
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/b3/d4b39c1c2d46f3ae6e49ed80f2ecd9d1/0132006976v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/e2/bae2c84df6310701a01325e9fbfd96d6/0132099756v1.jpeg "Simon Ritter, Deputy CTO bei Azul, warnt: Vibe Coding produziere Code, der tue, was das Modell verstanden habe – nicht, was gemeint war. (Bild: Azul)")
:quality(80)/p7i.vogel.de/wcms/b5/f4/b5f489601994978d1730f20e206002f7/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Antwortzeiten beschleunigen So machen Sie Hadoop Beine mit Apache Tez
Apache Tez hilft Unternehmen dabei Anwendungen, zu entwickeln, die zusammen mit Hadoop, Yarn, Hive und Pig eine effiziente Big-Data-Umgebung bieten. Die ursprünglich von Hortonworks entwickelte Anwendung unterstützt Directed Acyclic Graph (DAG) und soll, einfach ausgedrückt, eine Schnittstelle für andere Big-Data-Anwendungen liefern, um deren Leistung zusammen mit Hadoop deutlich zu verbessern.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
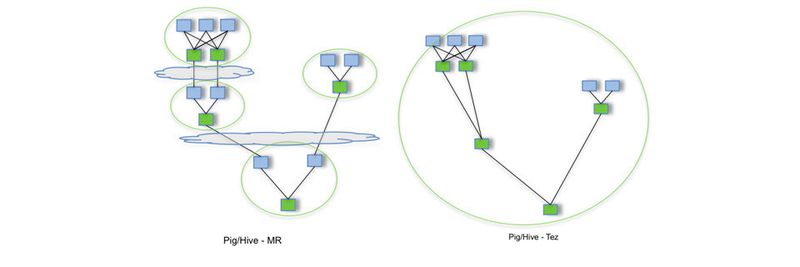
Hadoop ist in der aktuellen Version weit mehr als ein herkömmliches Werkzeug für die bessere Verwaltung von Big Data. Das Hadoop-Ökosystem ist zu einer Art Betriebssystem für Big-Data-Umgebungen aufgestiegen und bietet eine Vielzahl an Möglichkeiten und Erweiterungen. Diese Erweiterungen lassen sich in einer Art Framework zusammen nutzen. Dabei steigt die Leistung, aber auch die Effektivität der Umgebung an. Eine dieser Lösungen ist Apache Tez.
Tez wurde nicht für Endanwender in Big-Data-Umgebungen zur Verfügung gestellt, sondern für Entwickler, die Abfragen und Jobs effizienter erstellen wollen. Vor allem wenn es um die Verarbeitung von Daten in Echtzeit oder zumindest nahezu in Echtzeit geht, müssen Entwickler in Standard-Hadoop-Umgebungen nacharbeiten, damit die Leistung von Abfrage-Jobs akzeptabel ist. Genau für diese Einsatzzwecke wurde Tez entwickelt. Auch Apache Hive und Pig setzen beim Abfragealgorithmus mittlerweile nicht mehr auf MapReduce, sondern auf Tez.
Darum ist Tez schneller als MapReduce
Tez baut auf Yarn auf und wird auch durch Yarn gesteuert. Unternehmen müssen für den Einsatz von Tez auf ihrem Hadoop-Cluster keinerlei Einstellungen ändern oder Software installieren. Tez ist ein Client-Programm, welches sehr einfach implementiert werden kann. Entwickler müssen nur die notwendige Tez-Bibliothek in HDFS hochladen und danach mit dem Tez-Client eine Verbindung aufbauen. Tez kann jeden MapReduce-Job ohne Modifikationen ausführen. Das erleichtert die Migration zu Tez und bietet eine sehr schnelle Integration der Umgebung. Entwickler können mehrere MapReduce-Jobs in einen Tez-Job überführen und dadurch enorm die Leistung steigern. Während jeder Mapreduce-Job seine Ergebnisse in HDFS speichern muss, benötigt der Tez-Job für seine Ausführung keinen schreibenden Zugriff auf HDFS. Auch das beschleunigt die Ausführung enorm.
Schnellere Datenverarbeitung mit Tez
Apache Tez erweitert Hadoop in einem wichtigen Bereich, nämlich der Schnittstelle zwischen der Datenverarbeitung und den interaktiven Anwendungen.
Da das Tool mittlerweile als Toplevel-Produkt aufgenommen wurde, ist auch der Einsatz in produktiven Big-Data-Umgebungen sinnvoll. Viele große Unternehmen arbeiten mittlerweile mit Apache Tez und helfen auch bei der Weiterentwicklung, zum Beispiel Facebook, LinkedIn, Microsoft oder Twitter und Yahoo. Aber auch die NASA und Netflix nutzen Tez.
Entwickler können mit Apache Tez Anwendungen oder Batch-Dateien für die Datenverarbeitung erstellen und dabei auf die APIs von Tez setzen. Das verbessert nicht nur die Leistung der Anwendungen, sondern erleichtert auch deutlich die Entwicklung. Tez setzt dabei auf Yarn auf und arbeitet direkt mit der Hadoop-Erweiterung zusammen. Tez kann MapReduce ersetzen und dabei auch auf mehrere Hadoop-Cluster parallel zugreifen, die in verschiedenen Rechenzentren verteilt sind.
