
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Planungshilfe für Big Data Welches Hadoop darf's denn sein?
Zukunftsorientiert, wirtschaftlich und flexibel – es gibt viele Gründe, die Hadoop zur Allzweckwaffe für den Übergang in das Big-Data-Zeitalter machen. Das große Spektrum an Möglichkeiten wirft bei IT-Verantwortlichen aber auch zahlreiche Fragen auf.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
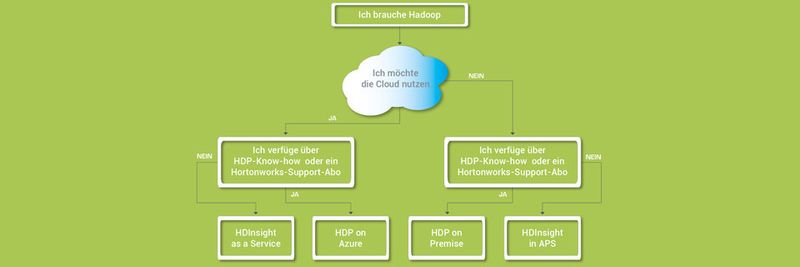
„Wir brauchen Hadoop!“, hallt es gegenwärtig weltweit aus Entscheiderkreisen, wenn es um die Zukunft der unternehmenseigenen Business Intelligence (BI) geht. Das Open Source Framework der Apache-Gemeinde hat sich fraglos als Standard für Big Data etabliert.
Die geringen Kosten sind nur eines von vielen Argumenten: Hadoop und seine Distributionen, wie etwa die Hortonworks Data Platform (HDP), können lizenzfrei und bei Bedarf sogar auf günstiger Standard-Hardware betrieben werden. Dazu locken vollkommen neue Geschäftsideen, da sich Datenbestände in bislang ungekannter Vielfalt und Menge verarbeiten lassen.
Gleichzeitig erlaubt die Technologie Abfragen über SQL – sprich: Anwender, die mit relationalen Datenbanken umgehen, werden sich auch in der Hadoop-Welt zurechtfinden. Nicht zuletzt gibt es dank der offenen Entwicklungsumgebung für jedes gängige Praxisszenario passende Lösungsbausteine.
Die Qual der Wahl
Doch gerade der Segen der Flexibilität kann auch zum Fluch werden. Denn: Welche Hadoop-Variante ist für die eigenen Anforderungen die richtige? Wie geht man in diesem Zusammenhang mit sicherheitsrelevanten Daten um? Ist die berüchtigte Cloud eine Option? Inwieweit kann ich die Technologie selbst installieren? Die Liste der Fragen lässt sich beliebig erweitern. Ein Blick auf typische Anwendungssituationen bringt Licht ins Dunkel.
„On-premise“ in einer Linux-Umgebung
Vor allem in Deutschland wird das Thema Sicherheit weiterhin groß geschrieben. Daher besteht ein hoher Bedarf an Lösungen, bei denen Datenbestände „On-premise“, also intern oder auf lokalen Ressourcen gehalten werden. Für die allgemein übliche Linux-Serverlandschaft bietet Hadoop eine besonders kostengünstige Option: Die Technologie kann auf der bereits vorhandenen Hardware betrieben werden.
Voraussetzung ist jedoch, dass die Rechner der Cluster-Knoten hinsichtlich Leistung und Speicher möglichst identisch ausgestattet sind. Andernfalls gestaltet sich die Installation äußerst komplex, wobei sich Fehler unmittelbar auf die Abfrage- und Analyse-Performance auswirken.
Know-how ist Pflicht
Daran zeigt sich auch: Wer Hadoop in Eigenregie betreiben möchte, der sollte über entsprechendes Know-how im Unternehmen verfügen. Ebenso kann sich die Unterstützung externer Berater als sinnvoll erweisen. Sonst schlägt der vermeintliche Kostenvorteil schnell ins Gegenteil um.
Der führende Hadoop-Anbieter Hortonworks bietet ein „Jumpstart“-Programm an, bei dem ein Cluster innerhalb von einer Woche hochgezogen und bereitgestellt wird. Zudem hält das Unternehmen im Rahmen eines Support-Abos einen Rundum-Service für den laufenden Betrieb bereit.
