
:quality(80)/p7i.vogel.de/wcms/9d/a9/9da9b4fd060f62036a63dc5ea316f4ef/0131283932v2.jpeg "Chinas bekanntestes KI-Modell von Deepseek will sich von der Nvidia-Abhängigkeit freischwimmen. Die Verantwortlichen haben erste Schritte unternommen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/5b/db/5bdb1266805002fc22dfc91f8464323d/0130876458v1.jpeg "Anwender sind sich der Problematik der Datensouveränität durchaus bewusst, haben aber oft keine durchdachte Lösung. Das ergab eine Studie von Red Hat. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/f9/e0/f9e0b1c5df2c71dac0ed6c4a6a41daa2/0130504390v1.jpeg "Der Autor: Manoj Mehta ist Präsident der EMEA-Region bei Cognizant (Bild: Erik Verheggen Fotografie Amsterdam)")
:quality(80)/p7i.vogel.de/wcms/c2/46/c2467c63f76bb87b95a0325250d912bf/0130876149v1.jpeg "Unternehmen wünschen sich souveräne und nachhaltige Plattformen für den Einsatz geschäftskritischer KI-Anwendungen, ergab eine Snapshot-Umfrage von Yorizon auf dem CloudFest 2026. (Bild: frei lizenziert Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/a4/78/a47816b2769482be79087b034dc8c278/0131037378v1.jpeg "Der Autor: Christian Hörl ist Gründer und Geschäftsführer von ScanProfi, einem Scandienstleister mit Fokus auf Geschäftskunden aus Industrie, Immobilienwirtschaft und dem öffentlichen Sektor. (Bild: ScanProfi)")
:quality(80)/p7i.vogel.de/wcms/6c/6f/6c6ff600e6a9ee58d83097e10fc2d95d/0130967409v1.jpeg "Der Autor: Lukas Diener ist Principal Consultant Data & Analytics Strategy, Data Culture, Data Governance und Domain Lead Strategy bei der QUNIS GmbH. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/4c/f7/4cf7fbdfeaf0aa72b869b5a7ba574b0d/0131526647v1.jpeg "Erforschen Chinas Datengeschichte: Projektleiter Dr. Chun Xu (l.) und Co-Projektleiterin Sijia Cheng. (Bild: Privat)")
:quality(80)/p7i.vogel.de/wcms/38/4a/384aff5eaf930e6ad32fc39b7b0f4d65/0131489904v1.jpeg "CEO Jay Kreps eröffnete die Current-2026-Konferenz mit seiner Präsentation. (Bild: Matzer)")
:quality(80)/p7i.vogel.de/wcms/67/f4/67f4caf2784adc0137eb21fef766eeba/0130652634v1.jpeg "Der Autor: Thomas Steur ist CTO von Matomo, einer global agierenden Open-Source-Analytics-Plattform mit Fokus auf Datenschutz, Compliance, Kontrolle und europäische Datensouveränität. (Bild: Matomo)")
:quality(80)/p7i.vogel.de/wcms/a1/d4/a1d467fc1fddf5b25594e49d9714f7c3/0130597934v1.jpeg "Der Autor: Oliver Bastert ist CTO bei Gurobi (Bild: Gurobi)")
:quality(80)/p7i.vogel.de/wcms/8e/70/8e7083abba5bdaa5b5ab6972670ec5fd/0130190257v1.jpeg "Sudhir Hasbe, Präsident sowie Technology und Chief Product Officer bei Neo4j, erklärte, warum Graph-Technologien für bessere KI-Analysen eine sinnvolle Ergänzung der KI-Verarbeitungskette sind. (Bild: Rüdiger)")
:quality(80)/p7i.vogel.de/wcms/28/95/289560ddeb2ca55c1e003d57d331063c/0130126830v1.jpeg "Diese Folie zeigt, woraus RisingWave besteht. (Bild: RisingWave)")
:quality(80)/p7i.vogel.de/wcms/08/11/0811bf36e0514d6fa324acee19211443/0131691136v2.jpeg "Der SAS-Hackathon-Champion entwickelte ein Früherkennungssystem für Alzheimer. (Bild: © SAS)")
