
:quality(80)/p7i.vogel.de/wcms/49/c6/49c665060846beb129ae679a2918c61a/0132163773v1.jpeg "Wer trägt die Verantwortung? Echte Datensouveränität bei KI und Cloud bedeutet, die Kontrolle über sensible Daten sicher in der eigenen Hand zu behalten. (Bild: © Lustre - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/6b/7a/6b7a7ae072bb7ab964cde4d302755ceb/0124814981v1.jpeg "Der European Blueprint soll bis Ende 2026 festlegen, welche europäischen Organisationen Zugang zu fortgeschrittenen KI-Modellen erhalten. Verbindliche Pflichten für Anbieter außerhalb der EU entstehen daraus nicht. (Bild: Vergiliy - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/26/81/2681098961a1b8010bbf241f3e914891/0132345254v1.jpeg "Räumlich-zeitliche Identifikatoren sollen fragmentierte Datenbestände systemübergreifend nutzbar machen. Nach Angaben von The Green Bridge ist die Grundlage für KI-Anwendungen und Automatisierung. (Bild: Unsplash-Steve A Johnson)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/d9/db/d9dbfbca0f9ff41469a40d883f8e5cb5/0132438388v1.jpeg "Mit Version 9.5 rückt Denodo die semantische Schicht ins Zentrum der Plattform und positioniert sich im Wettbewerb um die Kontextversorgung von KI-Agenten. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b8/76/b8761191f739895263a4bdbfcaf9c5b2/0132429694v1.jpeg "Mit dem Wechsel von assistierenden zu ausführenden Agenten verlagert sich der Kontrollbedarf im Produktdatenmanagement. Entscheidend wird die Nachvollziehbarkeit einzelner Attributänderungen. (Bild: Akeneo)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")
:quality(80)/p7i.vogel.de/wcms/78/9a/789af78a62e28f5e8cc995570d48b822/0130655525v1.jpeg "SupplyX wollte sein Transportmanagement-System ersetzen und fand den Engpass in den Daten. Ein Praxisbericht über die Datenbasis produktiver KI. (Source: © MAGNIFIER - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/9f/fe/9ffe3d484cf6fdc7ea137128b15f60a9/0131577982v1.jpeg "Im Einsatz für den Artenschutz: Ein WWF-Ranger durchstreift den Regenwald. Das geplante Wildlife Protection Operations Center soll solche Einsätze KI- und datenbasiert optimieren. (Bild: Emmanuel Rondeau / WW_US)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/e9/34/e9342418bd8081921fdd2fc2fc4be51b/0132359705v2.jpeg "Einsatz auf dem Acker: Wie sich humanoide Systeme mit schweren landwirtschaftlichen Maschinen vernetzen lassen, wird in Ilmenau erprobt. (Bild: Fraunhofer IOSB)")
:quality(80)/p7i.vogel.de/wcms/57/b8/57b8da3ba179d80f10073e7541f8b68f/0132491632v1.jpeg "Die Brücke vom Trainings-Cluster über die Simulation bis zum Roboter im Feld hat Lücken: Physical AI scheitert seltener am Modell als am Workflow. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f9/43/f943ca681620e9eb521fea039168a2fe/0132555049v1.jpeg "Die Konferenz T3 – Transform The Tomorrow diskutiert am 1. und 2. Dezember 2026 Strategien, wie Unternehmen sich zukunftssicher aufstellen können. (Bild: © Vogel Corporate Solutions / AdobeStock 1280236166, Oksana)")
:quality(80)/p7i.vogel.de/wcms/95/e5/95e50766b5de0f4b7ca74d1db2524bf2/0132321286v2.jpeg "Humanoide Roboter: Roboter, die vor wenigen Jahren noch eine Vision waren, sind heute dank KI, maschinellem Lernen und Echtzeit-Datenverarbeitung Realität. (Bild: Pete Linforth)")
