
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/f8/f6/f8f63ea1acab816895c1450c8a056fe1/0131911243v2.jpeg "Cisco sieht in KI eine große Chance für den Standort Deutschland – vorausgesetzt, Unternehmen verbinden Innovationswillen mit der richtigen Infrastruktur. (Bild: Cisco)")
:quality(80)/p7i.vogel.de/wcms/3f/cb/3fcbdf71036cdeb2dacc68c100bfa5db/0131917207v1.jpeg "Die Datenbank-Inseln laut Databricks (Bild: Dr. Dietmar Müller)")
:quality(80)/p7i.vogel.de/wcms/63/89/6389a2500088ebda5fe4bbcd76ced520/0131897755v1.jpeg "Das Marketingversprechen verspricht eine reibungslose Code-Übersetzung. In der Praxis bricht die automatisierte Migration komplexer Legacy-Systeme laut Gartner an ihren eigenen Grenzen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Kommentar von Kiran Prakash und Lucy Chambers, ThoughtWorks Vor dem Data Lake stehen die Use Cases
Künstliche Intelligenz (KI) und Machine Learning sind derzeit in aller Munde. Zahlreiche Unternehmen wollen auf diesen Zug aufspringen und von ihren Datenreserven profitieren.Tatsächlich bietet diese Technologie ein enormes Potenzial – aber nur ein sinnvoller Einsatz bringt echten Mehrwert.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
Unternehmen wollen häufig ihre KI-Initiativen durch den Aufbau eines Data Lakes schnell vorantreiben. Oft wird diese Vorgehensweise ausschließlich als ein Infrastruktur-Projekt betrachtet, ohne vorher Anwendungsfälle und Ziele zu definieren. Die Annahme ist: „Wenn wir eine robuste Dateninfrastruktur aufbauen, werden sich später schon Anwendungsfälle dafür ergeben.“
Software sollte jedoch am besten in vertikalen Schichten entwickelt und unbedingt an Anwendungsfälle gekoppelt werden, die jeweils einen klaren Mehrwert für den Nutzer liefern. Das gilt auch für datenintensive Projekte. Es kann verlockend sein, eine Plattform mit nur einer horizontalen Ebene (manchmal als Data Lake bezeichnet) zu entwickeln – besonders für Anwendungsfälle mit umfangreichen Datenmengen in unterschiedlichen Formaten. Es stellt sich die Frage: Ist der Ansatz des „Product Thinking“ der bessere Weg für Data-Lake-Projekte?
Die meisten großen Unternehmen würden davon profitieren, wenn sie den Umfang der Data Lakes auf das Speichern von Rohdaten beschränken und funktionsübergreifende Produktteams bilden würden. So könnten sie Machine-Learning-Anwendungen mit ihren eigenen Darstellungen (Lake Shore Marts) entwickeln, die speziell auf ihren Anwendungsfall zugeschnitten sind.
Erstmal machen, der Rest ergibt sich von alleine
Data Lakes scheinen besonders anfällig für die „Erstmal-machen-der-Rest-ergibt-sich-von-alleine“-Mentalität zu sein. Das kann verschiedene Gründe haben:
Oft gehören Data Scientists und Data Engineers zu getrennten Teams. Data Scientists sind näher an der Business-Perspektive, während Data Engineers sich mehr mit der Infrastruktur und IT befassen. Getrennte Teams erschweren den Informationsfluss und verstärken die Tendenz, einen Data Lake lediglich als ein Infrastrukturproblem zu betrachten.
Es ist nicht leicht, spezifische Anwendungsfälle und die Wertschöpfung eines Data Lakes zu ermitteln. Hierfür ist es notwendig, die Anwender einzubeziehen; die unterschiedlichen Parteien müssen sich auf ein gemeinsames Ziel einigen.
Oft wird argumentiert, Data Lakes sollten für eine große Bandbreite an Use Cases verwendbar sein. Sicherlich sollte ein Data Lake mehr als nur einen Anwendungsfall unterstützen. Aber es sollte nicht zu viel in Up-front-Architektur und Design investiert werden, bevor Use Cases identifiziert werden.
Fallstricke
Ohne die finalen Use Cases im Auge zu behalten, führt die Top-down-Planung eines Data Lakes fast zwangsläufig zu einer mangelhaften Problemlösung. Und ohne praktische Modelle aus den Daten zu entwickeln und sie in der realen Welt auszuprobieren, um aus dem Feedback zu lernen, ist es schwer, die beste Lösung für ein Problem zu finden.
Die Bereinigung und Formatierung der Daten für einen Use Case machen 70 bis 80 Prozent des Entwicklungsaufwands einer Anwendung für Machine Learning aus. Deshalb ist es nicht sinnvoll, viel Arbeit in die Aufbereitung der Daten zu stecken, ohne sich über deren Anwendung im Klaren zu sein. Die Personen, die an dem Modell arbeiten, werden wahrscheinlich noch einmal so viel Arbeit investieren müssen, sobald die Anwendungsfälle bestimmt sind.
