
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Parallelverarbeitung und In-Memory Die passende Infrastruktur für Big Data
Von Big Data können alle profitieren: Unternehmen, öffentliche Einrichtungen und Non-Profit-Organisation. Doch mit herkömmlichen Business-Intelligence-Verfahren und der entsprechenden IT-Infrastruktur lassen sich große, unstrukturierte Datenbestände nicht einfach in Echtzeit auswerten. Erforderlich sind neue Ansätze, wie etwa eine verteilte Parallelverarbeitung und In-Memory-Technologien.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
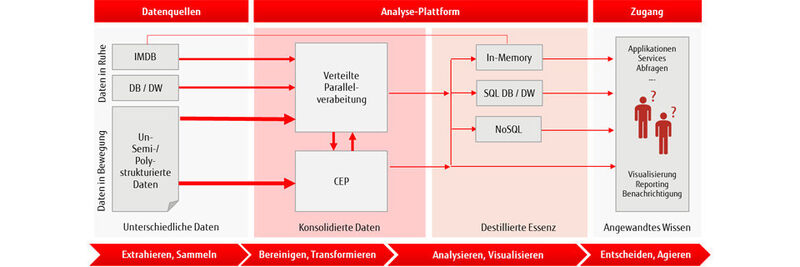
Unternehmen und Behörden sind daran interessiert, wirtschaftliche und gesellschaftliche Trends besser voraussagen und Projektrisiken schon im Vorfeld exakt quantifizieren und verringern zu können. Dazu bedarf es detaillierter Informationen über das künftige Verhalten von Kunden und die Wünsche der Bürger. Diese sollen Big-Data-Analysen liefern, indem Daten zum Kaufverhalten und zu Anfragen bei den Support-Abteilungen ausgewertet werden, oftmals sogar in Echtzeit.
Diese Analysen erleichtern es, ein Gefühl dafür zu bekommen, welche neuen Produkte Kunden wahrscheinlich kaufen und welche Serviceleistungen sie erwarten werden. Stadtentwickler und Verkehrsplaner sind durch solche Analysen in der Lage, den Bedarf an Straßen, S-Bahn- und Buslinien, Krankenhäusern und Schulen besser abzuschätzen.
Klassische BI reicht nicht aus
Allerdings erfordert Big Data eine andere IT-Infrastruktur als klassische Business-Intelligence-Lösungen (BI). Ein Grund dafür ist zum einen die Menge der Informationen, die im Rahmen von Big Data erfasst und bearbeitet werden muss, und zum anderen die häufige Anforderung, Datenanalysen in Echtzeit durchzuführen. Nach Einschätzung von Fujitsu steigen die Datenbestände in Unternehmen jährlich um 65 Prozent an. Die Marktforschungsgesellschaft IDC geht davon aus, dass die weltweit produzierte Datenmenge von rund 8.600 Exabyte bis 2020 auf mehr als 40.000 Exabyte anschwellen wird.
Hinzu kommt die wachsende Zahl an Datenquellen und Formaten. Neben Daten aus transaktionalen Datenbanken müssen jene aus Blogs, Click-Streams und Social-Media-Plattformen berücksichtigt werden. Hinzu kommen Multimedia-Daten wie Fotos und Videos, Textdateien, E-Mails, Log-Daten, Informationen von Sensoren und Lokationsdaten.
Etwa 80 Prozent dieser Informationen liegen in unstrukturierter Form vor und können mit klassischen BI Tools nur schwer bearbeitet werden. Denn die zugrunde liegenden Data Warehouses basieren auf relationalen Datenbanksystemen. Das heißt, sie sind für die Bearbeitung von strukturierten Daten in festen Tabellenfeldern ausgelegt. Unstrukturierte der semistrukturierte Daten müssten deshalb zunächst in strukturierte Daten überführt werden, wodurch klassische Infrastrukturkonzepte schnell an ihre Grenzen stoßen.