:quality(80)/p7i.vogel.de/wcms/35/aa/35aa7935774f380a96e1e3de73c09661/0129631002v1.jpeg "Einfaches Beispiel für die Chain-of-Thoughts-Prompting-Technik (Bild: IBM)")
:quality(80)/p7i.vogel.de/wcms/58/7a/587af12cf063f30f9f1dd8d09a8028ec/0129948269v1.jpeg "Die Autorin: Nina Herten ist Projektmanagerin für Digitales und Organisationsprozesse bei der LEVACO Chemicals GmbH (Bild: TobiasVollmer.de Mobil: +49 179 7796391)")
:quality(80)/p7i.vogel.de/wcms/37/af/37af6545336ac8aac53cccaf675c22d5/0116632947v1.jpeg "Der Autor: Steffen Vierkorn ist Geschäftsführer der QUNIS GmbH. Neben seiner Tätigkeit bei QUNIS lehrt er an der TU München und der TH Rosenheim. Zudem ist er Member ausgewählter Data Councils und Steerings großer Konzerne und weltweit tätiger Unternehmen. (Bild: QUNIS GmbH)")
:quality(80)/p7i.vogel.de/wcms/9e/1e/9e1e91da75c4ce4f88ac9b573c7dedaf/0131756867v1.jpeg "Bosch verliert im normalen Geschäft bekanntlich immens an Boden. Das soll sich nun ändern, indem man sich in Richtung künstlicher Intelligenz und humanoider Robotik stärker engagiert ... (Bild: Bosch)")
:quality(80)/p7i.vogel.de/wcms/6a/f0/6af08c0cda2db9768f3a3dc0543ea2a8/0131598813v2.jpeg "Teil des Benchmark-Tests: Durch Bewegungen mit verschiedenen Laufwegen auf einer Rampe wird die Fähigkeit zur Selbststabilisierung untersucht. (Bild: Fraunhofer IPA/ Rainer Bez)")
:quality(80)/p7i.vogel.de/wcms/69/55/69552afaceb34108ef291de9ef8e8244/0131579532v2.jpeg "Industriedisplay: mit Carrier Board und aufgestecktem Arduino UNO Q (Bild: Codico)")
:quality(80)/p7i.vogel.de/wcms/60/14/60144159bc4b7ebcd8b0e070919f8058/0131558268v2.jpeg "Transformation im Engineering: KI-gestützte Systeme generieren zunehmend selbstständig Schaltschranklayouts und entlasten Konstrukteure von zeitraubenden Routineaufgaben. (Bild: WSCAD)")
:quality(80)/p7i.vogel.de/wcms/12/d4/12d47f6b15c0c27c0130e07c1f31add0/0131669958v1.jpeg "Unkontrollierte API-Schlüssel für KI-Agenten werden zur wachsenden Angriffsfläche. Mit dem EU AI Act wird der Kontrollverlust zum regulatorischen Risiko für Unternehmen. (Bild: Dall-E / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/f5/f4/f5f42dd3f713a7e04b362e82feb7554c/0130676518v1.jpeg "Der Autor: Ismael Valenzuela ist Vice President Labs, Threat Research & Intelligence bei Arctic Wolf (Bild: Arctic Wolf)")
:quality(80)/p7i.vogel.de/wcms/bb/26/bb2627e105d7880a62718c6af900f7b7/0131230458v1.jpeg "Dr. Juliana Kliesch, Counsel bei Bird & Bird, betont, dass sich Unternehmen schon vor einem finalen Gesetzestext auf strengere EU-Vorgaben zu Personalisierung und Dark Patterns vorbereiten sollten. (Bild: Bird & Bird)")
:quality(80)/p7i.vogel.de/wcms/94/27/942709ac64ee0b1480a9eca920eed2e3/0130430184v1.jpeg "Verwaiste Service‑Accounts und überprivilegierte nicht‑menschliche Identitäten, kompromittierte oder anfällige Drittanbieter‑Pakete, nicht rotierte Secrets sowie ungeschützte Modelle, Daten‑Buckets und Endpunkte sind Tenable zufolge aktuelle Risiken für Cloud und AI. (Bild: BillionPhotos.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/64/f7/64f78dbc018f6ceb8b1c61d741f29f83/0131799992v1.jpeg "Anthropic muss den Zugang zu seinem KI-Modell blockieren, da die US-Regierung ein Sicherheitsrisiko befürchtet. (Bild: Gemini / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/19/5e/195e562ee64b2ecde1362513ff4d164e/0131152652v1.jpeg "Der Autor: Prof. Dr. Andreas Walter, LL.M., ist Partner (Co-Managing Partner) und Leiter der Praxisgruppe Banking & Finance bei Schalast Law | Tax (Bild: ©2023 Katja Kuhl)")
