
:quality(80)/p7i.vogel.de/wcms/49/c6/49c665060846beb129ae679a2918c61a/0132163773v1.jpeg "Wer trägt die Verantwortung? Echte Datensouveränität bei KI und Cloud bedeutet, die Kontrolle über sensible Daten sicher in der eigenen Hand zu behalten. (Bild: © Lustre - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/6b/7a/6b7a7ae072bb7ab964cde4d302755ceb/0124814981v1.jpeg "Der European Blueprint soll bis Ende 2026 festlegen, welche europäischen Organisationen Zugang zu fortgeschrittenen KI-Modellen erhalten. Verbindliche Pflichten für Anbieter außerhalb der EU entstehen daraus nicht. (Bild: Vergiliy - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/26/81/2681098961a1b8010bbf241f3e914891/0132345254v1.jpeg "Räumlich-zeitliche Identifikatoren sollen fragmentierte Datenbestände systemübergreifend nutzbar machen. Nach Angaben von The Green Bridge ist die Grundlage für KI-Anwendungen und Automatisierung. (Bild: Unsplash-Steve A Johnson)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/d9/db/d9dbfbca0f9ff41469a40d883f8e5cb5/0132438388v1.jpeg "Mit Version 9.5 rückt Denodo die semantische Schicht ins Zentrum der Plattform und positioniert sich im Wettbewerb um die Kontextversorgung von KI-Agenten. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b8/76/b8761191f739895263a4bdbfcaf9c5b2/0132429694v1.jpeg "Mit dem Wechsel von assistierenden zu ausführenden Agenten verlagert sich der Kontrollbedarf im Produktdatenmanagement. Entscheidend wird die Nachvollziehbarkeit einzelner Attributänderungen. (Bild: Akeneo)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")
:quality(80)/p7i.vogel.de/wcms/78/9a/789af78a62e28f5e8cc995570d48b822/0130655525v1.jpeg "SupplyX wollte sein Transportmanagement-System ersetzen und fand den Engpass in den Daten. Ein Praxisbericht über die Datenbasis produktiver KI. (Source: © MAGNIFIER - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/9f/fe/9ffe3d484cf6fdc7ea137128b15f60a9/0131577982v1.jpeg "Im Einsatz für den Artenschutz: Ein WWF-Ranger durchstreift den Regenwald. Das geplante Wildlife Protection Operations Center soll solche Einsätze KI- und datenbasiert optimieren. (Bild: Emmanuel Rondeau / WW_US)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/e9/34/e9342418bd8081921fdd2fc2fc4be51b/0132359705v2.jpeg "Einsatz auf dem Acker: Wie sich humanoide Systeme mit schweren landwirtschaftlichen Maschinen vernetzen lassen, wird in Ilmenau erprobt. (Bild: Fraunhofer IOSB)")
:quality(80)/p7i.vogel.de/wcms/57/b8/57b8da3ba179d80f10073e7541f8b68f/0132491632v1.jpeg "Die Brücke vom Trainings-Cluster über die Simulation bis zum Roboter im Feld hat Lücken: Physical AI scheitert seltener am Modell als am Workflow. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f9/43/f943ca681620e9eb521fea039168a2fe/0132555049v1.jpeg "Die Konferenz T3 – Transform The Tomorrow diskutiert am 1. und 2. Dezember 2026 Strategien, wie Unternehmen sich zukunftssicher aufstellen können. (Bild: © Vogel Corporate Solutions / AdobeStock 1280236166, Oksana)")
:quality(80)/p7i.vogel.de/wcms/95/e5/95e50766b5de0f4b7ca74d1db2524bf2/0132321286v2.jpeg "Humanoide Roboter: Roboter, die vor wenigen Jahren noch eine Vision waren, sind heute dank KI, maschinellem Lernen und Echtzeit-Datenverarbeitung Realität. (Bild: Pete Linforth)")
:quality(80)/p7i.vogel.de/wcms/81/6d/816dfab525864f08b3569676daffb31f/0132240748v2.jpeg "Workflow des Ablaufs einer GitLost-Attacke. (Bild: Noma Security)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/30/19/30192d4799534c8e823986e895916cf4/0131682946v1.jpeg "Der Autor: Stig Martin Fiskå ist Global Head of AI for Good bei Cognizant und Leiter der Cognizant Ocean Business Group (Bild: Cognizant)")
:quality(80)/p7i.vogel.de/wcms/d6/42/d64261f97ff8ea94ab4f7e2f5afb1869/0132187522v1.jpeg "KI-Agenten stimmen Abläufe in Unternehmen zunehmend selbstständig ab – umso wichtiger sind übergeordnete Governance-Regeln und Berechtigungskonzepte, wie sie auch für menschliche Mitarbeitende gelten. (Bild: © Andrea Danti - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
NoSQL NoSQL-Datenbanken im Vergleich
