
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/27/58/27588eb554c000560228987e8b9ded77/0131379007v1.jpeg "Der Autor: Torsten Oelze ist Director bei Cognyte (Bild: Cognyte)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/93/4e/934e8b65bd2ff95ae390446e86b4920f/0131912137v2.jpeg "Siemens Industrial Edge ermöglicht es Kunden, Edge-Geräte und -Apps direkt am Produktionsstandort bereitzustellen und zu verwalten. Das App-Ökosystem sorgt für eine nahtlose Verbindung zu industriellen Anlagen, IT-Systemen und der Cloud. (Bild: Siemens)")
:quality(80)/p7i.vogel.de/wcms/43/3f/433f1d38ba273f8c124e0285f97b46d7/0131912118v2.jpeg "Agentische KI: Die Zukunft der KI in EDA liegt nicht mehr in Copiloten, sondern in der Orchestrierung vieler Prozesse. (Bild: Siemens EDA)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/b3/d4b39c1c2d46f3ae6e49ed80f2ecd9d1/0132006976v2.jpeg "Laut einer Bitkom-Studie lässt die Zunahme von KI-gestützer Software-Entwicklung Kunden andere Erwartungen an Software stellen: Statt für Arbeitszeit werde künftig stärker für messbare Ergebnisse bezahlt, beispielsweise anhand der Zahl gelöster Tickets. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/ba/e2/bae2c84df6310701a01325e9fbfd96d6/0132099756v1.jpeg "Simon Ritter, Deputy CTO bei Azul, warnt: Vibe Coding produziere Code, der tue, was das Modell verstanden habe – nicht, was gemeint war. (Bild: Azul)")
:quality(80)/p7i.vogel.de/wcms/b5/f4/b5f489601994978d1730f20e206002f7/0131967433v1.jpeg "„Patch the Planet“: Die von OpenAI gestartete Initiative soll mittels KI-gestützter Sicherheitsanalyse Open-Source-Maintainer entlasten, indem potenzielle Schwachstellen vor der Weitergabe an Projekte von Experten geprüft und in belastbare Patches überführt werden. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Datenübernahme und -verarbeitung 8 Dinge, die Sie über Big Data wissen sollten
Um Big Data optimal im Unternehmen einzusetzen, kommen Verantwortliche um den Betrieb eines größeren Clusters kaum herum. Außerdem gibt es keine einzelne Lösung, die alles enthält, sondern es sind verschiedene Anwendungen notwendig. In diesem Beitrag geben wir einen Einblick.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
Die Basis der meisten Big-Data-Umgebungen ist Hadoop. Diese Lösung verfügt aber standardmäßig nicht über alle Features, sondern muss mit weiteren Lösungen ergänzt werden. Erst dann ist eine vernünftige Big-Data-Infrastruktur sinnvoll. Es gibt kostenlose Open-Source-Erweiterungen, welche die Installation, den Betrieb und die Datenverarbeitung mit Hadoop erleichtern. Sind diese Lösungen noch nicht im Einsatz, so ist es sinnvoll, diese nachträglich zu implementieren. Unternehmen, die eine neue Umgebung installieren, sollten idealerweise gleich die notwendigen Zusatzdienste mit einplanen.
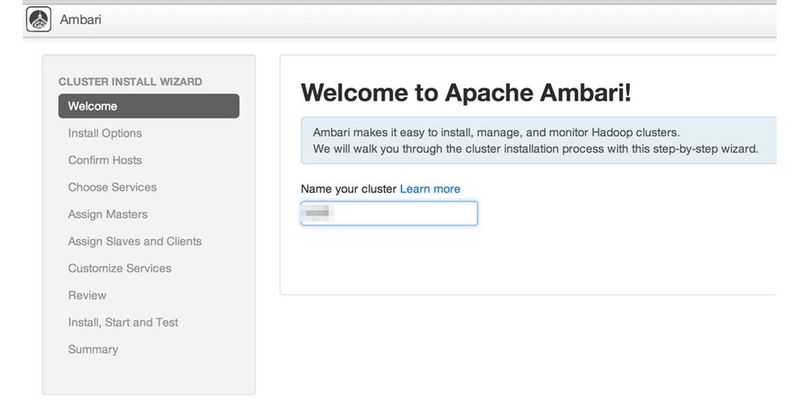
Hadoop-Cluster optimal installieren und verwalten mit Ambari
Hadoop-Cluster sind systembedingt in den meisten Fällen recht große Konstruktionen, die mit Standardbordmitteln nur schwer zu installieren, zu verwalten und zu überwachen sind. Ambari bietet eine grafische Oberfläche für das Installieren und erweitern von Hadoop-Clustern. Die webbasierte GUI führt Administratoren durch die Erstellung des Hadoop-Clusters.