Scale-up und Scale-out helfen nicht weiter
Traditionell stehen als Optionen die vertikale Server-Skalierung (Scale-up) und die horizontale Skalierung (Scale-out) zur Wahl. Allerdings sind beide Ansätze keine nachhaltige Lösung. Denn für die physischen Ressourcen eines Server-Systems gelten Grenzen bezüglich der Anzahl der Prozessorkerne, der Arbeitsspeicherkapazität, dem lokalen Plattenspeicher und der Netzwerkbandbreite. Zwar werden sich die heutigen Grenzwerte in Zukunft nach oben verschieben. Das hilft jedoch nicht weiter, weil jeder Performance-Gewinn durch das Wachstum der Datenmengen, die im Rahmen von Big-Data-Projekten anfallen, kompensiert wird.
Gleiches gilt für den Scale-out-Ansatz, also einer horizontalen Server-Skalierung in Verbindung mit relationalen Datenbanken. In diesem Fall können sich die Speicherverbindungen zum Flaschenhals entwickeln. Zudem steigt der Aufwand für die Koordination der Zugriffe auf gemeinsam genutzte Daten, je mehr Datenbank-Server zum Einsatz kommen. Das wiederum führt laut dem Amdahlschen Gesetz zur Abnahme der Server-Effizienz und zu Beschränkungen bezüglich des Parallelisierungsgrads. Eine Scale-out-Infrastruktur in Verbindung mit relationalen Datenbanken wäre daher höchst aufwendig und würde dennoch nicht die erhofften Performance-Gewinne bringen.
Parallelverarbeitung und Shared-Nothing-Architektur
Der Schlüssel zum Erfolg ist eine Parallelisierung auf der Basis einer Shared-Nothing-Architektur und nicht blockierender Netzwerke. Bei diesem Konzept werden die Daten auf die lokalen Plattenspeicher der Knoten in einem Server-Cluster verteilt. Die Bearbeitung der Daten erfolgt auf denjenigen Server-Knoten, auf denen die Daten liegen.
Eine verteilte Parallelverarbeitung hat mehrere Vorteile:
- Hohe Performance: Bearbeiten viele Knoten eine Abfrage, sinkt die Bearbeitungszeit und Analyseresultate stehen schneller zur Verfügung.
- Hohe Skalierbarkeit: Der Anwender kann mit wenigen Knoten starten und bei Bedarf weitere hinzufügen. Eine solche Infrastruktur lässt sich linear und ohne Obergrenze horizontal erweitern.
- Fehlertoleranz: Daten werden auf mehrere Knoten repliziert. Fällt ein System aus, übernimmt ein Server mit einer Datenreplik dessen Aufgabe – und das im laufenden Betrieb.
- Kosteneffizienz: Eine Serverfarm lässt sich aus handelsüblichen Zwei-Prozessor-Systemen mit einigen Terabyte lokalem Speicher aufbauen.
Apache Hadoop als Big-Data-Standard
Der De-facto-Standard für die verteilte Parallelverarbeitung ist das Open-Source-Ecosystem Apache Hadoop. Hadoop lässt sich horizontal auf mehrere tausend Knoten skalieren, ist fehlertolerant und erlaubt stabile Speicher- und Analyseprozesse. Ein Bestandteil von Hadoop ist das Hadoop Distributed File System (HDFS), das die verteilte Speicherung sehr großer Datenmengen auf mehreren Knoten erlaubt. Dazu wird das Netzwerk in Master- und Slave-Knoten unterteilt.
Auf dem Master Server liegt der sogenannte NameNode. Dieser spaltet die Daten in Blöcke auf, verteilt sie auf die Server und speichert die Metadaten. Zum Zwecke der Fehlertoleranz werden identische Blöcke auf mehreren Servern vorgehalten. Außerdem ist der NameNode für die Verwaltung der Metadaten zuständig; er weiß also genau, wo die Datenblöcke liegen und wo Speicherkapazitäten frei sind. HDFS sieht zwei NameNodes für den Fall vor, dass ein System ausfällt.