NoSQL-Datenbanken wurden aus der Notwendigkeit heraus entwickelt, große, unterschiedliche Mengen von Dimensionen wie Raum, Zeit und Lokation auf möglichst effiziente Weise zu speichern und zu verarbeiten. Mittlerweile sind sie die unabdingbare Alternative zu relationalen SQL-basierten Datenbanken. Doch nicht jede NoSQL-Datenbank eignet sich für jeden Zweck. Tatsächlich sind die meisten sogar recht spezialisiert.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
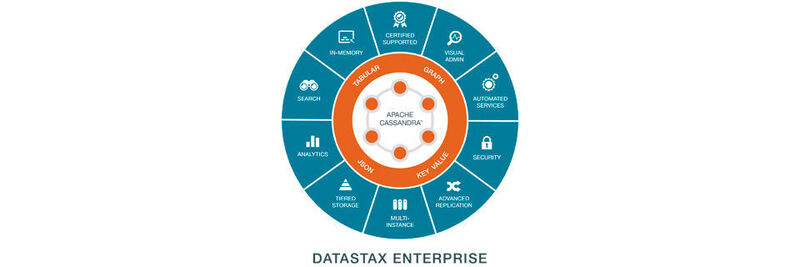
„NoSQL“ steht mittlerweile für „not-only SQL“, wobei SQL (Structured Query Language) den verbreiteten Standard bildet, der vor allem in relationalen Datenbanken wie Oracle oder in Hadoop und Spark verwendet wird. Damit betrifft SQL nicht die Art der Datenablage – in einer Tabelle oder einem verteilten Filesystem – sondern vielmehr die Abfrage und Auswertung dieses Datenspeichers mithilfe einer Abfragesprache. NoSQL bedeutet, dass nicht nur SQL unterstützt wird, sondern, nach Jahren der Weiterentwicklung von NoSQL-Datenbanken, auch andere Abfragemethoden wie N1QL, JSON oder Skriptsprachen.
Typen der Datenablage und Abfrage
Zunächst ist es von Vorteil, die verschiedenen Typen der Dateiablage in NoSQL-Datenbanken zu kennen. Sofort wird klar, wie stark sich die Produkte in ihrer Basistechnologie unterscheiden.
- Graph-Datenbanken: Sie bildet Beziehungen der Daten untereinander ab, etwa zwischen Followern bei Twitter; Stärke: Beziehungen und Netzwerke. Als Beispiele können Neo4j (s. u.) und SAP Hybris dienen.
- Dokumenten-Datenbanken: Die zu speichernden Objekte werden als Dokumente mit möglicherweise verschiedenen Attributen gespeichert. Das ist sinnvoll bei Blogs und Content-Management-Systemen oder Wikis. Für Web-Dokumente wird heute meist JSON verwendet. Die Attribute oder „tags“ lassen sich leicht in eine Tag-Cloud übersetzen. Handelt es sich bei den Dateien um getaggte Bilder, lässt sich darauf mithilfe von Deep Learning eine entsprechende Mustererkennung anwenden.
- Key-Value-Datenbanken: Dieser Datenbank-Typ speichert Daten in Form von Schlüssel-Wertepaaren, wobei der Schlüssel als Index fungiert, mit dem die Datenbank durchsucht wird. Dieser Typ ist recht verbreitet und durch die bewährte Indextechnik auch jedem Datenbank-Administrator und -Programmierer vertraut.
- Multi-Value-Datenbanken: Neben Feldern gibt es auch Wiederholfelder. In einem Datensatz können etwa mehrere E-Mail-Adressen als Wiederholfelder angelegt sein oder die Historie früherer Adressen als gruppierte Wiederholfelder, bestehend aus Straße, Hausnr., PLZ und Stadt, hinterlegt werden.
- Multi-Modell-Datenbank: vereint alle genannten Datenbanktypen inkl. spalten-orientierter Datenbanken wie etwa SAP HANA oder Oracle Ten Times.
Neben den verbreiteten relationalen Datenbanken gibt es noch Objekt-Datenbanken wie Versant oder Gemstone, aber sie spielen wegen des Erfolgs der NoSQL-Datenbanken kaum noch eine Rolle.
Die Beraterfirma Altoros hat die drei NoSQL-Datenbanken Cassandra (Datastax Enterprise 5.0), Couchbase Server 5.0 und MongoDB (v3.4) miteinander verglichen. Es handelt sich um sehr verbreitete und hochskalierbare Enterprise-Produkte, aber sie spiegeln nicht die ganze Bandbreite des NoSQL-Spektrums wider.
Cassandra
Cassandra ist ein partitionierter, zeilenorientierter Datenspeicher, in dem die Zeilen in Tabellen organisiert sind. Anfangs wurde Cassandra bei Facebook von den Amazon-Dynamo-Entwicklern mit dem Ziel entworfen, hohe Verfügbarkeit und lineare Skalierbarkeit zu liefern. Es weist einstellbare Datenkonsistenz und aktive Anti-Entropie-Technologie auf. Schließlich entwickelte sich Cassandra zu einem Apache-Projekt und zum kommerziellen Produkt der Firma Datastax: Cassandra Enterprise. Zusätzlich zur Open-Source-Version stellt die Enterprise-Version noch Volltextsuche, Echtzeit-Analytik, erweiterte Datensicherheit und Auditierungsfunktionen bereit.
:quality(80)/images.vogel.de/vogelonline/bdb/952900/952906/original.jpg "Das Logo der NoSQL-Datenbank Cassandra (Bild: The Apache Software Foundation)")
Cassandra- und NoSQL-Bascis, Teil 1
Grundlagen der NoSQL-Datenbank Apache Cassandra
MongoDB

