
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/b3/d4b39c1c2d46f3ae6e49ed80f2ecd9d1/0132006976v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/e2/bae2c84df6310701a01325e9fbfd96d6/0132099756v1.jpeg "Simon Ritter, Deputy CTO bei Azul, warnt: Vibe Coding produziere Code, der tue, was das Modell verstanden habe – nicht, was gemeint war. (Bild: Azul)")
:quality(80)/p7i.vogel.de/wcms/b5/f4/b5f489601994978d1730f20e206002f7/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Internet of Things Relationale und NoSQL-Datenbanken wachsen zusammen
Denkt man über die Möglichkeiten nach, die das Internet der Dinge (Internet of Things, IoT) in Aussicht stellt, fallen einem gleich unterschiedlichste Lösungsplattformen und Datentechnologien ein. Was man aber in der Regel nicht ganz oben auf der Liste findet, ist eine relationale Datenbank.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
Stattdessen scheint das Potenzial einer vernetzten Welt voller intelligenter Geräte, die miteinander kommunizieren, nach völlig neuen Lösungen und Wegen zu verlangen, um den wachsenden Strom immer neuer, teils unstrukturierter Datentypen – „Big Data“ – effizient nutzen zu können. Solche Lösungen werden meist mit dem Schlagwort „NoSQL“ in Verbindung gebracht.
Über all diese Überlegungen sollte aber nicht vergessen werden, dass sich die Grundlagen trotz des IoT-Siegeszugs und vieler innovativer NoSQL-Lösungen nicht ändern, egal wie viele neue Geräte plötzlich die Datenübertragung via Internet beginnen. Daten müssen auch weiterhin in einem breiteren Kontext verstanden werden – ob sie durch einen intelligenten Kühlschrank, Smartphone-Anwendungen oder städtische Bahnübergänge erzeugt werden. Sowohl CEOs als auch Data Scientists müssen sich immer noch damit beschäftigen, wie vom Internet der Dinge erzeugte Daten mit anderen Unternehmensdaten im Zusammenhang stehen.
Mehr heißt nicht immer besser
Die schiere Explosion mobiler und maschinengenerierter Datenströme sowie von Datenströmen aus den sozialen Medien sorgt bereits dafür, dass Datenspezialisten ihre Lösungsportfolios erweitern. Ein typisches Rechenzentrum bietet heute in puncto Datenmanagement-Technologien ein Flickenteppich-Bild: Von relationalen Datenbanken für den professionellen Unternehmenseinsatz über eigenständige reine NoSQL-Nischenlösungen für einige wenige Spezialaufgaben bis hin zu spezialisierten Erweiterungen – das Arsenal zur Verwaltung von Daten ist vielfältiger geworden.
NoSQL-Lösungen wie MongoDB und Hadoop stellen in so einem Umfeld zwar ein potentes Werkzeug für unstrukturierte Daten dar, dem aber meist die komplexen transaktionalen Fähigkeiten von relationalen-Datenbanken fehlen, um die Daten auch effektiv den eigenen Bedürfnissen entsprechend zu bearbeiten. Außerdem besitzen viele NoSQL-Lösungen keine ACID-Konformität – das bedeutet ein großes Risiko für die Konsistenz der Datensätze und kann Datensilos erzeugen.
Auf der anderen Seite wird immer noch eine leistungsfähige, robuste relationale Kern-Datenbank benötigt, mit der sich traditionelle strukturierte Unternehmensdaten zuverlässig und sicher – also ACID-konform – verwalten lassen. In solchen Datenbanken fehlten aber meist die speziellen Features zur Bewältigung der unstrukturierten neuen Datentypen, die das IoT dem modernen Rechenzentrum zuführt.
Anwender wollen eine Lösung für alle Datentypen
Die kürzlich von Forrester Consulting veröffentlichte Fallstudie „Relational Databases are Evolving to Support New Data Capabilities“ fasst diese Umstände in konkrete Zahlen: Mehr als die Hälfte der Befragten gaben an, nicht verhindern zu können, dass Entwickler neue Applikationen auf separaten NoSQL-Datenbanken einsetzen. Gleichzeitig sagten 42 Prozent, dass sie Probleme mit dem Management eben solcher in ihren Infrastrukturen eingesetzten NoSQL-Datenbanken haben.
Für 85 Prozent der Befragten sind Planungs-, Budgetierungs- und Prognose-Daten für die allgemeine Geschäftsstrategie am wichtigsten, 72 Prozent nannten hier auch transaktionale Daten aus Business-Applikationen. Solche Daten werden normalerweise durch die Anwendung relationaler Qualitäten aufgewertet, was für den Einsatz einer relationalen Datenbank als Standardlösung im Unternehmen spricht.
Gleichzeitig gaben über die Hälfte der Befragten an, dass auch neue Datentypen eine wichtige Rolle spielen. Daher wünscht sich mit 78 Prozent die überwiegende Mehrheit aller befragten Studienteilnehmer eine gemeinsame Lösung, die sowohl strukturierte als auch unstrukturierte Datentypen unterstützt.
