
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/b3/d4b39c1c2d46f3ae6e49ed80f2ecd9d1/0132006976v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/e2/bae2c84df6310701a01325e9fbfd96d6/0132099756v1.jpeg "Simon Ritter, Deputy CTO bei Azul, warnt: Vibe Coding produziere Code, der tue, was das Modell verstanden habe – nicht, was gemeint war. (Bild: Azul)")
:quality(80)/p7i.vogel.de/wcms/b5/f4/b5f489601994978d1730f20e206002f7/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Open Source und Linux für die Bereitstellung von Anwendungen nutzen Big-Data-Umgebungen mit Docker virtualisieren
Bei Docker handelt es sich um eine auf Linux basierende Lösung, die Anwendungen im Betriebssystem virtualisieren kann. Anwendungen lassen sich so leichter bereitstellen, da die Container mit den virtualisierten Anwendungen transportabel sind. Wir zeigen die Möglichkeiten und Vorteile von Docker auf.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
Vor allem im Big-Data-Bereich spielen eine große Anzahl verschiedener Anwendungen und zahlreiche Server eine wichtige Rolle. Die Anwendungen sind häufig kompliziert in der Einrichtung und müssen zudem untereinander schnell und effizient Daten austauschen können, um eine effiziente Datenanalyse zu gewährleisten. Der größte Teil der wichtigsten Big-Data-Lösungen basiert auf Open Source Software unter der Apache-Lizenz. Auch Hadoop, der De-facto-Standard im Bereich Big Data, baut auf Linux auf. Aus diesem Grund spielt auch die Virtualisierung in diesem Bereich eine große Rolle.
Allerdings ist es nicht immer sinnvoll, einen virtuellen Server zu installieren und auf diesem Server Anwendungen bereitzustellen. Denn bei allen Vorteilen von virtuellen Servern haben diese auch einige Nachteile: Die Images sind oft recht groß, verbrauchen Ressourcen und benötigen emulierte oder virtualisierte Hardware. Außerdem wird ein komplettes Betriebssystem gebraucht, welches installiert, verwaltet, gesichert und konfiguriert werden will.
Anwendungen ohne VMs mit Docker virtualisieren
Oft ist es effizienter, die Anwendung selbst zu virtualisieren und direkt auf einem Host zu betreiben. Diese Virtualisierung müssen aber sowohl das Betriebssystem als auch die Anwendungen unterstützten. Da die meisten Big Data Tools auf Linux aufbauen, schlummert hier also deutliches Optimierungspotenzial. Linux bietet mit Control-Groups und Ressourcen-Isolation Möglichkeiten, Anwendungen auf Hosts zu virtualisieren.
Docker ist eine solche Virtualisierungslösung, die in der aktuellen Version auf die Linux-Lösungen Libcontainer und Execution Driver setzt. Ältere Versionen haben noch Linux Container (LXC) unterstützt. Die Technik lässt sich mit Docker noch nutzen, empfohlen wird aber die Verwendung von Libcontainer.
Ab Version 1.5 unterstützt Docker auch IPv6. Außerdem lassen sich jetzt auch Container erstellen, die nur lesenden Zugriff erlauben. Das kann für Big-Data-Umgebungen ideal sein. IPV6 lässt sich auch für die Kommunikation zwischen Containern nutzen, was bei vielen Hadoop-Clustern sinnvoll ist. Außerdem ist dadurch auch eine schnellere Kommunikation zwischen Containern möglich, die sich auf verschiedenen Virtualisierungshosts befinden.
So funktioniert Docker
Anwendungen laufen in Docker als Container. Die Images, um solche Anwendungen bereitzustellen, zum Beispiel Big-Data-Applikationen, werden Docker Images genannt. Diese sind sehr klein, lassen sich schnell verteilen und noch schneller bereitstellen. Docker-Container erhalten eigene IP-Adressen und sind auch über verschiedene Ports ansprechbar.
Erstellen Administratoren zum Beispiel einen Hadoop-Cluster, lassen sich die Knoten mit Docker in Containern virtualisieren und auf den Hosts verteilen. Auch Zusatzanwendungen wie Hive und Yarn lassen sich auf diesem Weg virtualisiert über Container zur Verfügung stellen. Ein Beispiel für einen solchen Cluster ist hier zu finden. Die Einrichtung ist auch in einem Youtube-Filme zu sehen.
Neben der Möglichkeit, Hadoop-Clusterknoten bereitzustellen, können Administratoren auch die NoSQL-Datenbank-Server über Docker bereitstellen, etwa die NoSQL-Datenbank MongoDB.
Cloudbreak und Apache Ambari – Docker-Lösung speziell für Big Data
In diesem Bereich gibt es mit Cloudbreak eine Möglichkeit, Hadoop direkt mit Docker-Technologien zu verbinden. Cloudbreak soll vor allem bei der Bereitstellung von Hadoop in Docker-Container unterstützen. Cloudbreak bietet hier auch eine REST-API, mit der sich Hadoop-Cluster in Docker-Container verwalten lassen, unabhängig von der Umgebung, in welcher diese betrieben werden.