MongoDB ist eine JSON-Dokument-orientierte NoSQL-Datenbank, die im Web skaliert. Deshalb stellt MongoDB seine Dienste auf Google, AWS und Microsoft Azure bereit. Um die JSON-Dokumente zu handhaben, kann der Nutzer mehrere Tools nutzen; für die Abfrage kann er sich einer Reihe von Sekundärindizes und einer REST-API-basierten Abfragesprache bedienen.
Wenn es um Datenreplikation und Partitionierung geht, bietet die Datenbank laut Altoros entsprechend unabhängig ablaufende Prozesse an. Um die Governance und Datenqualität zu gewährleisten, unterstützt die Version 3.6 nun JSON-basierte DB-Schemata, um so die Gültigkeit neuer Daten zu prüfen. Kürzlich wurden mehrere neue Services und Leistungsmerkmale bereitgestellt. MongoDB Atlas ist ein Monitoring- und Backup-Dienst für Datenbanken, MongoDB Stitch ein Backend-as-a-Service, das Routine-Aufgaben wie Authentisierung oder Payment-Abwicklung abnimmt.
MongoDB erfreut sich erheblicher Verbreitung und Beliebtheit. Rund 30.000 Downloads pro Tag sprechen für sich. Zu den Kunden gehören Bosch und AMADEUS, das Flugreservierungen und -tickets verwaltet. „Der Datenbankhersteller hat weltweit über 3.000 Unternehmenskunden“, berichtet Roman Gruhn, Director of Information Strategy bei MongoDB.
Couchbase Server