:quality(80)/p7i.vogel.de/wcms/eb/14/eb14dc94cb19af3163180d60d1355283/0131851376v1.jpeg "Der Autor: Maximilian Harms ist Senior Director Business Transformation bei Dataiku (Bild: Dataiku)")
:quality(80)/p7i.vogel.de/wcms/99/ba/99ba69a8921df4be68d3e4a900c863cb/0130092667v1.jpeg "Artificial Superintelligence (ASI) bezeichnet eine hypothetische Form von KI, deren Fähigkeiten die menschliche Intelligenz in nahezu allen Bereichen übertreffen würden. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/d5/59/d5597bab8d5d2a99d6655c93a99ef357/0129935720v1.jpeg "Artificial General Intelligence bezeichnet eine hypothetische KI mit universellen kognitiven Fähigkeiten, die Wissen flexibel auf unterschiedliche Aufgaben übertragen kann. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/68/f8/68f8b9869e1288dfa2eeff3a1dc6a7eb/0127838110v1.jpeg "Nicht jedes Modell muss groß sein, um große Wirkung zu erzielen: Small Language Models (SLMs) arbeiten mit deutlich weniger Parametern als ihre großskaligen Gegenstücke, liefern aber in klar umrissenen Aufgabenfeldern vergleichbare Ergebnisse. (Bild: Midjourney / KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/74/05/74053661b14a2f12ec5e98ebd1469197/0127788138v1.jpeg "Ein neuronales Netz als Sprachdenker: Large Language Models verarbeiten Milliarden von Wörtern, um Sprache zu verstehen, zu strukturieren und neu zu erzeugen. (Bild: KI-generiert)")
:quality(80)/p7i.vogel.de/wcms/c9/1a/c91ad9dfc806cc7df9fe7074ca5e64dd/0127064676v1.jpeg "Das sind die Gewinner der IT-Awards 2025! (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/43/e4/43e42f37cc71f12e6ae46717e700644e/0126701619v1.jpeg "Wer sind die Gewinner unserer großen Leserwahl? CloudComputing-Insider verleiht heute die IT-Awards 2025 in sechs Kategorien. (Bild: Vogel IT-Medien GmbH)")
:quality(80)/p7i.vogel.de/wcms/82/9a/829ab32db929fbae572a7c8290463a08/0121295821v1.jpeg "Die Gewinner der BigData-Insider Readers' Choice Awards 2024 (Bild: Manuel Emme Fotografie)")
Praxistipp Big Data Performance Tuning So holen Sie mehr aus Ihrem Hadoop Cluster raus
Das Performance Tuning eines Hadoop Clusters ist eine komplexe Aufgabe und will gut vorbereitet sein. Zum Glück stehen dem Kundigen mit einer Hadoop-Distribution eine Reihe von Monitoring- und Benchmarking-Tools zur Verfügung. Eine Reihe von Parametern, die die Leistung beeinflussen, lässt sich damit feintunen.
Anbieter zum Thema
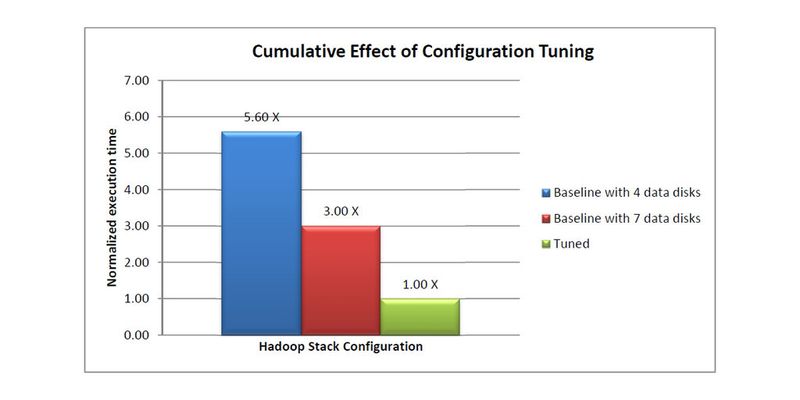
Für das Tuning der Hadoop Performance sind Fachkenntnisse empfehlenswert, die sich auf das Betriebssystem Linux, den entsprechenden Hypervisor, die Java VM (JVM), das Netzwerk und die Hardware erstrecken sollten. Kurzum: auf den gesamten Hadoop- und Non-Hadoop-Technologiestapel. Im folgenden, sehr knappen Überblick wird vorausgesetzt, dass sich alle diese Komponenten im aktuellsten Zustand befinden, insbesondere die Software.