Der zweite zentrale Bestandteil von Hadoop ist das MapReduce Framework beziehungsweise dessen Weiterentwicklung YARN (Yet Another Resource Negotiator). Es ist für die Verwaltung der Ressourcen und die parallelisierte Anwendungssteuerung zuständig. MapReduce beziehungsweise YARN teilen eine Analyseaufgabe in viele kleinere „Jobs“ auf und verteilen diese inklusive der Daten auf die Server-Knoten.
Bei YARN ist ein „schlanker“ Ressourcen-Manager für die zentrale Verwaltung der Ressourcen zuständig. Hinzu kommt ein ApplicationMaster. Er wird auf den Slave-Knoten im Server-Cluster für die jeweiligen Jobs generiert und steuert das Abarbeiten der betreffenden Teilaufgabe. Am Ende werden die Ergebnisse der Jobs zu einem Ganzen zusammengefügt.
Schnellere Analysen mit In-Memory-Datenbanken
Eine zentrale Anforderung an Big Data ist, dass Analyseergebnisse möglichst schnell, am besten in Echtzeit, zur Verfügung stehen. Daher müssen auch die Daten schnell verfügbar sein. Plattenspeichersysteme und selbst All-Flash-Arrays (AFA) sind in diesem Punkt In-Memory-Datenbanken (IMDB) wie etwa SAP HANA unterlegen. Denn In-Memory-Datenbanken nutzen den Arbeitsspeicher von Server-Systemen, um Daten zu speichern. Nach Erfahrungswerten von Fujitsu erfolgen Datenanalysen bei Einsatz einer IMDB etwa um den Faktor 1.000 bis 10.000 schneller als bei Verwendung konventioneller Datenbanktechniken und Storage-Technologien.
Bei einer In-Memory-Datenbank befindet sich das gesamte Datenvolumen zusammen mit den Datenbankanwendungen im Hauptspeicher eines Servers oder mehrerer Server. Festplatten dienen nur zum Ablegen von regelmäßigen Sicherungskopien und zur Protokollierung von Datenänderungen. Da bei einer In-Memory-Datenbank das Einlesen der Daten von einem relativ langsamen Plattenspeicher entfällt, lassen sich die Informationen extrem schnell speichern, abrufen und sortieren. Die Analyse von Geschäftsdaten ist somit in Echtzeit möglich. Herkömmliche Lösungen, die relationale Datenbanken und Festplattenspeicher nutzen, benötigen dafür unter Umständen mehrere Tage.
Verteilte Parallelverarbeitung und In-Memory im Zusammenspiel
Über die verteilte Parallelverarbeitung können Daten, die aus unterschiedlichen Quellen stammen, vorverarbeitet und in eine für die anstehenden Analyseaufgaben optimale Form gebracht werden. Anschließend erfolgt der Export der Daten in die In-Memory-Datenbank. Die folgenden Analyseschritte erfolgen im Hauptspeicher eines oder mehrerer Server.
Datenbanken für Big Data
Sind die Analysen nicht extrem zeitkritisch, können die vorverarbeiteten Daten auch in herkömmliche SQL-Datenbanken exportiert werden, sofern das Volumen überschaubar bleibt. Für Big-Data-Szenarien mit einem steigenden Volumen an zu exportierenden Daten eignen sich NoSQL-Datenbanken besonders gut. Diese Datenbanken setzen auf keinem festen Schema auf und kommen daher mit jedem Datentyp zurecht. Außerdem erlauben sie es, Datenformate anzupassen, ohne dadurch die Anwendung zu beeinträchtigen.
Vor allem aber können sie auf beliebig viele Server verteilt werden, was dem steigenden Datenvolumen sehr entgegenkommt. Die geläufigste Variante ist die spaltenorientierte NoSQL-Datenbank. Sie kommt vor allem bei der Verarbeitung großer strukturierter Datenmengen zum Zuge, bei denen man mit zeilenorientierten relationalen Datenbanken nicht die gewünschten Antwortzeiten erreicht.
