
:quality(80)/p7i.vogel.de/wcms/49/c6/49c665060846beb129ae679a2918c61a/0132163773v1.jpeg "Wer trägt die Verantwortung? Echte Datensouveränität bei KI und Cloud bedeutet, die Kontrolle über sensible Daten sicher in der eigenen Hand zu behalten. (Bild: © Lustre - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/6b/7a/6b7a7ae072bb7ab964cde4d302755ceb/0124814981v1.jpeg "Der European Blueprint soll bis Ende 2026 festlegen, welche europäischen Organisationen Zugang zu fortgeschrittenen KI-Modellen erhalten. Verbindliche Pflichten für Anbieter außerhalb der EU entstehen daraus nicht. (Bild: Vergiliy - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/26/81/2681098961a1b8010bbf241f3e914891/0132345254v1.jpeg "Räumlich-zeitliche Identifikatoren sollen fragmentierte Datenbestände systemübergreifend nutzbar machen. Nach Angaben von The Green Bridge ist die Grundlage für KI-Anwendungen und Automatisierung. (Bild: Unsplash-Steve A Johnson)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/d9/db/d9dbfbca0f9ff41469a40d883f8e5cb5/0132438388v1.jpeg "Mit Version 9.5 rückt Denodo die semantische Schicht ins Zentrum der Plattform und positioniert sich im Wettbewerb um die Kontextversorgung von KI-Agenten. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b8/76/b8761191f739895263a4bdbfcaf9c5b2/0132429694v1.jpeg "Mit dem Wechsel von assistierenden zu ausführenden Agenten verlagert sich der Kontrollbedarf im Produktdatenmanagement. Entscheidend wird die Nachvollziehbarkeit einzelner Attributänderungen. (Bild: Akeneo)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")
:quality(80)/p7i.vogel.de/wcms/78/9a/789af78a62e28f5e8cc995570d48b822/0130655525v1.jpeg "SupplyX wollte sein Transportmanagement-System ersetzen und fand den Engpass in den Daten. Ein Praxisbericht über die Datenbasis produktiver KI. (Source: © MAGNIFIER - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/9f/fe/9ffe3d484cf6fdc7ea137128b15f60a9/0131577982v1.jpeg "Im Einsatz für den Artenschutz: Ein WWF-Ranger durchstreift den Regenwald. Das geplante Wildlife Protection Operations Center soll solche Einsätze KI- und datenbasiert optimieren. (Bild: Emmanuel Rondeau / WW_US)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/e9/34/e9342418bd8081921fdd2fc2fc4be51b/0132359705v2.jpeg "Einsatz auf dem Acker: Wie sich humanoide Systeme mit schweren landwirtschaftlichen Maschinen vernetzen lassen, wird in Ilmenau erprobt. (Bild: Fraunhofer IOSB)")
:quality(80)/p7i.vogel.de/wcms/57/b8/57b8da3ba179d80f10073e7541f8b68f/0132491632v1.jpeg "Die Brücke vom Trainings-Cluster über die Simulation bis zum Roboter im Feld hat Lücken: Physical AI scheitert seltener am Modell als am Workflow. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f9/43/f943ca681620e9eb521fea039168a2fe/0132555049v1.jpeg "Die Konferenz T3 – Transform The Tomorrow diskutiert am 1. und 2. Dezember 2026 Strategien, wie Unternehmen sich zukunftssicher aufstellen können. (Bild: © Vogel Corporate Solutions / AdobeStock 1280236166, Oksana)")
:quality(80)/p7i.vogel.de/wcms/95/e5/95e50766b5de0f4b7ca74d1db2524bf2/0132321286v2.jpeg "Humanoide Roboter: Roboter, die vor wenigen Jahren noch eine Vision waren, sind heute dank KI, maschinellem Lernen und Echtzeit-Datenverarbeitung Realität. (Bild: Pete Linforth)")
:quality(80)/p7i.vogel.de/wcms/81/6d/816dfab525864f08b3569676daffb31f/0132240748v2.jpeg "Workflow des Ablaufs einer GitLost-Attacke. (Bild: Noma Security)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/30/19/30192d4799534c8e823986e895916cf4/0131682946v1.jpeg "Der Autor: Stig Martin Fiskå ist Global Head of AI for Good bei Cognizant und Leiter der Cognizant Ocean Business Group (Bild: Cognizant)")