Vorkonfigurierte Lösung für Windows
Für den On-premise-Einsatz in einem Windows-Umfeld steht eine eigene Hadoop-Version zur Verfügung. Sie ist das Resultat der Microsoft-Partnerschaft mit Hortonworks und basiert folgerichtig auf der HDP. Darüber hinaus hat Microsoft die Hortonworks-Distribution zur Hadoop-Plattform HDInsight weiterentwickelt.
Nach Aussage des Herstellers fällt die Implementierung der Windows-Variante auf der eigenen Hardware prinzipiell leichter als im Linux-Bereich. Sinnvoll ist die Verwendung allemal, wenn die passenden Server in einem Unternehmen bereits vorhanden sind. Hierbei hat Microsoft für die Bereitstellung, Verwaltung und Überwachung eigens das Hadoop-Framework Ambari in sein System Center bzw. den Operations Manager integriert.
Einfacher gestaltet sich der Einstieg in die Hadoop-Welt mit einer vorkonfigurierten Appliance. Ein anschauliches Beispiel bildet das Analytics Platform System (APS). Die „schlüsselfertige“ Komplettlösung basiert einerseits auf dem „Massively Parallel Processing“ (MPP) des Parallel Data Warehouse (PDW), in dessen Kontext die strukturierten Datenbestände des SQL-Servers verarbeitet werden. Andererseits wurde mit HDInsight eine Komponente beispielsweise für unstrukturierte Massendaten integriert.
Die Abfragetechnologie „PolyBase“ sorgt schließlich dafür, dass die beiden Welten mittels SQL auch von Fachanwendern nahtlos, transparent und flexibel verknüpft werden können. Das APS lässt sich im Regelfall sehr einfach in ein bestehendes BI-Umfeld einbinden. Vorhandene Data Marts, DWHs und Hadoop-Cluster können umfassend konsolidiert bzw. integriert werden. Ebenso ist eine Auslagerung der unstrukturierten Daten in die Cloud möglich. Zudem kann die Anwendung bis in den Multi-Peta-Bereich linear skaliert werden, sodass man auch für künftige Big-Data-Szenarien gerüstet ist.
Datenmanagement in der privaten Cloud
Im Windschatten von Big Data bahnt sich auch die Cloud unaufhaltsam ihren Weg. Beliebig skalierbare Rechen- und Speicherressourcen, die auf Abruf bereitstehen – das klingt nach guten Voraussetzungen für das neue Datenzeitalter. So öffnet sich selbst die kritische, deutsche Klientel zunehmend der Thematik. Denn: Neben den Vorteilen der Wirtschaftlichkeit und des einfachen Handlings halten Cloud-Anbieter mittlerweile auch für Sicherheitsfragen die passenden Antwort bereit.
Für den Hadoop-Einsatz auf Linux lässt sich beispielsweise eine sogenannte Private Cloud mittels HDP einrichten. Dabei werden die Cluster auf gesonderten Servern ausgerollt, die ausschließlich für den eigenen Gebrauch bereitstehen. HDP deckt in diesem Kontext das gesamte Spektrum von der Speicherung über das Management bis hin zur Analyse der strukturierten und unstrukturierten Massendaten ab. Auf diese Weise können virtuelle Rechnerverbünde aufgebaut werden, die die gleichen Arbeitsprozesse wie eine On-premise-Lösung übernehmen.
Unternehmen haben somit die Möglichkeit, Zukunftsszenarien kostengünstig zu antizipieren und einen fließenden Übergang in die Big-Data-Ära geschaffen werden. Ebenso lässt sich eine hybride Umgebung anlegen, bei der etwa personenbezogene Daten konsequent on-premise gehalten werden können, während man per se unkritische Quellen wie Sensoren oder Weblogs per Cloud verwaltet.