Das Getrennte verbinden
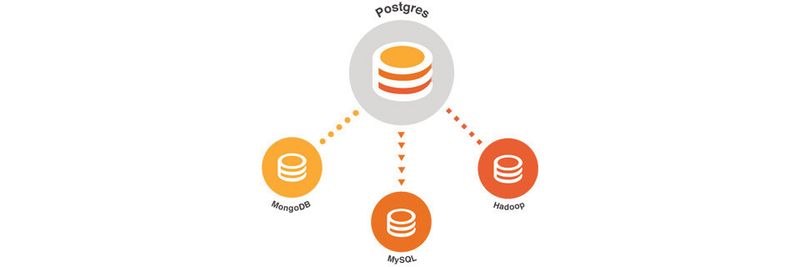
Die große Herausforderung, die sich aus der IoT-Entwicklung für das Rechenzentrum ergibt, ist damit die Integration von Datentypen aus verschiedensten Quellen – erst dann lassen sie sich wirklich analysieren und verstehen sowie gemeinsam mit bestehenden Daten aus langjährigen Lösungen nutzen. Mit anderen Worten: Daten aus Hadoop-Clustern oder MongoDB-Implementierungen müssen mit relationalen Tabellen in Einklang gebracht werden, um das komplette Gesamtbild zu sehen oder aussagekräftige Momentaufnahmen zu erhalten.
FDWs – die flexiblen Datenintegratoren
Das Open-Source-basierte relationale Datenbankmanagementsystem (DBMS) PostgreSQL besitzt bereits die erforderliche Technologie zur Einbindung unterschiedlichster Datenquellen und entwickelt so die Integration traditioneller strukturierter sowie unstrukturierter Datentypen weiter. Denn ein Feature, mit dem sich künftig die Datenherausforderungen des Big-Data-Zeitalters vor dem Hintergrund der fortschreitenden IoT-Entwicklung lösen lassen könnten, sind die sogenannten Foreign Data Wrappers (FDW).
Mit ihnen können sich Daten aus unterschiedlichsten Quellen wie MongoDB, Hadoop und MySQL in Postgres integrieren. Sie verbinden externe Datenspeicher mit PostgreSQL-Datenbanken, sodass Nutzer SQL-Abfragen für externe Datenquellen lesen und schreiben können, als wären sie Teil der eigenen Postgres-Tabelle. So lassen sich die Grenzen zwischen Datensilos innerhalb von heterogenen Datenbank-Landschaften aufbrechen und Anwendern wird ein ganzheitlicher Einblick in ihre Daten gewährt.
Gemeinsam mit dem JSON-Datentyp für NoSQL-Funktionen erlauben es FDWs, das relationale DBMS als zentralen Datenbank-Hub im Unternehmen zu betreiben. Mit JSON / JSONB werden unstrukturierte und semi-strukturierte Implementierungen unterstützt, deren Datentypen erkannt und die Daten mit relationalen Tabellen kombiniert. Da dabei aus einer Postgres-Tabelle heraus gearbeitet wird, geschieht das unter Einhaltung der ACID-Grundsätze relationaler Technologien sowie zentraler Regeln der Geschäftsabwicklung und der Logik.
Dieser Ansatz aus dem Open-Source-Umfeld zeigt beispielhaft, wie sich unterschiedlichste Datenbanktechnologien für ein einheitliches Datenumfeld zusammenführen lassen. In Zukunft können Unternehmen sowohl ihre herkömmlichen als auch neuen Datentypen effizient bearbeitet und damit zu jeder Zeit die Konsistenz und Sicherheit ihrer Unternehmensdaten gewährleisten.
Evolution statt Revolution
Die relationale Datenbank wird neben den vielen neuen NoSQL-Lösungen weiterhin eine zentrale Rolle spielen. Denn ACID-Konformität, Datenkonsistenz und -sicherheit sind und bleiben auch in Zukunft unverzichtbare Grundpfeiler jeder Unternehmensdatenbank, egal wie viele unterschiedliche Datentypen es zu verarbeiten gilt. Schöpft das relationale DBMS sein Potential zur Weiterentwicklung seiner Funktionen und zur Integration fremder Datenquellen weiter aus, kann es sogar zum sprichwörtlichen neuralgischen Knoten des Rechenzentrums im Zukunftszeitalter des Internet der Dinge werden.
Unternehmen profitieren dabei neben der umfassenden Übersicht über wirklich all ihre Daten auch von interessanten Spareffekten, denn die zeit- und kostenintensive Verwaltung vieler unterschiedlicher, voneinander getrennter Spezial-Datenbanken entfällt. Entscheidende Ressourcen und Budgets werden so dann wieder für Kernaufgaben im Unternehmen wie strategische Investitionen und erfolgsentscheidende Transformationen frei.
* Sascha Scholing ist Sales Director für Zentral- und Osteuropa und die Türkei bei EnterpriseDB.
Artikelfiles und Artikellinks
Link: EnterpriseDB im Web
(ID:43525375)
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/38/6a/386a83f6075ab241f8df2516189861b5/0125557742v1.jpeg "Denodo DeepQuery – eine KI-Lösung, die komplexe Geschäftsfragen durch Echtzeit-Analysen über alle Unternehmensdaten hinweg beantworten möchte. (Bild: Denodo)")