
:quality(80)/p7i.vogel.de/wcms/49/c6/49c665060846beb129ae679a2918c61a/0132163773v1.jpeg "Wer trägt die Verantwortung? Echte Datensouveränität bei KI und Cloud bedeutet, die Kontrolle über sensible Daten sicher in der eigenen Hand zu behalten. (Bild: © Lustre - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/6b/7a/6b7a7ae072bb7ab964cde4d302755ceb/0124814981v1.jpeg "Der European Blueprint soll bis Ende 2026 festlegen, welche europäischen Organisationen Zugang zu fortgeschrittenen KI-Modellen erhalten. Verbindliche Pflichten für Anbieter außerhalb der EU entstehen daraus nicht. (Bild: Vergiliy - stock.adobe.com / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/48/a9/48a9cdd76c9b8a649e4c72a65e2b5ba7/0131515572v1.jpeg "Der Autor: Christian Del Monte ist Senior Software Architect bei Adesso SE. Er beschäftigt sich mit Big Data, verteilten Systemen, Apache Spark, Delta Lake und Cloud-nativen Architekturen. (Bild: CHristian Del Monte)")
:quality(80)/p7i.vogel.de/wcms/6b/c3/6bc30ac79b0dc05e39a6f93b228c0e5f/0132228780v1.jpeg "„Souveränität muss ganzheitlich gedacht werden“ – Sven Selle, Senior Director Field Engineering EMEA bei Dataiku. (Bild: Vogel IT-Medien / Dataiku)")
:quality(80)/p7i.vogel.de/wcms/26/81/2681098961a1b8010bbf241f3e914891/0132345254v1.jpeg "Räumlich-zeitliche Identifikatoren sollen fragmentierte Datenbestände systemübergreifend nutzbar machen. Nach Angaben von The Green Bridge ist die Grundlage für KI-Anwendungen und Automatisierung. (Bild: Unsplash-Steve A Johnson)")
:quality(80)/p7i.vogel.de/wcms/e8/05/e805d228897962220779fc3b22bc3acc/0132070606v1.jpeg "Die AI Data Plane bündelt nach Darstellung von Couchbase mehrere Dienste auf einer KI-nativen Datenplattform, darunter MCP-Server, Agent Memory und Agent Catalog. Sie läuft sowohl in der selbst verwalteten Enterprise-Variante als auch im Managed-Service Capella. (Bild: Couchbase)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/d9/db/d9dbfbca0f9ff41469a40d883f8e5cb5/0132438388v1.jpeg "Mit Version 9.5 rückt Denodo die semantische Schicht ins Zentrum der Plattform und positioniert sich im Wettbewerb um die Kontextversorgung von KI-Agenten. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/b8/76/b8761191f739895263a4bdbfcaf9c5b2/0132429694v1.jpeg "Mit dem Wechsel von assistierenden zu ausführenden Agenten verlagert sich der Kontrollbedarf im Produktdatenmanagement. Entscheidend wird die Nachvollziehbarkeit einzelner Attributänderungen. (Bild: Akeneo)")
:quality(80)/p7i.vogel.de/wcms/af/ce/afce59eea1904a99277023c34d4b7c33/0132343197v1.jpeg "Fünf Preview-Releases zwischen Januar und Mai 2026 gingen der Freigabe von Apache Spark 4.2.0 voraus. Die Version steht auch in Databricks Runtime 19 Beta bereit. (Bild: Apache)")
:quality(80)/p7i.vogel.de/wcms/78/9a/789af78a62e28f5e8cc995570d48b822/0130655525v1.jpeg "SupplyX wollte sein Transportmanagement-System ersetzen und fand den Engpass in den Daten. Ein Praxisbericht über die Datenbasis produktiver KI. (Source: © MAGNIFIER - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/9f/fe/9ffe3d484cf6fdc7ea137128b15f60a9/0131577982v1.jpeg "Im Einsatz für den Artenschutz: Ein WWF-Ranger durchstreift den Regenwald. Das geplante Wildlife Protection Operations Center soll solche Einsätze KI- und datenbasiert optimieren. (Bild: Emmanuel Rondeau / WW_US)")