Der Couchbase Server, der mittlerweile in der Cluster-basierten Version 5.0 vorliegt, ist eine gemischte NoSQL-Datenbank. Sie unterstützt sowohl JSON-Dokumente als auch eine verteilte Key-Value-Datenbank. Die JSON-Dokumente lassen sich mit einer REST-API-basierten Abfrage auswerten, allerdings wird dabei das Objekt-relationale Mapping (ORM) vermieden, damit die Leistung hoch bleibt.
Um eine hohe Performance zu sichern, operiert Couchbase mit einem Cache auf Objektebene, mit asynchroner Replikation und Datenpersistenz. Auch die Skalierbarkeit steht im Vordergrund, sodass sowohl Scale-out-Verfahren als auch Scale-up-Verfahren realisierbar sind, um Workloads, die hohe Leistungen an Computing, RAM-Nutzung und Storage-Nutzung erfordern, unabhängig voneinander zu unterstützen.

Um JSON-Abfragen zu realisieren, stellt Couchbase 5.0 zusätzlich den auf dem SQL92-Standard entstehenden N1QL-Standard bereit. Er bietet geschäftlichen Applikationen die Möglichkeit, strukturierte Abfragen wie mit SQL zu nutzen, soll aber so leicht zu verwenden sein wie eine Web-Suchmaschine. Das öffnet den Weg zum Einsatz eines BI-Connectors von Tableau, es erlaubt, Big Data mithilfe von Apache Kafka und Apache Spark anzufragen, wobei sich Machine Learning nutzen lässt.

Couchbase 5.0 [PDF] verfügt nun über eine API für das Streaming in Echtzeit und unterstützt OpenShift sowie Container, mit denen es sich auf Ubuntu und RHEL installieren lässt. Auch AWS, Google Cloud Platform und Azure lassen sich für die Bereitstellung nutzen. Der Fokus liegt auf der Performance; moderne Konnektivität stützt den Couchbase-Anspruch, eine Datenbank für die Interaktion mit Kunden (Engagement) zu sein.
Neo4j

Neo4j ist eine reine Graphdatenbank, die nicht erst seit ihrer Erweiterung im Oktober 2017 zu einer Graph-Plattform eine technologische Vorreiterrolle in ihrem Segment einnimmt (neben zwei Millionen Downloads bis 2015). Wie eingangs erwähnt, bilden Graphen, etwa bei Facebook, eine finite Anzahl von Beziehungen ab. In Neo4j wird alles entweder als Kante, als Knoten oder als Attribut gespeichert. Jeder Knoten hat eine beliebige Anzahl von Attributen. Knoten und Kanten können eine Beschriftung (Label) tragen. Beschriftungen können verwendet werden, um die Treffermenge bei Suchen einzuschränken.

Mit der Einführung von Schemata wurde auch das Indexing in der Abfragesprache Cypher eingeführt. Bisher war Indexing nur getrennt von Cypher verfügbar. Cypher ist die deklarative Abfragesprache in Neo4j, mit der sich laut Hersteller selbst komplexe Abfragen realisieren lassen sollen.

Die Daten können beispielsweise soziale Beziehungen, Verbindungen im öffentlichen Nahverkehr, Straßenkarten oder Topologien in Netzwerken sein. Die Anwendungen reichen von künstlicher Intelligenz über Betrugserkennung und Echtzeit-Empfehlungen bis zu Stammdatenmanagement. Die Datenbank weist mehr zehn Millionen Downloads auf und zählt 250 kommerzielle Unternehmen zu ihren Kunden, darunter so große wie eBay und Walmart.

Die Neo4j-Graph-Plattform in der Version 3.3 unterstützt Unternehmen dabei, vernetzte Daten in vollem Umfang zu nutzen und die komplexen Verknüpfungen zwischen Personen, Prozessen und Systemen zu entschlüsseln. „Wir wurden auf Graphdatenbanken aufmerksam, weil wir unsere Daten besser verstehen und mehr Nutzen aus ihnen ziehen wollten. Bei Graphdatenbanken stehen die Beziehungen zwischen den Datenpunkten an allererster Stelle“, so Mark Hashimoto, Director of Engineering bei Comcast.