Hier arbeitet Cloudbreak auch sehr eng mit Ambari zusammen. Ambari bietet eine grafische Oberfläche für das Installieren von Hadoop-Clustern und kann jederzeit beim Hinzufügen weiterer Knoten und Prozesse unterstützen. Neben der Überwachung von Clustern lassen sich auch die Anwendungen, Abfragen und deren Auslastung auslesen. Dazu kommt die parallele Anbindung an Oozie, Zookeeper und Hive.
Sehr wichtig in diesem Zusammenhang ist auch das Informieren von Administratoren bei Fehlern in Jobs oder des ganzen Servers. Anbinden lassen sich dazu auch Hadoop-Knoten, die über Docker-Container zur Verfügung gestellt werden. Außerdem kann Ambari auch Hadoop-Cluster komplett, auf Docker-Containern basierend, installieren. Administratoren finden dazu Anleitungen im Internet.
Docker in der Cloud nutzen – Microsoft Azure und Amazon EC2
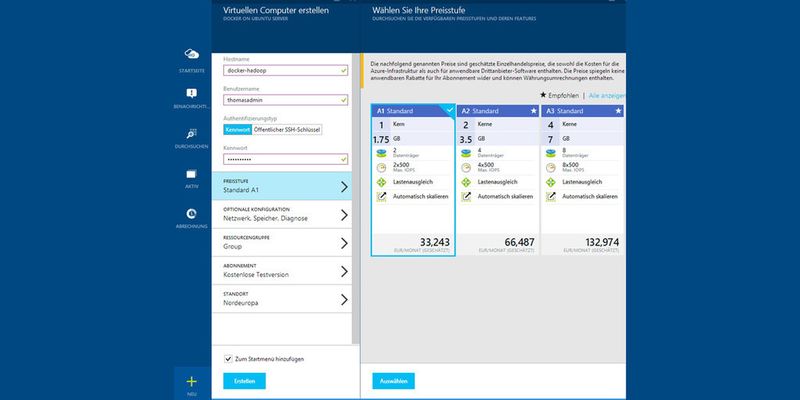
Docker gehört mittlerweile zum Standard, wenn es um die Virtualisierung von Anwendungen geht. Daher haben auch große Cloudanbieter reagiert und Erweiterungen integriert. Wollen Unternehmen Hadoop-Cluster auf Basis von Linux in Microsoft Azure bereitstellen, lässt sich ebenfalls Docker nutzen. Wer Interesse an einem Test hat, kann sich eine virtuelle Maschine auf Basis von Ubuntu in Microsoft Azure erstellen.
Dazu verwenden Administratoren die Docker-VM-Erweiterung des Azure Linux Agent, um einen virtuellen Docker-Computer zu erstellen. Dieser kann eine beliebige Anzahl von Containern für Anwendungen in Azure hosten, auch für Hadoop. Die genaue Vorgehensweise beschreibt Microsoft in der Azure-Dokumentation. Auch in Amazon EC2 lässt sich Docker einbinden. Dazu nutzen Administratoren den Amazon EC2 Container Service.
Google plant in seiner Cloud Platform ebenfalls die Docker-Integration. Hier steht bereits die Alpha-Version der Google Container Engine zur Verfügung.
Wer im Unternehmen auf VMware-Virtualisierungsprodukte setzt, soll zukünftig ebenfalls mit Docker virtualisieren können. VMware will dazu bei der Entwicklung von Docker mitarbeiten und die Verwaltung von Docker-Container über eigene Verwaltungswerkzeuge ermöglichen.
Fazit
Unternehmen, die eigene Hadoop-Cluster betreiben oder die Einführung planen, sollten sich in jedem Fall die Möglichkeiten von Docker ansehen. Zwar wird die Bereitstellung zu Beginn etwas komplexer, im laufenden Betrieb offenbaren sich aber schnell die Vorteile der viel kleineren Images. Die Hosts können effizienter ausgenutzt werden und die Bereitstellung neuer Clusterknoten geht viel schneller.
(ID:43317291)
:quality(80)/p7i.vogel.de/wcms/45/9c/459cd112940346cbf86a75d963c4b354/0125608157v1.jpeg "Docker bringt KI-Agenten in Compose. Entwickler können Agenten-Workloads deklarieren, lokal testen und in der Cloud skalieren. Cloud-Offload startet im Beta-Test. (Bild: Docker)")
:quality(80)/p7i.vogel.de/wcms/87/26/8726481c73b8bbff6aac59255bafe24f/0126590013v1.jpeg "Der Autor: Michael Hunger beschäftigt sich seit mehr als 35 Jahren leidenschaftlich mit Softwareentwicklung. In den vergangenen 13 Jahren hat er an der Open-Source-Graphdatenbank Neo4j in verschiedenen Funktionen gearbeitet, zuletzt als Leiter der Produktinnovation und Entwicklerstrategie. Sein aktueller Fokus liegt auf generativer KI, Cloud-Integrationen und Developer Experience. (Bild: Neo4j)")