
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Data-Warehouse-Modernisierung Mit dem Data Lake zu neuen Erkenntnissen
Die Modernisierung vorhandener Data-Warehouse-Lösungen (DWH) bietet diverse Ansatzpunkte, angefangen bei der Architektur über die verwendeten Technologien bis hin zu den zugrundeliegenden Prozessen. Eine Kernkomponente bildet dabei der unternehmensweite Data Lake. Er ermöglicht es, die ganz unterschiedlich strukturierten Big Data nutzbar zu machen und kombiniert auszuwerten. Wie aber lässt sich ein Data Lake homogen in das bestehende Umfeld integrieren? Und welche Rolle nimmt er gegenüber dem etablierten DWH ein?
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
Die IT-Abteilungen stehen vor einem Dilemma: Aufgrund mangelnder Flexibilität und Agilität entwickeln Fachbereiche zunehmend eigene Analyselösungen vorbei am etablierten DWH. Dabei kommen oftmals neue Technologien zum Einsatz, wie etwa Self-Service-Werkzeuge oder Hadoop. In der Folge geht dem Unternehmen nicht nur der sogenannte Single Point of Truth verloren. Vielfältige Potenziale der bereichsübergreifenden Vernetzung bleiben ungenutzt. Und was ganz entscheidend ist: Irgendwann sind die Fachabteilungen mit dem Management ihrer Lösung überfordert. Die IT kann an diesem Punkt kaum mehr unterstützen, da die genutzten Technologien nicht in die vorhandene DWH-Umgebung passen.
Daher ist ein entscheidender Aspekt bei der DWH-Modernisierung die „Zentralisierung“ – sprich: Bestehende Insellösungen aus den einzelnen Fachbereichen werden auf einer Analyseplattform zusammengeführt. Ein Kernelement bildet dabei der unternehmensweite Data Lake. Er fungiert einerseits als Sammelbecken für unterschiedlichste Rohdaten. Andererseits bildet er den Ausgangspunkt für explorative Analysen. Somit erweitert der Data Lake die bestehende Umgebung um jene Fähigkeiten, derer es beim Umgang mit Big Data bedarf, wie etwa die drei „Vs“ – Volume, Variety und Velocity. Daher ist er auch nicht als DWH in neuem Gewand zu betrachten, sondern vielmehr als wichtige Ergänzung.
Der Data Lake ist kein DWH-Ersatz
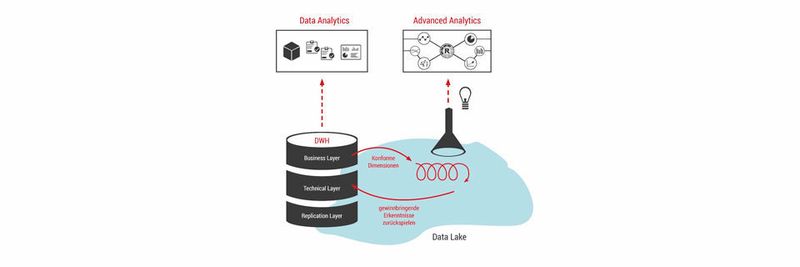
Bei Data Lake und DWH handelt es sich also um zwei Komponenten einer unternehmensweiten Analyse-Plattform, die jeweils unterschiedliche Nutzerbedürfnisse adressieren (siehe Grafik). Das traditionelle DWH legt den Fokus auf eine hohe Prozesseffizienz im Kontext interaktiver Self-Service-Analysen und Berichte, wobei die Informationen relativ passgenau für die Anwender aufbereitet werden. Entsprechend gehen hier strukturierte Daten, beispielsweise aus ERP und CRM, in eine bewährte Schichtenarchitektur aus Replication Layer, Technical Layer und Business Layer ein.