Administratoren können über Ambari Dienste und Prozesse auf Clusterknoten in Hadoop starten, stoppen und deren Status überwachen. Dazu stellt Ambari auch ein webbasiertes Dashboard für die Verwaltung zur Verfügung. Außerdem lässt sich die Lösung mit Nagios verbinden.
Big-Data-Umgebungen virtualisieren
Bei Docker handelt es sich um eine Lösung, die Anwendungen im Betriebssystem virtualisieren kann. Basis ist Linux. Anwendungen lassen sich leichter bereitstellen, da die Container mit den virtualisierten Anwendungen transportabel sind.
Oft ist es effizienter, die Anwendung selbst zu virtualisieren und direkt auf einem Host zu betreiben. Das muss das Betriebssystem aber unterstützten, und die Anwendungen auch. Docker ist eine solche Virtualisierungslösung, die auf die Linux-Lösungen Libcontainer und Execution Driver setzt. Erstellen Administratoren zum Beispiel einen Hadoop-Cluster, lassen sich die Knoten mit Docker in Container virtualisieren und auf den Hosts verteilen. In diesem Bereich gibt es mit Cloudbreak eine Möglichkeit, Hadoop direkt mit Docker-Technologien zu verbinden. Ambari kann Hadoop-Cluster basierend auf Docker-Container installieren. Administratoren finden dazu Anleitungen im Internet.
Abfragen für Hadoop mit Apache Drill
Apache Drill erweitert die Möglichkeit von Hadoop-Umgebungen und NoSQL-Datenbanken um die Möglichkeit, SQL-Abfragen zu erstellen. Im Fokus stehen Echtzeit-Abfragen und Ad-hoc-Berichte in BI- oder Big-Data-Umgebungen. Apache Drill ist in der Lage, einfache Analysen und Abfragen durchzuführen, kann aber auch in Batch-Prozessen und Pipelines eingebunden werden, wenn es um komplexere Berechnungen geht. Die Abfrage-Sprache wird auch als DrQL bezeichnet.
Vorteil der Lösung ist die Unterstützung von SQL-gängigen Abfragen. Das heißt, Entwickler können sich sehr schnell in das Produkt einarbeiten und erhalten schnell zuverlässige Abfragen. Als Datenspeicher kann Drill direkt an Hadoop angebunden werden und unterstützt in dieser Hinsicht auch das Hadoop File System (HDFS); HBase wird ebenfalls unterstützt. Unternehmen, die sich mit Hadoop beschäftigen, kommen kaum um Spark und Drill herum. Auch wenn die beiden Technologien noch nicht im Einsatz sind, sollten sich Entwickler den Produkten auseinandersetzen.
Big Data mit Apache Spark
Wer sich mit Big Data und Hadoop beschäftigt, sollte auch Apache Spark im Blick haben. Durch das Produkt wird die Verwendung von Hadoop in eine neue Dimension der Leistung gehoben, auf die kein Unternehmen verzichten kann, welches Big Data effizient betreiben will. Im Daytona Gray Sort Benchmark siegte Spark in der 100-Terabyte-Klasse mit einem neuen Weltrekord. Der alte Weltrekord lag bei 72 Minuten und wurde von einem Hadoop-MapReduce-Cluster aufgestellt. Spark hat den alten Rekord mit 23 Minuten geschlagen – und das mit einem Zehntel der Rechenkraft.
Es wird schnell klar, dass Spark in Bereiche der Big-Data-Verarbeitung vordringen kann, die für Hadoop nicht möglich sind. Apache Spark erweitert die Möglichkeit von Hadoop-Clustern um Echtzeitabfragen, ähnlich zu SQL. Dazu bietet das Framework In-Memory-Technologien, kann also Abfragen und Daten direkt im Arbeitsspeicher der Clusterknoten speichern. Da die Abfragen sich auch parallel auf mehrere Knoten verteilen lassen, steigt die Leistung enorm.
Apache Spark soll MapReduce in Hadoop ablösen und bietet eine schnellere Abfragegeschwindigkeit von Daten. Die Entwickler selbst sprechen von einer hundertfachen Geschwindigkeit. Das Framework wird bereits von großen Unternehmen eingesetzt, die eine große Datenmenge verarbeiten müssen. Prominente Beispiel sind NASA, Intel und IBM.