:quality(80)/p7i.vogel.de/wcms/81/6d/816dfab525864f08b3569676daffb31f/0132240748v2.jpeg "Workflow des Ablaufs einer GitLost-Attacke. (Bild: Noma Security)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/30/19/30192d4799534c8e823986e895916cf4/0131682946v1.jpeg "Der Autor: Stig Martin Fiskå ist Global Head of AI for Good bei Cognizant und Leiter der Cognizant Ocean Business Group (Bild: Cognizant)")
:quality(80)/p7i.vogel.de/wcms/d6/42/d64261f97ff8ea94ab4f7e2f5afb1869/0132187522v1.jpeg "KI-Agenten stimmen Abläufe in Unternehmen zunehmend selbstständig ab – umso wichtiger sind übergeordnete Governance-Regeln und Berechtigungskonzepte, wie sie auch für menschliche Mitarbeitende gelten. (Bild: © Andrea Danti - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Datenqualität sicherstellen So verbessert Apache Griffin die Data Quality
Apache Griffin kann die Datenqualität in Big-Data-Umgebungen verbessern. Das Open Source Tool unterstützt die Batch-Verarbeitung und den Streaming-Modus. Wir geben einen Überblick.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
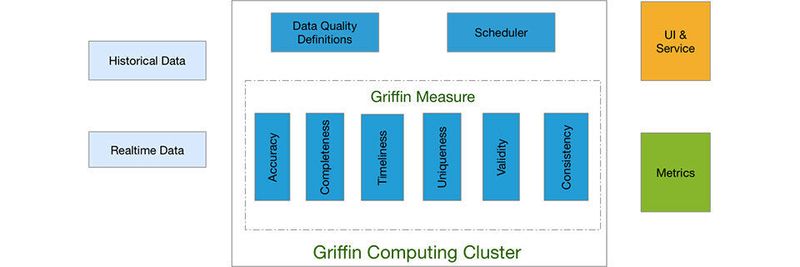
Apache Griffin ist seit Ende 2018 ein Top-Level-Projekt bei Apache. Mit dem Open Source Data Quality Tool lässt sich die Datenqualität von Quelldaten in Big-Data-Umgebungen verbessern. Anwender können eigene Qualitätskriterien definieren. Vor allem, wenn Daten in verschiedenen Quellen verteilt sind und zur Weiterverarbeitung eingelesen werden müssen, kann Apache Griffin dabei helfen, die Datenqualität deutlich zu verbessern. Bei den Daten kann es sich zum Beispiel um Batchdaten aus einem relationalen Datenbanksystem handeln, um Daten aus einem Hadoop-System oder nahezu Echtzeit-Streaming-Daten von Kafka, Storm und anderen Echtzeit-Datenplattformen.
eBay und PayPal nutzen Griffin
Ursprünglich wurde Apache Griffin vor allem bei eBay eingesetzt, um Streamingdaten vor der Verarbeitung zu verbessern. Bei eBay bietet Griffin einen zentralen Datenqualitätsservice für mehrere eBay-Systeme. Hier verarbeitet Griffin täglich mehr als 800 Millionen Datensätze. Das Tool wird außerdem mittlerweile von vielen anderen Unternehmen eingesetzt, um die Datenqualität von Quelldaten zu verbessern. Auch PayPal setzt auf Apache Griffin.
Apache Griffin baut auf Hadoop und Spark auf, um Daten aller Art zu verarbeiten und zu analysieren. Auch unstrukturierte Daten lassen sich dadurch verbessern. Alle notwendigen Aufgaben zur Verbesserung der Datenqualität können in einem einheitlichen Prozess in Apache Griffin durchgeführt werden. Dadurch lassen sich fehlende Daten, falsche Daten oder invalide Daten schnell erkennen und die Verarbeitung entsprechend steuern.
So wird die Datenqualität mit Apache Griffin verbessert
Um die Datenqualität in Big-Data-Umgebungen mit Apache Griffin zu verbessern, wird in verschiedenen Schritten vorgegangen. Datenwissenschaftler und Analytiker definieren zunächst ihre Datenqualitätsanforderungen in Apache Griffin. Dazu gehören zum Beispiel Genauigkeit, Vollständigkeit, Aktualität Profilerstellung und andere Anforderungen. Hier wird also ein Datenqualitätsmodell erstellt, um die Datenqualitätsregeln und Metadaten zu definieren.
Anschließend werden die zu verarbeitenden Quelldaten in Apache Griffin Cluster importiert. Die Quelldaten können auch aus relationalen Datenbanken stammen, aber auch aus Hadoop oder Kafka. Zur Berechnung wird auf Spark gesetzt. Das Modell oder die Regeln werden dazu automatisch durch die Model Engine ausgeführt, um die Validierungsergebnisse der Beispieldatenqualität für das Streaming von Daten zu erhalten.