Indes lässt sich die Heterogenität von Big Data über diese Prozesse und Methoden nur schwerlich abbilden. Zwar handelt es sich im Regelfall nicht um gänzlich neue Formate. Schließlich speichern und verarbeiten wir bereits seit Jahren Daten aus E-Mails, Web-Anwendungen, PDFs, Social Media oder Sensoren über das Internet of Things (IoT). Jedoch lassen sich diese Quellen nicht ohne weiteres mit traditionellen Daten mischen und gemeinsam auswerten. Dies ist insbesondere auf den hohen Aufwand bei der Datenintegration zurückzuführen, die einer kurzfristigen und agilen Umsetzung neuer Anforderungen entgegensteht. Zudem lassen sich manche der Daten nur schwer in die klassischen, relationalen Strukturen überführen.
Hier greift das Data-Lake-Konzept: Daten aus ganz unterschiedlich Quellen werden unmittelbar in ihrer Ursprungsform abgelegt. Im Weiteren lassen sich strukturierte wie unstrukturierte Daten schnell und einfach für die Analyse nutzbar machen sowie beliebig verknüpfen. Folglich können Data Scientists und Fachanwender kreativ mit den Daten arbeiten und neue Zusammenhänge jenseits des standardisierten Reportings erschließen. Dieses explorative Vorgehen kommt vor allem dann zum Einsatz, wenn sich der Wert von Datenbeständen im Vorhinein nicht genau einschätzen lässt.
Integration eines Data Lakes
Wie aber ist ein Data Lake sinnvollerweise aufzubauen? Und wie lässt er sich homogen in das bestehende Analyseumfeld integrieren? Herzstück des Data Lakes ist üblicherweise Hadoop. Das Open Source Framework kann beliebige Datenarten in großen Mengen verarbeiten, wobei die Berechnungen auf verschiedene Knoten eines Rechnerverbundes verteilt werden. Infolgedessen können Rohdaten sehr effektiv in ihrer Ursprungsform gespeichert und analysiert werden. Auf dieser technologischen Basis gilt es zunächst einen Bereich einzurichten, in dem die unstrukturierten Daten lediglich gespeichert werden. In diesem Kontext verschafft eine Metadatenschicht den erforderlichen Überblick und hilft bei der Suche nach den gewünschten Quellen. Sie umfasst technische und operative wie auch geschäftsrelevante Information.
Im besten Fall werden die Metadaten bereits bei der Beladung automatisch generiert. Entsprechend der bekannten DWH-Konzepte werden die Daten in identifizierbaren „Eigentümer“-Gruppen oder logischen Zonen organisiert, wie zum Beispiel einer „Raw Data Area“ oder „Staging Area“. Auf diese Weise wird auch eine Data Governance aufgebaut, die verhindert, dass der Data Lake als gigantische Ansammlung unbrauchbarer oder unauffindbarer Daten endet.
Zudem benötigt ein Data Lake eine dezidierte Zone, in der Daten vorstrukturiert abgelegt und somit für spätere Auswertungen verwendet werden können. Beispielsweise greift auch der Data Scientist immer wieder auf Stammdaten und konforme Dimensionen zurück, um diese in seine freien Analysen einzubeziehen und etwaigen Erkenntnissen die notwendige Aussagekraft zu verleihen. In der Abbildung ist der vorstrukturierte Teil durch die Überlappung zwischen Data Lake und DWH dargestellt. Beim Einrichten bieten sich verschiedene Vorgehensweisen an: Zum einen können Stammdaten generell im DWH gespeichert werden. So hat der Data Scientist etwa bei der Analyse von IoT-Sensordaten die Möglichkeit, konkrete Aussagen zu Standorten oder Bezeichnungen der jeweiligen Geräte zu treffen.
Zum anderen lassen sich die Stammdaten im Data Lake ablegen, wobei dieser Bereich als Bestandteil des DWHs definiert ist. Auf diese Weise können die Daten auch größeren Anwender-Gruppen, zum Beispiel im Rahmen des Standard-Reportings, bereitgestellt werden. Innovativ ist an diesem Lösungsansatz, dass ein direkter Zugriff aus dem DWH in den Data Lake – oder umgekehrt – ermöglicht wird. Somit sind die in der Abbildung gezeigten Grenzen nur konzeptionell zu verstehen. Und: Ob die gewonnenen Erkenntnisse über zusätzliche Hive-Modelle oder andere Technologien bereitgestellt werden, ist letztendlich unerheblich.
