
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/be/44/be44598197334ca0f319a1d93f235877/0131874766v1.jpeg "Viele KI-Systeme stoßen schnell an Grenzen, sobald reale Patienten und Behandler, unvollständige Daten, unterschiedliche IT-Systeme ins Spiel kommen, meint Robert Ranisch, Professor für Medizinische Ethik an der Universität Potsdam. (Bild: Canva / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/54/63/54636cb4c3049adcffc96869579069bb/0131948039v1.jpeg "Die reifsten KI-Anwender melden laut Box-Report nicht weniger, sondern mehr Datenvorfälle, weil sie ihre Agenten-Landschaft überhaupt überblicken. (Bild: Box)")
:quality(80)/p7i.vogel.de/wcms/f8/f6/f8f63ea1acab816895c1450c8a056fe1/0131911243v2.jpeg "Cisco sieht in KI eine große Chance für den Standort Deutschland – vorausgesetzt, Unternehmen verbinden Innovationswillen mit der richtigen Infrastruktur. (Bild: Cisco)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Spaltenorientierte Datenbanken und In-Memory Big Data im Supply Chain Management
Big Data wird gemeinhin ungeordnetes Datenvolumen beschrieben, dessen Erfassung, Speicherung, Verwaltung und Analyse eine normale Datenbank nicht bewältigen kann. Allerdings geht es nicht nur um die Menge der enthaltenen Informationen, sondern auch darum, diese aus verschiedenen Blickwinkeln zu strukturieren und zu analysieren.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
Big Data bringt nicht nur in Bereichen wie Marketing oder Online-Business Vorteile. Auch traditionelle Zweige, wie Supply Chain Management (SCM), können von strukturierten Big-Data-Lösungen profitieren durch:
- 1. Mehr Datentransparenz
- 2. schnelleres, genaueres Leistungs-Monitoring und Ausnahmenidentifizierung
- 3. Automatisierte Algorithmen
- 4. Schnellere, genauere Entscheidungsfindung,
- 5. Akkurate Analysen und Auswertungen
Die Datenmengen in den Firmen wachsen und Unternehmen müssen flexibler und schneller reagieren, um sich zu behaupten. Sie benötigen mehr Geschwindigkeit bei der Datenanalyse. Big Data kann Gewinnmargen um fünf bis 35 Prozent steigern, aber um riesige Datenmengen effektiv einzusetzen und zu analysieren, braucht die Technologie zusätzliche Fähigkeiten: beispielsweise eine spaltenorientierte Datenbank und In-Memory-Computing.
Spalten- vs. zeilenorientierte Datenbank
Es gibt zwei Optionen, eine Datenbank einheitlich in einem eindimensionalen Datenstrom anzuordnen: Zeilen- und spaltenorientierte Datenbanken. Um zu verstehen, warum Big-Data-Lösungen zur Optimierung der Supply Chain von einer spaltenorientierten Datenbank profitieren, müssen die Datenbanken zunächst verglichen werden:
Zeilenorientierte Datenbanken
Herkömmliche, relationale Datenbanken sind zeilenorientiert. Zeilen werden in der Datenbanktabelle der Reihe nach geschrieben. Das erlaubt ein schnelles Schreiben und ist daher sinnvoll für Anwendungen, die viele oder alle Spalten zugleich abrufen müssen, wie Datensätze mit personenbezogenen Daten, die bei Abruf nebeneinander erscheinen. Beispielsweise Name, Anschrift, Geburtsdatum, Telefonnummer und so weiter. Das Auslesen von zeilenorientierten Datenbanken dauert allerdings lange, weil alle Zeilen hintereinander gescannt werden.
Zeilenorientierte Datenbanken sind daher für OLTP-Systeme (Online Transactional Processing Systems) wie einem ERP geeignet, aus dem ständig viele Informationen in die Datenbank eingespeist werden müssen. Für häufiges Beschreiben brauchen spaltenorientierte Datenbanken mehr Zeit, sind aber beim Abrufen von Daten schneller.
Spaltenorientierte Datenbanken
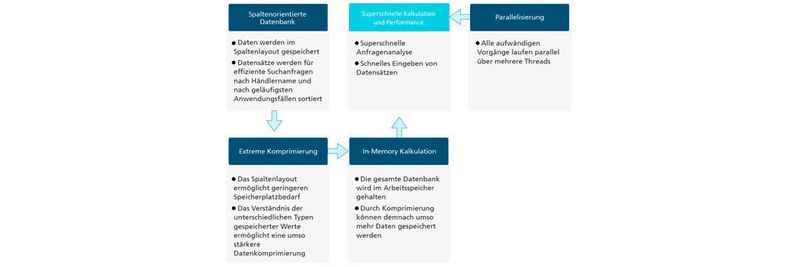
Spaltenorientierte Datenbanken schreiben Datensätze Spalte für Spalte, also zuerst alle Zeilen der ersten Spalte, dann alle Zeilen der zweiten Spalte, etc. Das ist sinnvoll für die Analyse vielspaltiger Tabellen, deren Daten nicht gleichzeitig abgerufen werden müssen. Abfragen laufen bis 20-mal schneller als bei zeilenorientierten Datenbanken, da nur die für die Auswertung nötigen Spalten und nicht alle Zeilen durchsucht werden müssen.
Das ist nützlich bei OLAP-Systemen (Online Analytical Processing Systems). Daten in spaltenorientierten Datenbanken lassen sich stark komprimieren, weil Werte desselben Datentyps nebeneinander hinterlegt sind – in zeilenorientierten Datenbanken liegen Werte verschiedener Datensätze nebeneinander, weshalb das nicht möglich ist.