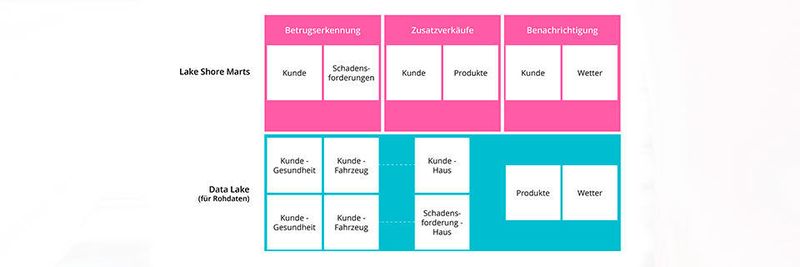
Hier ein hypothetisches Beispiel: Ein Versicherer plant einen Data Lake. Das Ziel ist, Data Scientists neue Möglichkeiten zu bieten, Daten abzurufen und zu analysieren, um das Geschäft voranzutreiben. Die Firma ist über die Jahre durch Übernahmen gewachsen und hat deshalb keine einheitliche Kundensicht. Die Kundendaten sind auf etwa 20 Subsysteme verteilt, je nach Produktlinie (Krankenversicherung, Autoversicherung etc.).
Im Zusammenhang mit der Data-Lake-Initiative möchte das Unternehmen nun eine einheitliche Sicht auf die Kundendaten schaffen. Monate lang wird nach einer durchgängigen Definition der Kunden gesucht, die für alle zukünftigen Anwendungsfälle gültig ist. Das Ergebnis ist nur mittelmäßig zufriedenstellend. Wo liegen die Ursachen?
- 1. Es gibt möglicherweise keine einheitliche Definition des Kunden, die für alle zukünftigen Use Cases gleich gut passt.
- 2. Die Kundendaten aus 20 verschiedenen Systemen zu bündeln, abzugleichen und zu deduplizieren erfordert einen hohen Koordinationsaufwand zwischen den verschiedenen Produktteams.
Ohne zu wissen, wie die zusammengeführten Kundendaten eingesetzt werden, kann dies zu einer Mammutaufgabe werden. Das Unternehmen ist nicht in der Lage zu priorisieren und gut informierte Entscheidungen zu treffen, wenn Trade-offs involviert sind.
Wenn die Nutzer des Data Lakes nicht früh genug sicherstellen, dass die gespeicherten Daten auch genutzt werden, besteht die Gefahr, dass aus dem Data Lake ein Datensumpf (Data Swamp) wird – also ein Abladeort für Daten jeglicher Qualität. Dies ist kostenintensiv und hat wenig Nutzen für das Unternehmen.
Product Thinking für Data Lakes
Wir empfehlen, den Data Lake mit einem Bottom-up-Ansatz anzugehen, indem eine vertikale Schicht nach der anderen gebaut wird. Wie würde das am Beispiel des Versicherers aussehen?
Fangen wir mit den folgenden Use Cases an:
- Identifikation betrügerischer Ansprüche, um diese für eine eingehendere, manuelle Untersuchung auszuwählen. Das Ziel ist, Betrugsfälle im laufenden Jahr um fünf Prozent zu reduzieren.
- Vorhersage des Wetterverlaufs, sodass der Versicherer Kunden empfehlen kann, ihre Autos bei einer Sturmwarnung unterzustellen. Auf diese Weise sollen Kfz-Versicherungsfälle um zwei Prozent verringert werden.
- Zusatzverkäufe anderer Versicherungsprodukte an Kunden, auf Basis der aktuellen Produkte. Das Ziel: Onlinezusatzverkäufe um drei Prozent erhöhen.
Ausgangssituation
Es besteht eine komplexe IT-Architektur und eine Governance-Struktur, die Dokumentationsstandards, Richtlinien für die notwendige Datenspezifikation, Rückwärtskompatibilität, Versionierung etc. umfasst.
Vorab werden schon einige Entscheidungen getroffen, z. B. ob man on-premises oder lieber in-cloud arbeiten möchte oder welcher Provider und welcher Datenspeicher gewählt wird. Diese Entscheidungen lassen sich später im Projekt nicht mehr so leicht ändern, deshalb müssen sie auf ein Minimum reduziert werden.
Ein Architekturteam stellt sicher, dass die Architektur geeignet ist und die Governance-Strukturen beachtet werden, während sich die Plattform weiterentwickelt und Anwendungen entwickelt werden. Ein interdisziplinäres Delivery-Team, in dem Product Owner, Data Scientists und Data Engineers vertreten sind, stellt die Anwendungsfälle produktiv.