Welches Vorgehen letztlich zum Einsatz kommt, hängt von unterschiedlichen Faktoren ab. Hierzu zählen unter anderem Fragen der Data Governance: Wer ist Eigentümer der Daten? Welche Engineer-Prozesse liefern die Daten? Wie oft werden die Daten in welchen Auswertungen verwendet? Ebenso spielen aber auch die vorhandenen Technologien eine Rolle. Ein DWH im Data Lake ist per se ausgeschlossen, wenn keine Abfrage-Schnittstelle vorhanden ist, die einen direkten Zugriff ermöglicht. Gleiches gilt, wenn der Entwickler nicht über das erforderliche Big-Data- bzw. Technologie-Know-how verfügt.
Einsatz von Cloud-Technologien
Der aufbereitete Teil des Data Lakes entspricht also im Wesentlichen dem Konzept eines DWHs. Jedoch besteht dadurch die Gefahr, dass die gewonnene Flexibilität und Agilität gleich wieder verloren geht. „On-Premise“-Lösungen lassen sich im Big-Data-Kontext kaum noch effizient realisieren. Die stetig wachsenden Anforderungen führen meist dazu, dass die Systeme immer komplexer und kostenintensiver werden. Ein stabiler Betrieb ist nur durch einen hohen administrativen Aufwand zu gewährleisten. Um dem entgegenzuwirken, bieten sich Cloud-Technologien für die Umsetzung an. Die erforderlichen Ressourcen stehen innerhalb weniger Minuten zur Verfügung. Speicher- und Rechenkapazitäten – bzw. „Storage“ und „Compute“ – können unabhängig voneinander skaliert werden. Nach der Verwendung spezifischer Dienste werden diese einfach wieder abgeschaltet. Der Nutzer bezahlt nur das, was er tatsächlich auch beansprucht hat, was vor allem beim Einsatz von großen Hadoop-Clustern zu erheblichen Kosteneinsparungen führt.
Allerdings sollte der Einsatz von Cloud-Ressourcen einer klar definierten Strategie folgen. Dabei geht es nicht nur darum, Vorgehensweisen und Einsatzgebiete festzulegen. Ebenso ist die Auswahl des Anbieters von Relevanz, um für vertrauliche Unternehmensdaten entsprechend hohe Sicherheitsstandards gewährleisten zu können. Ein etablierter Cloud-Provider wie beispielsweise Microsoft begegnet der Sicherheitsdiskussion mit deutschen Rechenzentren sowie einem Treuhandmodell, bei dem ein Tochterunternehmen der Telekom den Zugriff auf die Daten kontrolliert. Einige Anbieter stellen entsprechende Architekturen auch als „Private Cloud“ zur Verfügung. Infolgedessen können sich Unternehmen eine Cloud im eigenen Rechenzentrum aufbauen. Jedoch gehen die Vorteile hinsichtlich der Skalierung und nutzungsorientierten Kosten zugunsten einer abgeschirmten und isolierte Umgebungen verloren.
Experimente in der Sandbox
Ein wichtiges Einsatzgebiet der Cloud-Dienste bildet das sogenannte Sandboxing. Prinzipiell handelt es sich um eine Methode, mit der Software in einer separaten Umgebung getestet werden kann, ohne laufende Prozesse zu behindern. Im Kontext des Data Lakes bedeutet das: Der Data Scientist erhält für seine Analysetätigkeiten ein autarkes Experimentierfeld. Nach Bedarf kann er ganze Hadoop-Cluster mit beliebig vielen Servern in Anspruch nehmen. Andere Anwender, Programme oder Systeme bleiben von seinen Aktivitäten unberührt. Zudem entsteht der IT keinerlei Aufwand für die Installation, Konfiguration und Wartung der Infrastruktur. Entsprechend ist das Kostenrisiko verhältnismäßig gering, falls aus den explorativen Analysen kein konkreter Nutzen resultieren sollte. Währenddessen gehen gewinnbringende Erkenntnisse in die DWH-Umgebung ein – sprich: Sie werden operationalisiert und in das Standard-Reporting überführt. Hier wird erneut deutlich, dass das Data-Lake-Umfeld durch sauber aufbereitete Stammdaten anzureichern ist, um aus Massendaten überhaupt neue Erkenntnisse ziehen zu können. Um Matching-Problemen vorzubeugen, kommen die qualitätsgesicherten und konformen Dimensionen des DWHs zum Einsatz.