Apache Sqoop – SQL-Datenaustausch in Big-Data-Umgebungen
Apache Sqoop ist ein Datentransfer-Tool für Big-Data-Umgebungen, vor allem für Hadoop. Einer der größten Vorteile des Tools ist die Möglichkeit, Daten aus SQL-Datenbanken in NoSQL-Infrastrukturen zu übertragen. Sollen Daten zwischen SQL-Datenbanken und NoSQL-Infrastrukturen/Hadoop-Umgebungen ausgetauscht werden, kommen Entwickler kaum an Apache Sqoop vorbei.
Der Daten-Import-Export lässt sich in beide Richtungen durchführen, also von der relationalen Datenbank zu Hadoop und von Hadoop zurück in die entsprechende Datenbank. Entwickler können Sqoop in eigene Infrastrukturen einbinden, aber auch in Cloudlösungen integrieren. Sqoop steht auch für HDInsight in Microsoft Azure zur Verfügung. So gut wie jede Hadoop-Distribution und -Cloudlösung unterstützt Sqoop. Die wichtigsten relationalen Datenbanken lassen sich anbinden.
Mehr Sicherheit mit Apache Knox und Chukwa
Bei Apache Knox handelt es sich um ein Gateway für Hadoop-Cluster. Wer Big-Data-Analysen im Cluster betreibt, muss natürlich auch für die Sicherheit im Cluster sorgen. Hier spielt Apache Knox eine wichtige Rolle. Die Hadoop-Erweiterung bereichert das Sicherheitsmodell von Hadoop und integriert Authentifizierungen und Benutzerrollen für den Zugriff auf die Daten.
Für die Anbindung der Benutzer kann Knox auch auf Active Directory und andere LDAP-Verzeichnisse zugreifen. Auch die Anbindung an andere Authentifizierungsmechanismen ist möglich. Um die Hadoop-Infrastruktur zu überwachen, setzen Administratoren zum Beispiel auf Apache Chukwa. Das System setzt auf Hadoop auf und überwacht HDFS-Datenzugriffe. Auch das MapReduce-Framework lässt sich damit analysieren und überwachen.
Big Data in der Cloud
Nicht immer ist ein eigener Cluster für den Betrieb einer Big-Data-Lösung notwendig. Amazon bietet in Amazon Web Services und Microsoft in Azure die Möglichkeit, Cluster zu erstellen. Die hier vorgestellten Zusatzwerkzeuge funktionieren überwiegend auch mit diesen Cloud-Lösungen, sodass Administratoren auch hier die Möglichkeit haben, sich die Arbeit etwas zu erleichtern. Neben der Möglichkeit, Hadoop als virtuellen Cluster zu erstellen, können Administratoren auch virtuelle Server in Amazon ECS oder Microsoft Azure Virtual Machines betreiben und auf dieser Basis selbst einen Cluster erstellen.
HDFS oder GPFS für Big Data nutzen
Viele Unternehmen setzen beim Betrieb einer Big-Data-Lösung auf das Hadoop File System (HDFS). Es gibt aber auch Alternativen. Eine der bekanntesten Alternativen in diesem Bereich ist das General Parallel File System (GPFS) von IBM. GPFS ist für AIX und Linux verfügbar.
Nutzen lassen sich die Vorteile von GPFS im Zusammenhang mit Hadoop, vor allem mit einer speziellen Hadoop-Distribution von IBM. Diese Distribution mit der Bezeichnung InfoSphere BigInsights bietet vor allem in sehr großen Umgebungen im Vergleich zu reinen Open-Source-Umgebungen viele Vorteile.
Durch die neue GUI bietet GPFS wesentliche Vorteile im Vergleich zu HDFS. Im Bereich Hadoop sollten sich Unternehmen vor der Anschaffung von HDFS darüber nachdenken, ob nicht vielleicht GPFS besser geeignet sein könnte. Allerdings sollten hier erst Angebote eingeholt werden, da GPFS ein kommerzielles Dateisystem ist. Prominenter Kunde ist zum Beispiel das Formel-1-Team Red Bull Racing.
(ID:43479825)
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/34/a2/34a2d02781eaabef906c308dd135c049/0130541481v1.jpeg "KI kann helfen, konsistente Datanbankschemata zu erstellen und weiterzuentwickeln. (Bild: © CreativeIMGIdeas - stock.adobe.com / KI-generiert)")