:quality(80)/p7i.vogel.de/wcms/13/bf/13bf56b36e033947b7dbdaf83cc3c4fa/0132104707v1.jpeg "IT-BUSINESS verlost drei Exemplare des Buchs „Data-Driven Marketing und der Erfolgsfaktor Mensch“ von Lutz Klaus. (Bild: Lutz Klaus)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/e9/34/e9342418bd8081921fdd2fc2fc4be51b/0132359705v2.jpeg "Einsatz auf dem Acker: Wie sich humanoide Systeme mit schweren landwirtschaftlichen Maschinen vernetzen lassen, wird in Ilmenau erprobt. (Bild: Fraunhofer IOSB)")
:quality(80)/p7i.vogel.de/wcms/57/b8/57b8da3ba179d80f10073e7541f8b68f/0132491632v1.jpeg "Die Brücke vom Trainings-Cluster über die Simulation bis zum Roboter im Feld hat Lücken: Physical AI scheitert seltener am Modell als am Workflow. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f9/43/f943ca681620e9eb521fea039168a2fe/0132555049v1.jpeg "Die Konferenz T3 – Transform The Tomorrow diskutiert am 1. und 2. Dezember 2026 Strategien, wie Unternehmen sich zukunftssicher aufstellen können. (Bild: © Vogel Corporate Solutions / AdobeStock 1280236166, Oksana)")
:quality(80)/p7i.vogel.de/wcms/95/e5/95e50766b5de0f4b7ca74d1db2524bf2/0132321286v2.jpeg "Humanoide Roboter: Roboter, die vor wenigen Jahren noch eine Vision waren, sind heute dank KI, maschinellem Lernen und Echtzeit-Datenverarbeitung Realität. (Bild: Pete Linforth)")
:quality(80)/p7i.vogel.de/wcms/81/6d/816dfab525864f08b3569676daffb31f/0132240748v2.jpeg "Workflow des Ablaufs einer GitLost-Attacke. (Bild: Noma Security)")
:quality(80)/p7i.vogel.de/wcms/70/85/708551ab7700305b37e0b33bb2b49060/0132135242v1.jpeg "Vertreterinnen und Vertreter der Projektpartner Deutsche Welle, Bauhaus-Universität Weimar und Fraunhofer IDMT sowie des Projektträgers trafen sich in Ilmenau zum Kick-off Meeting von PADSE. (Bild: Fraunhofer IDMT)")
:quality(80)/p7i.vogel.de/wcms/87/4d/874da7c6b2f6b79ad1bf0cdee7d09690/0132101659v1.jpeg "Devin Security Swarm soll Schwachstellen nicht nur aufspüren, sondern ihre Ausnutzbarkeit in einer isolierten Sandbox validieren und Korrekturen als Pull Request bereitstellen. (Bild: Cognition)")
:quality(80)/p7i.vogel.de/wcms/30/19/30192d4799534c8e823986e895916cf4/0131682946v1.jpeg "Der Autor: Stig Martin Fiskå ist Global Head of AI for Good bei Cognizant und Leiter der Cognizant Ocean Business Group (Bild: Cognizant)")
:quality(80)/p7i.vogel.de/wcms/d6/42/d64261f97ff8ea94ab4f7e2f5afb1869/0132187522v1.jpeg "KI-Agenten stimmen Abläufe in Unternehmen zunehmend selbstständig ab – umso wichtiger sind übergeordnete Governance-Regeln und Berechtigungskonzepte, wie sie auch für menschliche Mitarbeitende gelten. (Bild: © Andrea Danti - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Grundlagen Statistik & Algorithmen, Teil 11 Methoden der Linearen Regressionsanalyse
Regressionsanalysen dienen dazu, Prognosen zu erstellen und Abhängigkeiten in Beziehungen aufzudecken. Will ein Smartphone-Hersteller herausfinden, mit welchem Preis er in welchem Kundenkreis welchen Umsatz erzielen kann, so kennt er nur eine Variable – den Preis – aber nicht die anderen Variablen. Heute gibt es eine große Zahl solcher Verfahren, denn sie werden für zahlreiche Zwecke benötigt, etwa in der Epidemiologie.
Anbieter zum Thema
:fill(fff,0)/p7i.vogel.de/companies/68/2d/682dd583dcc4c/fsas-afc-horizontal-2-positive-rgb-nov24.png "fsas-afc-horizontal-2-positive-rgb-nov24 (Fsas)")
:fill(fff,0)/p7i.vogel.de/companies/67/c6/67c6df851ba69/qunis-profilbild.png "qunis-profilbild (QUNIS)")
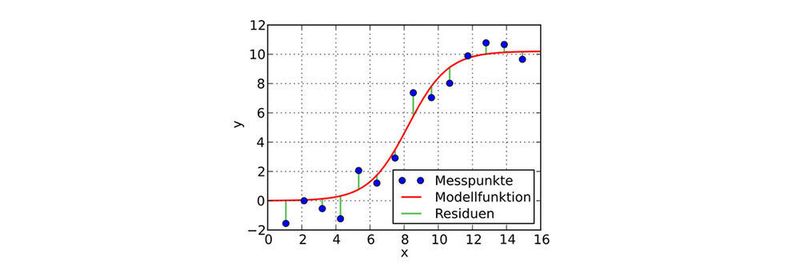
Bei Regressionsanalysen werden Beziehungen zwischen einer abhängigen und mehreren unabhängigen Variablen modelliert. Damit lassen sich Zusammenhänge quantitativ beschreiben oder Werte der abhängigen Variablen vorhersagen.