Kurzum: Zeilenbasierte Datenbanken sind zum Abruf vieler verschiedener Spalten oder einzelner Zeilen geeignet. Spaltenbasierte Datenbanken sind besser, wenn viele Zeilen oder einzelne Spalten benötigt und Änderungen an einzelnen Datensätzen durchgeführt werden. Spaltenorientierte Big-Data-Datenbanken, wie Relex, können Millionen Datensätze effizient komprimieren und Kalkulationen In-Memory, also im RAM-Speicher, durchführen. Sie berechnen riesige Datenmengen 100-mal schneller als herkömmliche Systeme. Fortschrittliche Algorithmen und Analysetools verwandeln Daten in eine mächtige Quelle, um bessere Prognosen für Warenauffüllungen anzubieten.
Relex‘ integrierte Big-Data-Lösung
Eine Kenntnis der verschiedenen Datenwerte ermöglicht eine mindestens 10-mal stärkere Komprimierung als bei zeilenorientierten Datenbanken. Benötigt eine herkömmliche relationale Datenbank 100 Gigabyte Speicherplatz, nimmt die eigens entwickelte Relex-Datenbank nur zehn Gigabyte Speicherplatz ein.
Relex‘ innere Architektur besteht aus mehreren Threads, wodurch diverse zeitintensive Arbeitsvorgänge parallel laufen können. Je mehr Threads parallel laufen, desto schneller werden die Daten wie Auswertungsmöglichkeiten der Suchanfragen, Ladezeiten oder Kalkulationen verarbeitet.
In-Memory-Technologie
Die In-Memory-Technik erlaubt dank der starken Komprimierung, die Daten im Arbeitsspeicher abzulegen. Suchanfragen der Datenbank werden im RAM bearbeitet. Das vermeidet zeitintensives Hin- und Herschieben der Daten zwischen ERP und Festplatte, was erneut zu Leistungserhöhung führt und Zeit spart, weil der gesamte Lese-Schreib-Prozess entfällt. In-Memory-Computing mithilfe von Relex ist fähig, Informationen für 50 Millionen SKUs (Stock Keeping Units, Bestandseinheiten/Artikelnummern) in zwei Stunden zu verarbeiten. Prognosen können theoretisch für mehrere Jahre vorgenommen werden, aber durch ein sich ständig änderndes Sortiment ist es sinnvoll, nur bis zu einem halben Jahr im Voraus zu planen.
Zum Beispiel können Disponenten Möglichkeiten für kommende Kampagnen durch das Durchspielen von Hypothesen für alle möglichen Permutationen analysieren. Historische Daten des Kampagnenprodukts oder, falls es diese nicht gibt, Daten von vergleichbaren Produkten, ermöglichen Prognosen für jede Filiale, jeden Ort, jeden Rabatt, saisonale Kombination und weitere Variationen. Die in Sekundenschnelle generierten Ergebnisse gewähren Einblicke in Bereiche wie den während Kampagnen erzielten Profit oder die laufende Umsatzsteigerung. So lassen sich potenzielle Engpässe und Bedarfsspitzen rechtzeitig kennzeichnen, sodass Unternehmen reagieren können.
Die SCM-Software von Relex besitzt eine integrierte, speziell angefertigte Datenbank. Das ist bisher unüblich. Datenbank und Anwendung gelten meist als getrennte Lösungen, die oft von unterschiedlichen Anbietern stammen. Die Datenbank dient als Server, an die die Anwendungssoftware gekoppelt wird. Das verkompliziert jedoch die Kommunikation zwischen Anwendung und Datenbank und führt zu Anwendungsgrenzen von Client-Server-Modellen. Um die benötigten Antworten zu erhalten, müssen präzise Anfragen gestellt werden. Die Antwort besteht oft in kurzen Zusammenfassungen einer begrenzten Anzahl von Dateien oder nur Kopien dieser – eine direkte Kommunikation ist nicht ohne weiteres möglich.
SQL-Erweiterungen
Die meisten Datenbankserver erlauben eine Umgehung der Beschränkung der SQL-Sprache über Erweiterungen. Diese sind häufig in anbieterspezifischer Sprache geschrieben, sodass eigentlich von der Anwendung verarbeitete Daten nun über die Datenbank laufen. Damit findet die Verarbeitung näher an der Datenquelle statt und das Hin- und Herschieben von Daten zwischen Datenbank und Anwendung wird minimiert. Aber es gibt Einschränkungen: Die nutzerspezifische Sprache ist kein adäquates Pendant zur vollwertigen Programmiersprache und schränkt Datenzugriffsmuster ein.
Relex erlaubt einen direkten Zugriff auf die Datenbank und das Arbeiten mit ihr. Das vermeidet das Hin- und Herschicken von Daten und verbessert zusätzlich die Performance. Datenbank und Anwendung sind eine einzelne, nahtlos ineinander übergehende Software. Darum laufen Prozesse auf niedrigem Kapazitätslevel und häufige Anfragen werden bei der Datenspeicherung direkt einkalkuliert.
Eine individuelle Anpassung macht Aufbau und Entwicklung der Software anspruchsvoll und zeitintensiv, dafür bietet die Lösung eine überdurchschnittlich hohe Leistung:
- Ca. fünf Milliarden Prognosen pro Stunde.
- Ca. eine Milliarde Transaktionen pro Stunde hochladen
- Eine Million Produkte in 1 Sekunde nach Lieferbarkeit sortieren
- Berechnung von 50 Mio. SKUs in zwei Stunden
(ID:44397266)
:quality(80)/p7i.vogel.de/wcms/34/a2/34a2d02781eaabef906c308dd135c049/0130541481v1.jpeg "KI kann helfen, konsistente Datanbankschemata zu erstellen und weiterzuentwickeln. (Bild: © CreativeIMGIdeas - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")