Anwendungsfälle entwickeln
Das Projektteam beginnt mit der kleinsten Komponente und implementiert deshalb den Anwendungsfall zur Betrugserkennung als erste vertikale Schicht. Mit dem Wissen, dass Krankenversicherung und Autoversicherung den Großteil der Ansprüche ausmachen, fokussiert sich das Team außerdem zuerst auf diese beiden vertikalen Ebenen. Für diese beiden Bereiche werden nun die unverarbeiteten Kundendaten und die Daten über Schadensersatzansprüche in den Data Lake gezogen. Anschließend werden sie bereinigt, akkumuliert und in einem Data Mart für die verschiedenen Use Cases aufbereitet. Als nächsten Schritt würde man ein Betrugsermittlungssystem aus den Daten entwickeln.
Nachdem eine erste Version des Modells zur Betrugserkennung produktiv ist, identifiziert das Team zusätzliche Datenfelder zur Ergänzung. Die Data Scientists arbeiten eng mit den Data Engineers zusammen und geben relevante Informationen umgehend weiter. Auf Feedback lässt sich so schnell reagieren. Gemeinsam suchen sie nach dem besten Weg, Daten aus den neu erschlossenen Feldern zu sammeln und das Modell anzupassen. Das neue Modell ist nun deutlich besser als das erste. Dieser Ansatz hat den Vorteil, dass nur zwei von 20 Datenquellen genutzt werden (müssen). So wird viel Arbeit gespart und noch effektiver auf das Fünf-Prozent-Ziel hingearbeitet.
Wenn das Betrugsermittlungssystem läuft und bereits einen Mehrwert für das Unternehmen generiert, kann sich das Unternehmen darauf konzentrieren, die Kundendaten für das Zusatzverkaufsziel wirksam einzusetzen. Hierfür werden Produktdaten und Kundendaten über Gebäudeversicherungen zum Data Lake hinzugefügt. Sie bilden zusammen mit bestehenden Kundendaten eine neue Darstellung in ihrem eigenen begrenzten Kontext. So kann auf produktive und effektive Weise auf das Ziel „zwei Prozent Zusatzverkäufe“ hingearbeitet werden.
Jetzt kann sich das Unternehmen dem Use Case „Benachrichtigungen“ zuwenden. In diesem Fall handelt es sich um ein komplexes Modell, das alle bisher verwendeten Rohdaten nutzt und zusätzlich noch eine weitere Quelle benötigt: Wetterdaten in Echtzeit.
Einige der Kundenrohdaten müssen für den Anwendungsfall neu aufbereitet werden. Doch welcher Vorteil liegt darin, die Daten im Nachhinein aufzubereiten und nicht direkt zu Anfang? Das Team versteht mittlerweile die Anforderungen der ersten beiden Anwendungsfälle besser und kann deshalb mit dem entsprechenden Arbeitseinsatz den gewünschten Mehrwert schaffen, ohne viel Zeit mit Spekulationen zu verschwenden.
Natürlich müssen nicht alle Arbeiten an anderen Use Cases warten, bis ein Use Case abgeschlossen ist. Doch die Anwendungsfälle sollten klar definiert sein.
Fazit
- Es gibt keinen einheitlichen „So-funktioniert-ein-Data-Lake"-Ansatz. Um möglichst schnell ans Ziel zu kommen, sollte das zu lösende Problem so präzise wie möglich beschrieben werden.
- Arbeiten Sie mit klar definierten Anwendungsfällen und messbaren Geschäftszielen. Testen Sie diese und berücksichtigen Sie Feedback. Datenprojekte als Produkte und nicht nur als Infrastruktur zu betrachten, erspart viel Arbeit.
- Data Scientists und Data Engineers sollten eng zusammenarbeiten. Das bringt schnellere und bessere Ergebnisse. Die gemeinsame Verantwortung hat außerdem den Vorteil, dass der Wartungsaufwand leichter zu koordinieren ist.
(ID:45947424)
:quality(80)/p7i.vogel.de/wcms/1a/6d/1a6dadedc4b4a0a1656003f88ebe8503/0125889645v1.jpeg "Dieses Data Mesh von Dataiku ist bereits ein LLM Mesh: Er erlaubt die Nutzung verschiedener Sprachmodelle (ganz unten), um so den besten Nutzen für die KI-Applikationen (ganz oben) zu erzielen. Dazwischen befinden sich Funktionen wie RAG, Abrechnung, Caching, Security und mehr. Routing und Orchestration sind für das Mesh von zentraler Bedeutung. (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/c5/dc/c5dc5a70b3b30c72d140b96c300743b7/0129090945v1.jpeg "Nur wenige Unternehmen schaffen den Sprung vom GenAI-Pilotprojekt zum produktiven Einsatz. Entscheidend ist nicht das Modell, sondern eine orchestrierte Architektur. (Bild: © Andrey - stock.adobe.com)")