Um aber das Betriebssystem auf die Handhabung eines Hadoop Clusters vorzubereiten, sind kleine Anpassungen nötig. So soll vermieden werden, dass dem System die Puste ausgeht, nur weil ein paar Limits zu eng gesetzt sind. Die voreingestellte Anzahl offener File Descriptors (FD) wird mit dem Befehl ulimit so konfiguriert, dass dieser Wert auf 32768 oder einen ähnlich hohen Wert gesetzt wird, je nach Clustergröße. Zudem sollte im Linux-Kernel der Wert net.core.somaxconn nicht auf dem Default-Wert von 128 bleiben, sondern wesentlich höher liegen, beispielsweise 1024.
Benchmarks
Das Hadoop Framework weist über 150 konfigurierbare Parameter auf, die die Leistung beeinflussen. Hinzukommen in den Zusatzschichten des Hadoop-Stapels ähnlich viele Parameter. Folglich muss sich eine Beschreibung der wichtigsten Vorgaben auf die praktischsten und effektivsten Parameter beschränken.
Wie effektiv das Tuning ist, muss sich mit dem richtigen Benchmarktest und den geeigneten Monitoring- und Tuning-Tools überwachen und einstellen lassen. Einer der gängigsten in Hadoop mitgelieferten Benchmarks ist TeraSort, der einfach ein Terabyte an Daten mit MapReduce sortiert.
TeraSort ist beliebt, weil er gleichermaßen Prozessor, Memory, die Disks und das Netzwerk belastet, sodass er als zuverlässiger Indikator für die Leistung des Gesamtsystems herangezogen werden kann. „Tuning ist immer Workload-abhängig“, ergänzt Wilfried Hoge. „Eine für TeraSort getunte Hadoop-Umgebung muss nicht optimal für die Kunden-Workloads sein.“
Weitere Benchmark-Tests
- Der STREAM Benchmark wird verwendet, um die Leistung des Memory-Subsystems und des NUMA-Verhaltens der Hardware festzustellen.
- Der IOzone File System Benchmark kann helfen, die Baseline Performance des IO-Subsystems festzustellen.
- Netperf lässt sich verwenden, um die Netzwerk-Infrastruktur einem Belastungstest zu unterziehen und ihre Baseline-Performance festzustellen.
- Hadoop bringt selbst Mikro-Benchmarktests wie etwa DFSIO, NNBench und MRBench mit. Sie lassen sich verwenden, um den Aufbau des Hadoop-Frameworks zu prüfen.
- Benchmarks wie etwa SPECcpu, SPECjbb und SPECjvm können ebenfalls hilfreich sein.
Hoge verweist auf die Systemanforderungen und Best Practices der Distributoren: „Sie geben ebenfalls wichtige Hinweise für die Einstellung von Parametern.“
Stell- und Kenngrößen
Es kann vorkommen, dass MapReduce-Aufgaben den Fortschritt von Hadoop-Workloads nicht „rechtzeitig“ anzeigen. Rechtzeitig bedeutet hier einen Zeitpunkt, der innerhalb des Default-Zeitlimits von 600 Sekunden liegt. Das ist der mapred.task.timeout, der in der Datei mapred-site.xml festgelegt wird. Je nach Workload sollte dieser Wert erhöht werden, ohne jedoch ein vernünftiges Maß zu überschreiten.
Sollten Exceptions wie java.net.SocketTimeoutException auftauchen, die besagen, dass ein „Timeout während des Wartens auf Bereitschaft des Channels für Lesen/Schreiben“ eintritt, dann sollten in der Datei hdfs-site.xml die Werte dfs.socket.timeout und dfs.datanode.socket.write.timeout erhöht werden, bis sie ein akzeptables Niveau erreicht haben.
(ID:43105672)
:quality(80)/p7i.vogel.de/wcms/b2/ab/b2ab0519c30fef6be3a3835be38c871a/0127078143v1.jpeg "GPT-OSS-120b und GPT-OSS-20b lassen sich auch als gehostete LLMs nutzen. (Bild: T. Joos)")
:quality(80)/p7i.vogel.de/wcms/c5/c9/c5c95857220a9e95200e10d5a4eb7db9/0125244377v1.jpeg "AWS lud zum Summit dieses Jahr auf das Hamburger Messegelände ein. (Bild: © Hamburg Messe und Congress/Jürgen Nerger)")