Die Lösung überprüft danach die Daten auf Basis der Anforderungen, die im Vorfeld festgelegt wurden. Anschließend werden Datenqualitätsberichte als Metriken an definierte Ziele weitergeleitet. Im Rahmen dieses Ablaufs werden die importierten Daten auf die Qualitäts-Anforderungen hin überprüft, die im Vorfeld definiert wurden. Die Vorgehensweise dazu zeigen die Entwickler auf der Quick-Start-Seite des Projektes.
Zusätzlich bietet Apache Griffin die Möglichkeit, Anforderungen an die Datenqualität in die Apache-Griffin-Plattform zu integrieren und eine Logik zur Definition der Datenqualität zu erstellen. Durch die Verwendung von Apache Griffin lassen sich Pipelines bei der Datenverarbeitung vereinfachen.
Anomalie-Erkennung mit Griffin
Das Ziel der Anomalie-Erkennung ist es, Fälle zu identifizieren, die innerhalb von Daten ungewöhnlich sind. Hier nutzt Griffin die Algorithmen Bollinger Band und MAD (Mean Absolute Deviation), um Datensätze zu finden, bei denen eine Anomalie wahrscheinlich ist. Die Anomalie-Erkennung ermöglicht es, Parameter im Algorithmus nach Bedarf anzupassen und die Ergebnisse nach Änderung dynamisch anzuzeigen.
Datenprofilierung
Data Profiling spielt eine wichtige Rolle bei der Verbesserung der Datenqualität. Die Ergebnisse des Profiling können mit dokumentierten Erwartungen verglichen werden. Stimmen die Ergebnisse nicht mit den dokumentierten Erwartungen überein, wird ein Warnbericht ausgelöst.
Einfache Statistiken erzeugen null-, eindeutige und doppelte Zählprofile in Griffin. Das hilft, Probleme zu identifizieren, wie ein unerwartet hoher Anteil von Nullwerten in einer Spalte. Ein Beispiel ist das Profil einer E-Mail-Adresse-Spalte und das Auffinden einer inakzeptabel hohen Anzahl fehlender E-Mail-Adressen. Zusammenfassende Statistiken erzeugen Maximal-, Minimal-, Mittelwert- und Medianzahlenprofile. Beispielsweise sollte der Wert für Alter in der Regel kleiner als 150 und größer als 0 sein. Die erweiterte Statistik generiert die Häufigkeit von Musterprofilen, die durch reguläre Ausdrücke erstellt werden.
Erste Schritte mit Apache Griffin, auch als Container
Um Apache Griffin zu nutzen, muss die Umgebung angepasst werden. Dazu gehört die folgende Software:
- JDK (1.8+)
- Hadoop (2.6.0+)
- Spark (2.2.1+)
- Hive (2.2.0)
Hadoop, Spark und Hive sind wichtige Grundlagen, die in einer Umgebung mit Apache Griffin vorhanden sein müssen. Auch mit Zookeeper ab Version 3.5 arbeitet Griffin zusammen.
Griffin arbeitet mit diesen Big-Data-Lösungen zusammen und ermöglicht die Verbesserung der Qualität von Echtzeitdaten, aber auch von anderen Daten. Die Anleitung zur ersten Einrichtung ist auf der Download-Seite zu sehen. Hier gibt es eine Quick-Start-Anleitung. Generell besteht die Integration zunächst darin, das Apache Griffin Measure Modul zu erstellen. Dazu werden die Quell-Dateien von Griffin heruntergeladen. Anschließend wird das Verzeichnis entpackt und Apache Griffin Jars erstellt:
unzip griffin-0.4.0-source-release.zipcd griffin-0.4.0-source-releasemvn clean installDie erstellte Datei muss dann noch in das Arbeitsverzeichnis verschoben:
mv measure/target/measure-0.4.0.jar <work path>/griffin-measure.jarDie Entwickler stellen auch Demodaten zur Bearbeitung zur Verfügung. Griffin kann auch über Container betrieben werden. Dazu steht auf dem Docker Hub auch ein entsprechendes Dockerfile zur Verfügung.
(ID:46280415)
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")