:quality(80)/p7i.vogel.de/wcms/d6/42/d64261f97ff8ea94ab4f7e2f5afb1869/0132187522v1.jpeg "KI-Agenten stimmen Abläufe in Unternehmen zunehmend selbstständig ab – umso wichtiger sind übergeordnete Governance-Regeln und Berechtigungskonzepte, wie sie auch für menschliche Mitarbeitende gelten. (Bild: © Andrea Danti - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
BigQuery, Cloud Data Flow, Dataproc So funktioniert Big Data mit der Google Cloud Platform
Big Data erfordert leistungsfähige Server und Anwendungen, die eine große Menge an Daten effizient verarbeiten können. Dafür eignen sich Cloud-Dienste wie die Google Cloud Platform hervorragend.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
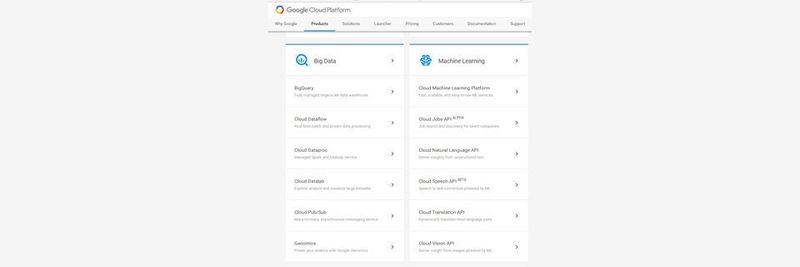
Google bietet mit seiner Google Cloud Platform, ebenso wie Amazon mit den Amazon Web Services (AWS) oder Microsoft mit Azure, umfassende Cloud-Dienste an – auch für Big Data. Wie Microsoft und Amazon bietet Google einen kostenlosen Testzeitraum für seine Cloud Platform an . In der Testversion lässt sich die Google Cloud Platform 60 Tage kostenlos nutzen, beziehungsweise bis die 300 Euro kostenloses Volumen aufgebraucht sind.
Die Google Cloud Platform bietet nicht nur Funktionen für Big Data, sondern auch für das Internet of Things (IoT). Vorteil der Google Cloud Platform ist vor allem, dass Google hier die gleiche Infrastruktur nutzt, die auch für seine anderen Dienste genutzt werden, zum Beispiel Google Mail, die Google-Suche oder YouTube. Außerdem stellt Google zahlreiche Entwicklerwerkzeuge zur Verfügung, mit denen sich eigene Apps erstellen lassen, die wiederum die verschiedenen Dienste in der Google Cloud Platform nutzen.
Hadoop, Spark, Pig und Hive in der Google Cloud Platform nutzen
Neben eigenen Big-Data-Diensten, wie zum Beispiel BigQuery, Cloud Dataflow, Datalab und Cloud Pub/Sub, lassen sich auch Dienste wie Spark und Hadoop direkt aus der Google Cloud Platform heraus nutzen. Google Cloud Dataproc bietet die Möglichkeit, bekannte Dienste wie Hadoop, Spark, Pig, Hive und andere anzubinden. Die Erstellung von Clustern zur Nutzung dieser Apache-Dienste erfolgt in der Weboberfläche der Google Cloud Platform. Bei Google Dataproc handelt es sich also um den mächtigsten Bereich der Big Data Tools der Google Cloud Platform.
Der Vorteil dabei ist die sehr flexible Skalierbarkeit der Google Cloud Platform. Außerdem lassen sich als Datenquellen auch Quellen außerhalb der Google Cloud Platform anbinden, das gilt auch für Dienste zur weiteren Verarbeitung von Daten. Die Größe und Leistung der Clusterknoten lässt sich jederzeit anpassen, das gilt auch für das Hinzufügen weiterer Clusterknoten.
Big Query – Enterprise Cloud Data Warehouse
Bei BigQuery handelt es sich um ein Enterprise Data Warehouse, das enorme Datenmengen bis in den Petabyte-Bereich verarbeiten kann. Zur Analyse lassen sich auch SQL-Befehle verwenden. Der Vorteil der Umgebung besteht darin, dass die Lösung keinerlei Infrastruktur zur Verfügung stellt. Das heißt, es sind keine Datenbank-Administratoren notwendig und keine virtuellen Server, die verwaltet werden müssen. Der Fokus der Lösung ist klar auf die Verarbeitung der Daten gelegt. Mit BigQuery lassen sich Big-Data-Analysen erstellen. Davon profitieren auch kleine Unternehmen, nicht nur große Konzerne.
Google gibt an, dass sich Daten im Terabyte-Bereich in wenigen Sekunden analysieren lassen, während Daten im Petabyte-Bereich etwas mehr Zeit erfordern, um analysiert zu werden. Die Daten werden automatisch verschlüsselt. Außerdem lassen sich auch Replikationen durchführen. Für die Verarbeitung der Daten lassen sich auch Berechtigungen vergeben. Dazu stehen verschiedene Rollen zur Verfügung, die Administratoren den Anwendern zuweisen können, um Daten zu verarbeiten. Für die Authentifizierung können Unternehmen hier auch auf das Google Cloud Identity & Access Management System setzen. Außerdem bietet Google auch die Speicherung der Daten in europäischen Rechenzentren an.