Weitere Varianten von NoSQL-Datenbanken sind Key-Value Stores, dokumentenorientierte Datenbanken (Document Stores) und Graphen-Datenbanken. Im Gegensatz zu relationalen Datenbanken, die universell verwendet werden können, sind NoSQL-Datenbanken auf spezielle Anwendungsfälle zugeschnitten.
Complex Event Processing zur Echtzeitanalyse
Sind im Rahmen von Big-Data-Analysen überwiegend Daten wie Clickstreams oder Sensordaten in Echtzeit zu verarbeiten, ist ein sogenanntes Complex Event Processing (CEP) erforderlich. Dieses ermöglicht die Echtzeitanalyse der Datenströme nach vorab definierten Regeln, welche Bedingungen und Aktionen enthalten. Sind gewisse Bedingungen erfüllt, werden eine oder mehrere damit verknüpfte Aktionen angestoßen.
Typischerweise muss eine CEP-Engine Hunderttausende oder Millionen von Ereignissen pro Sekunde bewältigen. Die Latenzwerte (Zeit zwischen der Entstehung eines Ereignisses und der anzustoßenden Aktion) liegen typischerweise im Bereich von Millisekunden oder manchmal sogar darunter. Um zeitraubende Festplattenzugriffe einzusparen, werden Ereignisströme im Hauptspeicher verarbeitet. Nur Protokolldaten landen auf der Festplatte. Zur Vermeidung von Datenverlusten und um die Last zu verteilen, lassen sich die Daten auf mehrere Server-Knoten replizieren.
Big-Data-Infrastrukturen entstehen nicht von alleine
Die Bereitstellung einer Big-Data-Infrastruktur ist alles andere als einfach. Server- und Speichersysteme, Netzkomponenten und Software müssen ausgewählt, beschafft, kombiniert und getestet werden. Das erfordert Spezialwissen, über das nicht jede IT-Abteilung verfügt. Und selbst wenn das Know-how vorhanden ist, steht dabei immer das Risiko im Raum, dass die Gesamtkonfiguration doch nicht so funktioniert, wie man es erwartet hat.
Lange Projektzeiten, hohe Kosten, Frustration und die Vernachlässigung von anderen wichtigen Aufgaben sind oftmals die Folge. Daher hat Fujitsu für die wesentlichen Techniken, die in einer Big-Data-Infrastruktur eine Rolle spielen, integrierte Systeme bestehend aus Server-, Storage und Netzkomponenten wie auch Software entwickelt. Das Ergebnis sind reduzierte Vorlaufzeiten bis zum Produktiveinsatz, ein minimiertes Projektrisiko und geringere Kosten.
Die integrierten Systeme kommen entweder bereits vorinstalliert aus dem Fujitsu-Werk in Augsburg zum Kunden oder aber Fujitsu stellt sogenannte Referenzarchitekturen zur Verfügung, die flexibel an spezielle Kundenbedürfnisse anpassbar sind. Für die verteilte Parallelverarbeitung bietet Fujitsu zum Beispiel das integrierte System Primeflex for Hadoop an, welches ebenso für den Einsatz von NoSQL-Datenbanken genutzt werden kann.
Zum Einsatz der In-Memory-Datenbank SAP HANA wurde das Integrierte System Primeflex for SAP HANA entwickelt, welches sowohl als Single-Node-Konfiguration wie auch als Multi-Node-Konfiguration angeboten wird.
Wer sich für den Einsatz integrierter Systeme entscheidet, hat somit die Möglichkeit, mit einem sehr überschaubaren Aufwand eine funktionierende Big-Data-Lösung zu bekommen. Gerade für mittelständische Unternehmen ist dieser Weg eine richtungsweisende Alternative zum traditionellen „Do-it-yourself“-Ansatz.
* Gernot Fels ist Head of Integrated Systems, Global Marketing bei Fujitsu
(ID:43522373)
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")