Unterstützung von Pig und Hive
Da MapReduce mittlerweile für viele Anforderungen nicht genügend Leistung bietet, ersetzen viele Unternehmen seit Hadoop 2 diese Funktion in Hadoop. Apache Pig und Hive nutzen ebenfalls Tez. Netzflix setzt seit einiger Zeit auf Apache Pig und konnte durch die Umstellung auf die Kombination Tez/Pig die Leistung mehr als verdoppeln. Profis schätzen an dem Projekt, dass Abfragen interaktiver und schneller durchführbar sind, als durch den eher starren Batch-Ansatz von MapReduce. Das ist auch der Grund, warum die NASA das Produkt für die Berechnung von Klima-Szenarien nutzt.
Apache Hive bietet die Möglichkeit, SQL-Abfragen für Hadoop-Datenbanken zu erstellen. Dazu wird der MapReduce-Ansatz verwendet. Da sich hier ebenfalls Tez einbinden lässt, steigt auch in diesem Bereich deutlich die Leistung.
Tez versus Spark
Vielen Unternehmen stellt sich auch die Frage, ob sie auf Apache Tez oder auf Spark setzen sollen. Spark und Tez arbeiten optimal mit Hive zusammen, beide bieten Directed Acyclic Graphs.
Im Grunde genommen kann auch Spark viele der Funktionen in Hadoop einbringen, die auch Tez kann. Sowohl Spark, als auch Tez unterstützen Directed Acyclic Graphs. Beide Erweiterungen arbeiten optimal mit Hive und Yarn zusammen, bieten In-Memory-Technologien, können alle Arten und Daten verarbeiten und sind auch ansonsten recht ähnlich im Funktionsumfang.
Setzen Unternehmen aber auf eine Umgebung mit Hive und Pig, so kann es sinnvoll sein, die in diesen beiden integrierte Tez-Erweiterung als Backend für MapReduce zu nutzen.
Sollen direkt die APIs genutzt werden, zum Beispiel um einen Data-Transformation-Job zu erstellen, empfehlen viele Big-Data-Profis, einen Distributed-Machine-Learning-Algorithmus zu implementieren.
Hier ist Spark häufig besser geeignet als Tez. Auch beim Erstellen einer eigenen Data Processing Language kann Spark oft sinnvoll sein, da die APIs für viele Entwickler schnell umsetzbar sind. Tez ist vor allem für die Zusammenarbeit mit Pig/Hive optimiert, lässt sich teilweise aber dafür etwas komplizierter in die Umgebung einbinden. Arbeiten Unternehmen mit Pig, hat Tez oft die Nase vorne, da die Kooperation von Spark/Pig noch nicht ideal gelöst ist.
Yarn ist Pflicht
Spark arbeitet mit Yarn zusammen, lässt sich grundsätzlich aber auch ohne Yarn nutzen. Das ist ein großer Unterschied zu Tez. Denn Tez baut immer auf Yarn auf und lässt sich ohne Yarn kaum bis gar nicht einsetzen. Dafür benötigt Tez keinerlei Container, sondern nur den Application Manager im Hadoop-Cluster. Container lassen sich zwar anbinden, aber nur aus Optimierungsgründen, nicht als Voraussetzung.
Aber auch hier müssen Entwickler selbst entscheiden, welche Technik besser passt. Beide Erweiterungen können Daten von Hadoop lesen und schreiben. Dazu bieten beide Open-Source-Lösungen eine vollständige Unterstützung für MapReduce in so gut wie allen Formaten. Im Fokus von Tez liegt die höhere Geschwindigkeit der Abfragen, im Gegensatz zu MapReduce. Das spielt vor allem für Hive und Pig eine wichtige Rolle.
Das ist auch der Grund, warum in vielen Fällen Hive, Pig und Tez in einem Atemzug genannt werden, wenn es um die Verbesserung und Optimierung von Hadoop-Umgebungen geht. Aber auch Spark bietet eine sehr gute Leistung. Außerdem verfügt Spark über eine effiziente API mit einem großen Satz an unterstützten Operatoren. Spark bietet mit REPL eine beliebte interactive Shell. Interessant ist auch die Python API. Aber auch hier spielen persönliche Geschmäcker eine wichtige Rolle. Tatsache ist, dass sowohl Tez als auch Spark für identische Einsätze entwickelt wurden und einen echten Mehrwert für Hadoop-Umgebungen liefern.
Fazit
Spark ist älter und teilweise ausgereifter, Tez bietet in Teilen bessere Leistung. Allerdings gibt es keine objektiven, zuverlässigen Leistungsvergleiche. Unternehmen müssen selbst testen, welche der beiden Lösungen ideal für ihre Umgebung ist. Aus diesem Grund sollten Unternehmen, die auf Big Data setzen, immer beide Lösungen parallel betrachten. Tez spielt immer dann seine Stärken aus, wenn sehr große Datenmengen in kurzer Zeit verarbeitet werden sollen und eine skalierbare Umgebung gefragt ist.
(ID:43522079)
:quality(80)/p7i.vogel.de/wcms/b5/f5/b5f50f43eb5fd6fb4b90f914dcbf3218/0130075484v1.jpeg "OpenClaw lässt sich lokal oder auf gehosteten Systemen installieren und mit verschiedenen LLMs verbinden. (Bild: T. Joos)")
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")