
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Schemafreie SQL-Abfragen für Hadoop und NoSQL Big Data mit Apache Drill
Das Thema Informationsgewinnung und Abfragen in Big-Data-Lösungen ist nicht immer einfach. Unternehmen sollten hier einen Blick auf die Open-Source-Lösung Apache Drill werfen.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
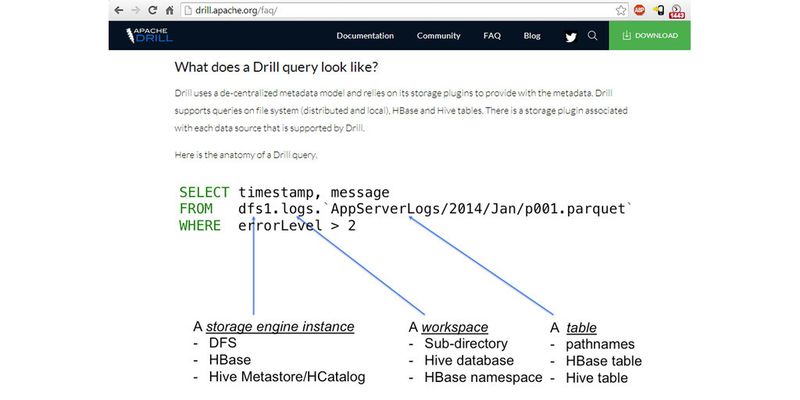
Apache Drill erweitert Hadoop-Umgebungen und NoSQL-Datenbanken um die Möglichkeit, SQL-Abfragen zu erstellen. Grundlage von Drill ist das Google-Produkt Dremel, welches Daten mit hoher Geschwindigkeit aus schemafreien SQL-Datenbanken abfragen kann. Im Fokus der Google-Lösung stehen Echtzeit-Abfragen und Ad-hoc-Berichte in BI- oder Big-Data-Umgebungen.
Drill ist vollständig kompatibel mit ANSI SQL und es sind keine Schemas in den Datenbanken notwendig, was bei NoSQL-Datenbanken die Regel ist. Apache Drill lässt sich parallel zu SQL und BI Tools einsetzen und unterstützt auch JDBC und ODBC.
Das Projekt gehört mittlerweile zu den Top-Level-Projekten von Apache, wird also als weit gehend stabil und fehlerfrei angesehen. Dem Einsatz in produktiven Umgebungen steht nichts entgegen. Drill kann, wie auch Hadoop, auf riesige Datenmengen im Petabyte-Bereich zugreifen, die auf tausende Clusterknoten verteilt vorliegen können. Die Leistung soll dabei nicht einbrechen.
Der bekannte Hadoop-Distributor MapR hat im vergangenen Jahr über 100 Millionen US-Dollar Risikokapital eingesammelt, um die Projekte Hadoop, Spark und Drill enger miteinander zu verzahnen. An der Technologie arbeitet daher nicht nur die sehr aktive Community, sondern auch potente Unternehmen, die sich in diesem Bereich bereits einen Namen gemacht haben. Zu den Geldgebern gehört unter anderem auch Google. MapR will Apache Drill zum Abfrage-Standard für Hadoop machen.
Einstieg in Apache Drill
Apache Drill ist in der Lage, einfache Analysen und Abfragen durchzuführen, kann aber auch in Batch-Prozessen und Pipelines eingebunden werden, wenn es um komplexere Berechnungen geht. Die Abfrage-Sprache wird auch als DrQL bezeichnet. Vorteil der Lösung ist die Unterstützung von SQL-gängigen Abfragen. Das heißt, Entwickler können sich sehr schnell in das Produkt einarbeiten und erhalten schnell zuverlässige Abfragen.
Als Datenspeicher kann Drill direkt an Hadoop angebunden werden und unterstützt in dieser Hinsicht auch das Hadoop File System (HDFS), aber auch HBase wird unterstützt. In Zukunft soll Apache Drill enger mit Apache Spark zusammenarbeiten. Da Spark im Grunde genommen der Nachfolger von MapReduce ist, wird diese Technik in immer mehr Big-Data-Infrastrukturen eingesetzt. Neben NoSQL lassen sich auch andere NoSQL-Datenbanken abfragen, zum Beispiel MongoDB. Drill unterstützt, im Gegensatz zu seinem Quell-Produkt Dremel, dabei sowohl spalten- als auch zeilenbasierte Formate.