Für die Speicherung der Daten können Unternehmen entweder den Datenspeicher in der Google Cloud Platform nutzen oder die Daten zu BigQuery streamen. Auch beim Streamen lassen sich die Daten in Echtzeit verarbeiten. Die Kosten, die bei der Verarbeitung anfallen, lassen sich im Webportal deckeln.
Cloud Dataflow – Batchverarbeitung nutzen
Bei Cloud Dataflow handelt es sich um eine Managed-Service-Lösung in der Google Cloud Platform, die für das Data Processing – inklusive ETL und Batchverarbeitung – geeignet ist. Ressourcen-Management oder die Optimierung der Leistung ist bei diesem Dienst nicht notwendig, da auch hier alle Ressourcen direkt aus der Cloud zur Verfügung gestellt werden. Mit dem Unified Programming Model bei Cloud Dataflow lassen sich umfassend Daten verarbeiten. Für die Programmierung des Dienstes kann zum Beispiel auch auf das Apache Beam SDK gesetzt werden. Cloud Dataflow arbeitet mit Cloud Storage, Cloud Pub/Sub, Cloud Datastore und Cloud Bigtable genauso zusammen, wie mit BigQuery.
Cloud Datalab – Datenvisualisierung
Datalab baut auf Jupyter auf, auch als „IPython“ bekannt. Der Clouddienst Datalab steht aktuell als Beta-Version zur Verfügung. Mit dem Dienst lässt sich Big Data analysieren und visualisieren, zum Beispiel Geodaten auf einer Weltkarte. Auch dieser Dienst arbeitet mit den anderen Produkten in der Google Cloud Platform umfassend zusammen. Die Analyse der Daten aus dem Datenspeicher in Google, lokalen Datenspeichern oder Datenspeicherns aus VMs, die auf Basis von Google Computer Engine zur Verfügung gestellt werden, sind problemlos möglich. Als Abfragemodell stehen Python, SQL und JavaScript zur Verfügung, zum Beispiel um BigQuery-Daten mit einzubeziehen.
Sobald die analysierten Daten optimal transformiert wurden und das Analysemodell zufriedenstellend implementiert wurde, lassen sich die Daten mit einem Mausklick zu BigQuery übertragen und weiternutzen. Auch Machine-Learning-Modelle lassen sich dadurch umsetzen. Zur Visualisierung lassen sich Google Charts oder matplotlib nutzen.
Cloud Pub/Sub – Daten in Echtzeit streamen
Mit Cloud Pub/Sub lassen sich Daten und Nachrichten in Echtzeit direkt aus der Cloud streamen. Mit dem Clouddienst lassen sich diese Informationen hin- und herschicken. Dazu werden natürlich auch zahlreiche Anwendungen unterstützt. Cloud Pub/Sub arbeitet dazu natürlich nicht nur mit Produkten in der Google Cloud Platform zusammen, sondern auch mit anderen Clouddiensten oder Anwendungen, die Unternehmen im eigenen Netzwerk zur Verfügung stellen. Cloud Pub/Sub setzt dabei auf die gleichen Techniken, die auch die Google-Suchmaschine einsetzt, aber auch Google Mail oder Google Ads. Google gibt den maximalen Verarbeitungsumfang mit einer Million Nachrichten pro Sekunden an. Die Daten lassen sich zur Übertragung natürlich auch verschlüsseln. Außerdem bietet Cloud Pub/Sub auch eine Replikation des Datenspeichers an. Google Cloud Dataflow verarbeitet die Daten in Echtzeit, die Cloud Pub/Sub streamt.
Zusammenarbeit mit Compute und Storage
Die verschiedenen Big-Data-Produkte arbeiten allesamt mit den anderen Produkten der Google Cloud Platform zusammen. So lassen sich die Daten, die verarbeitet werden sollen, nicht nur direkt im Google-Datenspeicher ablegen, zum Beispiel Cloud Storage, Cloud SQL oder Cloud Big Table, sondern auch in Datenbanken, die zum Beispiel auf virtuellen Servern installiert werden, die wiederum mit Compute in der Google Cloud Platform erstellt wurden.
(ID:44686736)
:quality(80)/p7i.vogel.de/wcms/7f/fb/7ffb6b273b3f67241d2e365e221d1ca4/0127694438v1.jpeg "Microsoft Fabric lässt sich über ein Dashboard steuern und komplett aus der Cloud 60 Tage kostenlos nutzen. (Bild: T. Joos)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")