Die Version 3.3 bietet eine gesteigerte Performance gegenüber v3.2. Dazu tragen erweiterte native Indexe, die Überarbeitung des Cypher Query Interpreters sowie höhere Leistung bei Schreib- und Aktualisierungsvorgängen bei. Neu ist die ETL-Erweiterung. IT-Architekten sollen von der schnellen Datenaufbereitung und dem Import in die Graph-Plattform mit Neo4j ETL profitieren. Die Verbindungen werden nicht nur offengelegt, sondern können auch für eine Reihe von relationalen Quellen und den Rohdatenformaten in Hadoop oder anderen Systemen (wie etwa Spark, siehe Bild) abgebildet werden.
Data Scientists können die Graph-Algorithmen von Neo4j zur Entwicklung ihrer KI-Logik für Projekte nutzen und gleichzeitig mit Cypher for Apache Spark größere Datenmengen in Form von Graphen traversieren. Geschäftskunden können ihre Graphdaten über eine Vielzahl branchenführender Partner (Tableau, Qlik usw.) visualisieren, verstehen, analysieren und untersuchen. Neo4j Desktop ist eine neue Konsole für Entwickler und Benutzer, die die Erforschung und Entwicklung mit einer lokalen, registrierten Version der Neo4j Enterprise Edition und weiterer Plattformkomponenten wie APOC und Algorithmenbibliotheken umfasst.
Empfehlungen
Die Altoros-Experten empfehlen die Verwendung von Couchbase Server oder MongoDB, um semistrukturierte Daten zu speichern und zu verarbeiten, welche vom JSON-Format profitieren können. Da es eine Mobilversion von Couchbase Server gibt, bietet er sich für Mobile-/Offline-Anwendungen an. Cassandra funktioniert hingegen gut für schreibintensive Workloads, wenn auf einem Big Data Level strukturierte Daten und nicht-relationale Daten zu verarbeiten sind.
Couchbase Server
Der Couchbase Server konzentriert sich stärker auf vertikale Skalierbarkeit als seine Rivalen in diesem Vergleich. Sein Leistungsmerkmal der multidimensionalen Skalierbarkeit (sowohl scale-out als auch scale-up) zielt auf entsprechende Kundenszenarien ab, die unterschiedliche Workload-Typen skalieren müssen (entweder mit Key-Value, Indexing oder Volltextsuche). Dieses Grundkonzept lässt sich wohl bis zu Hunderten von Cluster-Knoten skalieren, so die Experten. Der neue Standard N1QL – ausgesprochen „Nickel“ – erweitert SQL um Funktionen für die Abfrage von JSON-Dokumenten. Die Funktion XDCR erlaubt das leichte und zuverlässige Design von Multi-Cluster-Installation mit fortgeschrittenen Topologien.
In diesem Vergleich ist Cassandra ist das einzige Datenbanksystem, das Hochverfügbarkeit und Partitionierungstoleranz anbietet. Durch diese Fähigkeiten ist Cassandra in der Lage, Tausende von Cluster-Knoten zu unterstützen. Zudem ist es gut geeignet, beim Schreiben einen hohen Datendurchsatz an Log-orientierten, wenig wechselnden Daten (z. B. Logfiles) zu ermöglichen. Die Datenbank stellt eine ausreichende Anzahl von einstellbaren Konsistenzgraden, darunter auch solche, die speziell für Installationen an mehreren Rechenzentren entworfen wurden.
Wegen seiner hierarchischen Architektur bekommt MongoDB im Vergleich weniger Punkte. Es bietet eine bescheidene Anzahl von Cluster-Komponenten, wovon jede ihre eigenen Konfigurationsmerkmale aufweist, zusammen mit Master-Slave-Replikation, die von der Datenpartitionierung entkoppelt ist. Die Konfigurationsserver nehmen eine außergewöhnlich bedeutende Rolle ein. All diese Aspekte machen das Bereitstellungs-Design der Datenbank sowie deren Wartung kompliziert. Sie haben bis zu Version 3.5 zusätzliche Anforderungen an den Client-Code gestellt, um Probleme hinsichtlich der Belastbarkeit zu vermeiden. In Version 3.6 wurde das Deployment des Client-Codes geändert, ebenso wie viele weitere Merkmale.
Datenkonsistenz und Flexibilität
Verwendet man MongoDB jedoch auf angemessene Weise, ermöglicht die Datenbank einen hohen Grad an Datenkonsistenz und erlaubt es, Strategien der Partitionierung flexibel umzusetzen. Womit MongoDB Punkte holt, ist seine große Beliebtheit bzw. Verbreitung sowie die Verfügbarkeit von Schulungsmaterial. In einem direkten Vergleich zwischen Couchbase und MongoDB zählt Couchbase sieben Hauptkritikpunkte auf, doch nach Version 3.6 müssen diese nicht mehr unbedingt zutreffen.
Über Neo4j lassen sich die Experten von Altoros nicht aus – dieses Produkt wurde nicht getestet. Die Graph-Datenbank, die von Schweden im Silicon Valley entwickelt wurde, unterscheidet sich jedoch beträchtlich von dem getesteten Trio. Analysten wie Noel Yuhanna von Forrester haben Graph-Datenbanken kürzlich evaluiert.
„Die Einsatzszenarien für Graph-Datenbanken dehnen sich aus, um komplexere Anforderungen zu unterstützen“, so Yuhanna in seiner Zusammenfassung. „Der Markt für Graph-Datenbanken legt an Energie zu.“ Er empfiehlt: „Um eine Digitalisierungsstrategie erfolgreich umzusetzen, sollte man in Graph-Datenbanken investieren.“
(ID:45031524)
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")