Schnellere Datenanalyse
Drill soll vor allem dabei helfen, Abfragen und Informationen schneller zu erhalten als mit Bordmitteln über MapReduce. Zusammen mit Apache Spark kann Drill sogar noch schnellere Informationen liefern. Durch die Möglichkeit, Daten wie Parquet, JSON und HBase-Tabellen nutzen zu können und auch noch Direktabfragen zu bieten, ohne dass Schemas definiert werden müssen, eignet sich das System für schnelle Datenanalysen.
Durch die Zusammenarbeit mit verschiedenen Speichertreibern und SQL-Datenbanken oder BI-Tools eignet sich Drill auch hervorragend als Schnittstelle zwischen herkömmlichen Speichersystemen, Business-Intelligence-Lösungen und Big-Data-Infrastrukturen.
Entwicklungen 2015 – Zugriffskontrolle und mehr Datenquellen
Bereits dieses Jahr wollen die Entwickler noch mehr Datenquellen an Drill anbinden können. Geplant sind die Unterstützung von Cassandra und Solr sowie mehr Möglichkeiten mit JDBC. Auf diesem Weg sollen sich alle Datenbank-Server anbinden lassen, auch MySQL, Oracle, und Microsoft SQL-Server. Außerdem soll die Zugriffskontrolle flexibler gestaltet werden können und die SQL-Abfragen sollen erweitert werden. Die Geschwindigkeit soll gesteigert werden und die Integration in Apache Spark soll weiter vorangetrieben werden. Die Entwickler wollen es ermöglichen, dass Anwender mit Drill direkte Abfragen in Spark durchführen können. Das erlaubt es, dass BI-Tools wie Microstrategy, Spotfire oder Tableau angebunden werden können, ohne weitere Werkzeuge verwenden zu müssen.
Mit verbesserter Zugriffskontrolle sollen Unternehmen den Anwendern im Unternehmen Schnittstellen zu Drill zur Verfügung stellen, die das Zugreifen auf die Daten in der Big-Data-Infrastruktur erleichtert. Das soll Entwickler und Administratoren entlasten. Dazu ist es aber notwendig, dass durch Sicherheitsmechanismen auch festgelegt werden kann, welche Benutzer und Gruppen auf die einzelnen Daten zugreifen dürfen. Erstellen Benutzer zum Beispiel einen virtuellen Datensatz (CREATE VIEW vd AS SELECT) um Informationen mit anderen Benutzern zu teilen, soll sich das besser steuern lassen. Der virtuelle Datensatz wird als SQL-Anweisung über Apache Drill definiert. Auf diesem Weg lassen sich zum Beispiel Daten auslesen, die nur in der letzten Woche gesammelt wurden, oder einige Spalten lassen sich für verschiedene Benutzer maskieren. Die SQL-Abfragen lassen sich als Dateien im Dateisystem speichern. Auf Basis der Zugriffe auf das Dateisystem kann jetzt gesteuert werden, wer die Abfrage nutzen darf.
Eine weitere Möglichkeit ist das Definieren einer virtuellen Datenmenge in der Datenquelle, auf die ein Benutzer Zugriff hat. Der Benutzer darf nur Abfragen für diese Daten erstellen und hat auf andere Daten keinen Zugriff. Dadurch entfallen weitere Berechtigungskonfigurationen, was Administratoren und Entwickler entlastet.
Fazit
Unternehmen, die sich mit Hadoop beschäftigen, kommen kaum um Spark und Drill herum. Auch wenn die beiden Technologien noch nicht im Einsatz sind, sollten sich Entwickler mit den Produkten auseinandersetzen. Da die Datenmengen in Big-Data-Infrastrukturen immer mehr anwachsen, ist die Verzahnung von Anwendungen, welche die Analyse großer Datenmengen beschleunigen, mehr als sinnvoll. Werden die Produkte bereits frühzeitig in das Big-Data-Projekt integriert, profitieren alle davon, das Unternehmen, die Anwender und die Entwickler.
(ID:43206559)
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/34/a2/34a2d02781eaabef906c308dd135c049/0130541481v1.jpeg "KI kann helfen, konsistente Datanbankschemata zu erstellen und weiterzuentwickeln. (Bild: © CreativeIMGIdeas - stock.adobe.com / KI-generiert)")