Eine weitere Anwendung besteht in der für jede moderne Kommunikation essenziellen Trennung zwischen Signal (Funktion) und Rauschen (Fehler) sowie der Abschätzung des dabei gemachten Fehlers, der Störfunktion. Weitere einführende Bemerkungen sind in dem Artikel von BigData-Insider über die Einfache Lineare Regression zu finden.
Multiple lineare Regression
Die multiple lineare Regression wird auch „mehrfache lineare Regression“ (kurz: MLR) oder „lineare Mehrfachregression“ genannt. Sie ist ein regressionsanalytisches Verfahren und ein Spezialfall der linearen Regression. Die MLR versucht, eine beobachtete abhängige Variable durch mehrere unabhängige Variablen zu erklären. Das dazu verwendete Modell ist linear in den Parametern, wobei die abhängige Variable eine Funktion der unabhängigen Variablen ist. Diese Beziehung wird durch eine additive Störgröße überlagert. Die MLR stellt somit eine Verallgemeinerung der ELR bezüglich der Anzahl der Regressoren dar.

Bei der multiplen linearen Regression werden mehrere unabhängige Variablen oder Funktionen der unabhängigen Variablen berücksichtigt. Wird zum Beispiel der Term x hoch 2 zur vorigen Regression hinzugefügt, so ergibt sich: yi = β0 + β1xi + β2xi2 + eii = 1, ..., p. Dabei ist β der unbekannte Parameter. Obwohl der Ausdruck auf der rechten Seite quadratisch in der unabhängigen Variable ist, ist der Ausdruck linear in den Parametern β1, β2 und β3, und . Damit ist dies auch eine lineare Regressionsgleichung. Zur Bestimmung der Modellparameter wird die Methode der kleinsten Quadrate verwendet.
Die wesentliche Voraussetzung an das MLR besteht darin, dass es bis auf die Störgröße ε [Epsilon] das „wahre Modell“ beschreibt. Das zugrundeliegende „wahre Modell“ ist das eigentliche Populationsmodell, welches die Zielgröße und die relevanten Einflussgrößen in Beziehung zueinander setzt. Diese Beziehung wird durch eine additive Störgröße überlagert, für die angenommen wird, dass sie einen Erwartungswert von Null aufweist. Die grundlegende Annahme des Modells ist, dass es linear in den Parametern ist.
 und geschätzter Regressionsgerade (rot) sowie wahrer Störgröße und geschätzter Störgröße (Residuum).")
Im Modell wird in der Regel nicht genau spezifiziert, von welcher Art die Störgröße ε ist; sie kann beispielsweise von zusätzlichen Faktoren oder Messfehlern herrühren. Jedoch nimmt man als Grundvoraussetzung an, dass dessen Erwartungswert (in allen Komponenten) 0 ist (Annahme 1). Diese Annahme bedeutet, dass das Modell grundsätzlich für korrekt gehalten und die beobachtete Abweichung als zufällig angesehen wird oder von vernachlässigbaren äußeren Einflüssen herrührt.
Typisch ist die Annahme, dass die Komponenten des Vektors unkorreliert sind (Annahme 2) und dieselbe Varianz σ2 [kleines Sigma] besitzen (Annahme 3), wodurch sich mithilfe von Verfahren wie der Methode der kleinsten Quadrate (s.o.) einfache Schätzer für die unbekannten Parameter β und σ2 ergeben. Die Methode wird daher auch (multiple lineare) KQ-Regression bzw. KQ-Schätzer genannt. Es ist das Standardverfahren zur mathematischen Ausgleichsrechnung.
Der F-Test
Der globale F-Test, auch Globaltest, Gesamttest, Test auf Gesamtsignifikanz eines Modells, F-Test der Gesamtsignifikanz, Test auf den Gesamtzusammenhang eines Modells genannt, stellt eine globale Prüfung der Regressionsfunktion dar. Mit dem F-Test wird eine Kombination von linearen (Gleichungs-) Hypothesen geprüft und somit, ob mindestens eine Variable einen Erklärungsgehalt für das Modell liefert und das Modell somit als Gesamtes signifikant ist. Falls diese Hypothese verworfen wird, ist das Modell nutzlos. Diese Variante des F-Tests ist die gebräuchlichste Anwendung des F-Tests. Beim Spezialfall der Varianzanalyse kann man Unterschiede zwischen zwei Stichproben aufdecken.