Umgang mit Echtzeitdaten
Im Zuge des Internet of Things zählt auch die Nutzung von Echtzeitdaten zunehmend zu den typischen Anforderungen an eine unternehmensweite Analyseplattform. Dabei werden die eingehenden Datenströme bereits vor der Speicherung mithilfe entsprechender Dienste zu definierten Anwendungsfällen abgefragt. Daraus resultieren unmittelbare Aktionen, wie zum Beispiel Warnmeldungen, automatisierte Prozesse oder eine Darstellung in Echtzeitdashboards. Mitunter sollen auch nur bestimmte Events herausgefiltert werden, da eine voll umfängliche Speicherung nicht lohnenswert erscheint. Das brauchbare Datenmaterial wird indes nach der Echtzeitanalyse konsolidiert und im Data Lake bzw. DWH abgelegt. Als qualitätsgesicherte Stammdaten stehen sie dann wiederrum für die Anreicherung von Echtzeit- oder explorativen Analysen wie auch das Standard-Reporting zur Verfügung.
Fazit
Der Data Lake ist eine entscheidende Komponente im Rahmen der DWH Modernisierung. Er fungiert nicht nur als kostengünstiges Speichermedium für Big Data. Vielmehr eröffnet er die Möglichkeit, strukturierte wie unstrukturierte Daten schnell und einfach für kombinierte Analysen nutzbar zu machen. Insofern kann der Data Lake das etablierte DWH durch viele neue Erkenntnisse bereichern. Allerdings ist er kein adäquater Ersatz. Denn: Ohne konsolidierte Stammdaten stoßen freie Analysen auf Rohdaten schnell an ihre Grenzen. Mithilfe von Cloud-Technologien lässt sich ein Data Lake in kürzester Zeit in das vorhandene DWH-Umfeld integrieren. Ebenso können auf diesem Weg flexibel und preiswert Testumgebungen bzw. Sandboxes für die explorativen Analysen der Data Scientists eingerichtet werden.
Letztlich hat aber auch beim Data Lake bestand, was für Maßnahmen der DWH Modernisierung im Allgemeinen gilt: Die Projekte scheitern in den seltensten Fällen an der Technologie. Ausschlaggebend ist vor allem der Faktor Mensch. Seine Akzeptanz und Aktivität erwecken eine neue Lösung erst zum Leben. Infolgedessen erfordert die Implementierung neuer DWH-Komponenten eine enge Abstimmung mit den Nutzern – und das frühestmöglich im Rahmen der Planung und Entwicklung. Auf diese Weise wird sichergestellt, dass die Technologien den Anwendern tatsächlich den gewünschten Mehrwert bringen. Gleichzeitig sollten diese Vorgehensweisen lediglich Bestandteil eines umfassenden Kulturwandels hin zur datengetriebenen Organisation sein. Dabei sind insbesondere die höheren Managementebenen gefordert, für entsprechende Strukturen, Prozesse und Ressourcen zu sorgen.
* Alexander Thume und Jörg Stephan sind Principal Consultants bei Oraylis
(ID:44936613)
:quality(80)/p7i.vogel.de/wcms/eb/bc/ebbcbb417d292f3d20cb3bf87706705c/0125514392v1.jpeg "Big Data beschreibt die Verarbeitung und Analyse riesiger, vielfältiger Datenmengen mithilfe moderner Technologien wie Lakehouse, generativer KI und Data Mesh, um geschäftlichen Mehrwert zu schaffen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/4c/01/4c0194118da7847890b69dc7032e0c1b/0126827011v1.jpeg "Damit der Data Lake nicht „versumpft“, braucht es ein durchdachtes Governance-Konzept. (Bild: © vladimircaribb - stock.adobe.com)")