientist in der Praxis
Soweit die Theorie. Die reale Arbeitsweise des Data Scientist sieht ebenfalls sehr spannend aus. „Dazu gehört die Aufbereitung von Datenquellen und die Bildung von Datenkategorien“, erzählen Stephan Reimann und Alexander Richthammer von IBM. „Bei der Auswahl der passenden Technologie oder des Betriebsmodells – online oder on-premise – ist entscheidend, wie der Use Case aussieht.“ Hier ist also fachliches Wissen gefragt. „Die Cloud wird aus Kostengründen manchmal bevorzugt und sowohl Hadoop als auch NoSQL-Datenbanken, die man aus der Cloud beziehen kann, helfen, umfangreiche Datenbestände schnell und ohne Schema-Vorgabe zu durchforsten“ – ganz im Sinne der Data Exploration.
Um die Produktivität des Data Scientist zu erhöhen, insbesondere bei der Programmierung, ist eine Software gefragt, die zeitraubende Routine-Aufgaben automatisiert oder sie zumindest vereinfacht. Ein Beispiel ist IBM BigSheets, das zum Lieferumfang von InfoSphere BigInsights 3.0 gehört: „Der Vorteil von BigSheets: Der Data Scientist muss keine MapReduce-Jobs mehr in Java schreiben usw., sondern erledigt seine Aufgabe anhand von Tabellen, die zusammengeführt und gemappt werden“, berichtet Reimann. Daher der Name „sheets“ – Tabellen.
Viele Analyseverfahren
SPSS Modeler wird von IBM für Data Mining angeboten. Der Data Scientist bereitet mit dem Modeler Daten auf und nutzt eine Vielzahl von Data-Mining-Verfahren für die Analyse. Die Algorithmen können mit den vorgegebenen und auf Best Practices beruhenden Voreinstellungen ausgeführt werden oder bei Bedarf individuell mit sogenannten „Experteneinstellungen“ optimiert werden.
Bei Bedarf schlägt der Modeler die passenden Methoden bzw. Algorithmen zu ihrer Auswertung vor. Hierbei werden automatisiert alle relevanten Algorithmen ausgeführt und die besten Vorhersagemodelle ausgegeben. Ein von Reimann angeführtes Beispiel wären automatische Klassifizierer, die Daten kategorisieren. Modellierprozesse lassen sich als sogenannte „Streams“ in der Process Modeling Markup Language (PMML) ablegen und wiederverwenden. „Auf die Modellierung entfallen zehn bis 30 Prozent der Arbeit“, berichtet der Data Scientist.
Auch die Leistungssteigerung fällt ins Aufgabengebiet von Data Scientist und SPSS Modeler. „Die Methode des SQL Pushback verhindert, dass große Datenmengen – Big Data – übers Netz geschickt werden“, so Richthammer. Somit wird das Netzwerk entlastet. „Dazu werden Anweisungen und Regeln des Modelers an die Datenbank oder Hadoop geschickt und dort ausgeführt. Nur das Ergebnis wird übers Netzwerk zurückgeschickt.“ Bei Messungen lieferte der Einsatz von SQL Pushback erhebliche Performance-Gewinne und die Produktivität des Data Scientist wurde verbessert.
Anwendungsbeispiele und Erfolge
Mit seiner Arbeit kann der Data Scientist beispielsweise Kündigungen, etwa bei Personal, Versicherung, Mobilfunkverträgen usw., vorhersagen. „Im E-Commerce ist die Vorhersage des Kundenverhaltens von großer Bedeutung“, weiß Richthammer. Denn nur ein so optimierter Webshop ist ein profitabler Webshop.
SAS Education, IBM und EMC gehören zu den Unternehmen, die attraktive und detailliert beschriebene Ausbildungskurse zum Data Scientist anbieten. Pedro DeSouza, ein leitender Data Scientist bei EMC, freut sich: "Einer meiner Kunden konnte durch Analysen Kosten im zweistelligen Millionenbereich einsparen. Bei diesem Projekt haben wir fünf Millionen Caller Detail Records (CDR) untersucht. Durch die entsprechenden Analysen konnten wir ermitteln, bei welchen Nutzern Serviceprobleme auftraten. Bis dahin wurden bei Tausenden Kunden überflüssige, aber kostspielige Reparaturen ausgeführt.“
Durch eine weitere Datenmodellierung, den „Churn-Algorithmus“, konnte auch die Abwanderung („churn“) von Handykunden um 30 Prozent gesenkt werden. Dass Big Data nicht immer teuer sein muss, zeigt DeSouzas drittes Beispiel: „Ich konnte dazu beitragen, dass die Kosten für Big-Data-Analysen in einem Unternehmen von rund zehn Millionen US-Dollar auf 100.000 US-Dollar pro Jahr gesenkt wurden. Für die entsprechende kleine Änderung musste nicht einmal der laufende Betrieb unterbrochen werden.“
(ID:43210864)
:quality(80)/p7i.vogel.de/wcms/ec/d6/ecd6e69172380e583e7a75c0db7c51ef/0127955966v1.jpeg "Die neue dialogorientierte Benutzerschnittstelle zu AI Platform von ServiceNow heißt AI Experience. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/4c/01/4c0194118da7847890b69dc7032e0c1b/0126827011v1.jpeg "Damit der Data Lake nicht „versumpft“, braucht es ein durchdachtes Governance-Konzept. (Bild: © vladimircaribb - stock.adobe.com)")