:quality(80)/images.vogel.de/vogelonline/bdb/1430600/1430659/original.jpg "Der monegassische Stadtbezirk Monte-Carlo (© Noppasinw - stock.adobe.com)")
Grundlagen Statistik & Algorithmen, Teil 4
Der Monte-Carlo-Algorithmus und -Simulationen
Der Test geht auf einen der bekanntesten Statistiker, Ronald Aylmer Fisher (1890 bis 1962) zurück. Er formulierte auch den verbreiteten T-Test.
Epidemiologie
In der Erfassung und Bekämpfung von Epidemien sind Stichproben von größter Bedeutung. Das Problem ist die Aufdeckung von Zusammenhängen und von Merkmalen, die signifikant sind. Die Stichproben dürfen daher nicht zu klein ausfallen.
Die Regressionsanalyse wurde schon früh genutzt, um den Zusammenhang zwischen Tabakrauchen und Krankheits- bzw. Sterblichkeitsrate von Rauchern zu erfassen und zu bewerten. Während in den 1920er-Jahren Werbekampagnen gewöhnliche Zigaretten den US-amerikanischen Frauen als „Fackeln der Freiheit“ anpriesen, dachte wohl keiner – zumindest nicht offiziell – dass Rauchen erhebliche Gesundheitsrisiken barg und birgt.
:quality(80)/images.vogel.de/vogelonline/bdb/1409900/1409917/original.jpg "Prinzipbild des Rete-Algorithmus. Deutlich sind zwei Netzwerke (Alpha, Beta) zu erkennen und dass darin jeweils sehr viel Speicher benötigt wird. Dieser hohe Speicherbedarf ist einer der wenigen Nachteile des Rete-Algorithmus. (gemeinfrei)")
Grundlagen Statistik & Algorithmen, Teil 3
Speed für Mustererkennung mit dem Rete-Algorithmus
Doch Beobachtungsstudien, die Regressionsanalyse nutzten, entdeckten den o. g. Zusammenhang. Um zufällige Korrelationen bei der Analyse von Beobachtungsdaten auszuschließen, integrieren Forscher üblicherweise verschiedene Variablen in ihre Regressionsmodelle, zusätzlich zu ihrer primären unabhängigen Variable: das Rauchen etwa. Die abhängige Variable ist Lebensdauer (in Jahren), aber zusätzlich integrieren die Forscher Variablen wie Ausbildungsniveau und Einkommensklasse, also sozioökonomische (und ernährungsmäßige) Faktoren. Diese Störfaktoren wollen sie ausschließen, um so den primären Faktor, das Rauchen, zu determinieren.
:quality(80)/images.vogel.de/vogelonline/bdb/1481900/1481934/original.jpg "Kernel-Maschinen werden verwendet, um nichtlinear trennbare Funktionen zu berechnen, um so eine linear trennbare Funktion höherer Ordnung zu erhalten. (Kernel Machine.svg / Alisneaky, svg version by User:Zirguezi / CC BY-SA 4.0)")
Grundlagen Statistik & Algorithmen, Teil 5
Optimale Clusteranalyse und Segmentierung mit dem k-Means-Algorithmus
Sämtliche Störfaktoren auszuschließen, ist in einer empirischen Untersuchung kaum jemals möglich. Beispielsweise könnte ein hypothetisches Gen die Sterblichkeitsrate beeinflussen oder Leute dazu bringen, mehr zu rauchen. Um solche Störfaktoren aufzuspüren und zu eliminieren, werden häufig zufallsbasierte, kontrollierte Versuchsreihen ausgeführt. Falls es kausale Zusammenhänge gibt, fördern diese Stichproben eher Beweise zutage als Regressionsanalysen von Beobachtungsdaten. Lassen sich jedoch kontrollierte Versuche nicht realisieren, kann man Varianten der MLR wie etwa Instrumentvariablenschätzung nutzen, um kausale Zusammenhänge in Beobachtungsdaten aufzuspüren.
(ID:46549839)
:quality(80)/p7i.vogel.de/wcms/d4/90/d49096fad857f07b788198c34b35e010/0128339234v1.jpeg "Prophet ist ein wertvolles Werkzeug zur Datenanalyse mithilfe von Python und R. (Bild: T. Joos)")
:quality(80)/p7i.vogel.de/wcms/57/f5/57f51fb2030e615747fcfba43835725d/0128237968v1.jpeg "Microsoft Research hat FLAML initiert und auch in Azure zur Verfügung gestellt. (Bild: Microsoft)")