Über den Azure Marketplace lässt sich ein privates HDP-Cluster mithilfe des Wizard-Assistenten sehr einfach aufbauen. Dabei können die Clustergrößen frei gewählt und je nach Bedarf aufgestockt oder verringert werden. Das seit HDP 2.3 verfügbare Cloudbreak bietet sogar die Möglichkeit, diese Vorgänge zu automatisieren: Etwaige Lastgrenzen werden im Vorfeld definiert. Wenn man diese erreicht hat, vergrößert das System selbstständig die Anzahl der Knoten. Indes werden bei einer „Unterbeschäftigung“ die Ressourcen automatisch wieder zurückgefahren.
„Hadoop as a Service“
Wird indes Wert auf eine einfache und kostengünstige Nutzung gelegt, dann ist der HDInsight-Service auf Microsofts Cloud-Computing-Plattform „Azure“ zu bevorzugen. Nicht nur die Integration in die Microsoft-Welt fällt auf diesem Weg wesentlich leichter, da beispielsweise C# anstelle von Java als Programmiersprache genutzt wird.
Auch das Handling durch den Anwender gestaltet sich komfortabler. Es ist keinerlei Know-how zur Infrastruktur oder der Konfiguration erforderlich. Vielmehr erfolgt die Navigation über eine intuitiv zu bedienende Web-Oberfläche, auf der Cluster in beliebiger Größe erzeugt und auch während des Betriebs verändert werden können. Ebenso lässt sich die Hinzunahme oder Verringerung von Speicherressourcen terminieren bzw. automatisieren.
Ein besonderer Benefit ist dabei, dass Datenimport und -export auf einem anderen Speicher-Container stattfinden können, als dem HDInsight-Cluster. Das heißt: Die betreffenden Daten – etwa von Sensoren – laufen über den Tag hinweg im Speicher auf. In der Nacht startet ein gebuchtes HDInsight-Cluster automatisch mit der Transformation der Daten und schiebt diese schließlich wieder zurück. Danach schaltet sich das Cluster selbstständig wieder ab. Somit handelt es sich auch um eine äußerst wirtschaftliche Lösung, da letztendlich nur für die Zeit bezahlt wird, in der das Cluster online war.
Fazit: Sicherheit ist kein Argument
Cloud oder on-premise? Das ist also eine der Kernfragen, die sich bei der Auswahl der passenden Hadoop-Technologie stellt. Dabei wird die Sicherheit als wichtigstes Argument für eine interne Datenhaltung oftmals überbewertet. Nicht nur, dass Cloud-Anbieter inzwischen ebenso umfassende wie effektive Schutzfunktionen bieten. Gleichzeitig müssen sich die On-premise-Befürworter vergegenwärtigen, dass auch hinter der eigenen Firewall viele Gefahren lauern können.
Hardware, die bereits verwanzt geliefert wird, ist hierfür nur eines von zahlreichen Beispielen. Daher sind auch in diesem Kontext umfangreiche Sicherungsmaßnahmen erforderlich, angefangen bei einer leistungsfähigen Security-Architektur bis hin zur Verschlüsselung von ruhenden und bewegenden Daten. So ist es immer weniger von Belang, wo sich der Hadoop-Cluster letztendlich befindet.
Insofern macht eine konsequente Datenhaltung „on-premise“ nur noch Sinn, wenn per se sämtliche Bestände auf internen Ressourcen vorliegen und entsprechend verschoben werden müssten. Währenddessen sehen sich die Unternehmen in Zukunft noch stärker mit den schnell wechselnden und wachsenden Anforderungen einer modernen Geschäftswelt konfrontiert. Zum Erhalt der Wettbewerbsfähig wird ein hohes Maß an Flexibilität erforderlich sein, dass letztendlich nur Cloud-basierte Hadoop-Lösungen gewährleisten können. Entsprechend werden diese auch immer mehr an Bedeutung gewinnen.
(ID:43582914)
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/55/00/550007979508377a91017d5d9625a7e5/0129898368v2.jpeg "Die PIC64-Serie an Multicore-Mikroprozessoren setzt auf RISC-V-Kerne und eignen sich speziell für Anwendungen mit asynchronem Multipricessing (AMP) in intelligenten Embedded-Edge-Anwendungen. (Bild: Microchip)")